
01번째 게시물
첫 게시물입니다. 안녕하세요. 데이터 분석에 관심이 많은 기계공학과 데린이 입니다.
학부시절 실험하면서 데이터들을 처음 접했는데, 그 이후 데이터 분석이라는 분야에 흥미가 생겨서 재밌는 내용이나 파이썬 및 딥러닝 위주로 공부했던 내용 게시글 올릴 생각입니다!
혼자 보고 지나가면 까먹기도하고 뭔가 흔적을 남겨야 봤던 기억이 날것 같네요!
봐주셔서 감사합니다!
Mushroom Classification
데이터 : https://www.kaggle.com/datasets/uciml/mushroom-classification
데이터는 엑셀데이터로써 먹을 수 있는 버섯과 독버섯을 구별해야되는 과제입니다.
0) 필요한 패키지 모듈 가져오기
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torchinfo import summary
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split1) 데이터 확인
if __name__ == "__main__":
data = pd.read_csv(
"./kaggle_data/mushroom/mushrooms.csv"
)
print(data.head(5))
print(data.columns)
train_data = data.drop(["class"], axis=1)
label = data.loc[:, "class"]
nan1 = train_data.isnull().sum()
nan2 = label.isnull().sum()
print(nan1)
print(nan2)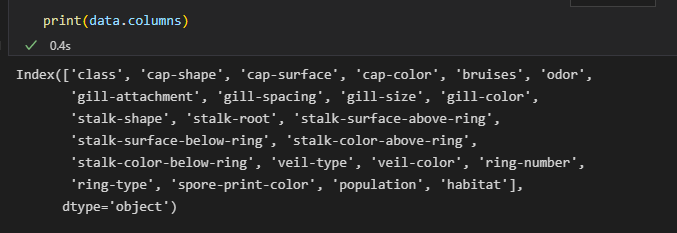
칼럼이 많네요 feature 값으로 버섯모양, 표면, 색깔, 등등이 있는 것 같습니다.
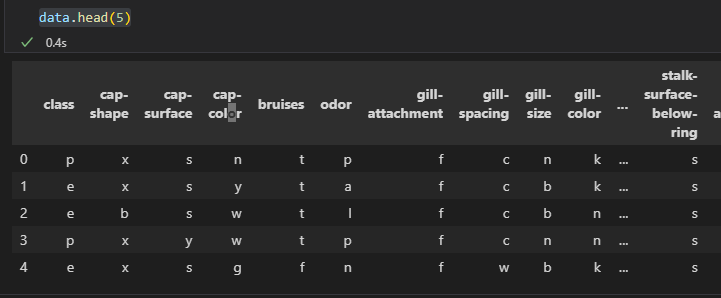
pandas로 이미지 데이터를 불러오고 head로 간략하게 데이터를 확인합니다.
보아하니 class p가 posion(독버섯)이고 e가 edible(식용)버섯으로 라벨이군요
바로 train_data랑 label로 분리 시켜 줍니다.
이후에 Nan 값이 존재 하는지 확인합니다.
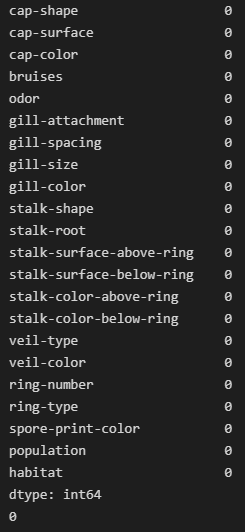
Nan 값이 없네요 아주 행복한 데이터 입니다.
2) 데이터 원핫-인코딩, Train,Valid,Test 셋 분리
train = pd.get_dummies(train_data)
train_class_num = len(train.columns)
## 라벨 class 균형 확인 : edible(4208), poison(3916)
class_count = label.value_counts()
# 라벨 원핫인코딩
label = pd.get_dummies(label)
label_class_num = len(label.columns)
## train, valid, test 데이터 분리 : train:4874, valid:1625, test:1625(stratify = label로 설정)
x_train, x_valid, y_train, y_valid = train_test_split(
train, label, test_size=0.4, shuffle=True, stratify=label, random_state=777
)
x_valid, x_test, y_valid, y_test = train_test_split(
x_valid,
y_valid,
test_size=0.5,
shuffle=True,
stratify=y_valid,
random_state=777,
)라벨로 식용, 독버섯 균형이 나쁘지 않네요 클래스가 2개뿐이니 시각화하지 않고 양만 파악하겠습니다.
Feature 값이 전부 str 타입이네요 딥러닝은 숫자 밖에 못알아먹으니 one-hot-encoding으로 Feature 값들을 변환 해줍니다.
이후에 사랑스러운 sklearn의 train_test_split을 두번해서 먼저 train, valid를 구분하고 구분된 valid를 valid, test로 다시 분리합니다.
3) 딥러닝을 위한 Dataset Batch, Dataloader 설정
# dataset class
class dataset(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __len__(self):
return len(self.y)
def __getitem__(self, index):
single_x = self.x.iloc[index]
single_y = self.y.iloc[index]
single_x = torch.tensor(
single_x, dtype=torch.float32
) # covert dataframe to Tensor
single_y = torch.tensor(single_y, dtype=torch.float32)
return single_x, single_y
def normalization(self):
pass
train_data = dataset(x_train, y_train)
valid_data = dataset(x_valid, y_valid)
test_data = dataset(x_test, y_test)
train_batch_size = 32
train_dataloader = DataLoader(train_data, batch_size=train_batch_size,shuffle=True)
valid_dataloader = DataLoader(valid_data, batch_size=train_batch_size)
test_dataloader = DataLoader(test_data, batch_size=1)
Network = network(input_channel=train_class_num, output_channel=label_class_num)딥러닝 커스터마이징 데이터셋을 구성하기 위해 class : dataset을 선언합니다. 클래스 메소드 get__item 에서 데이터셋이 데이터프레임이니 iloc로 한개씩 가져오고 데이터 타입이 전부 str에서 one-hot-encoding했으니 0 아니면 1이기 때문에 텐서로 변환만 해주고 따로 normalization이나 전처리는 안해도 되겠네요
이후에 train 배치 사이즈를 지정하고 valid, test는 디폴트로 1로 주고 Network가 batch만큼
잘 퍼가도록 train, valid, test DataLoader객체를 생성합니다.
4) Network 설정
class network(nn.Module):
def __init__(self, input_channel, output_channel):
super().__init__()
self.input_channel = input_channel
self.output_channel = output_channel
self.ln1 = nn.Linear(in_features=input_channel, out_features=input_channel * 2)
self.ln2 = nn.Linear(
in_features=input_channel * 2, out_features=input_channel * 4
)
self.ln3 = nn.Linear(
in_features=input_channel * 4, out_features=input_channel * 8
)
self.ln4 = nn.Linear(
in_features=input_channel * 8, out_features=input_channel * 4
)
self.ln5 = nn.Linear(
in_features=input_channel * 4, out_features=input_channel * 2
)
self.ln6 = nn.Linear(in_features=input_channel * 2, out_features=input_channel)
self.ln7 = nn.Linear(in_features=input_channel, out_features=output_channel)
def forward(self, x):
output = F.relu(self.ln1(x))
output = F.relu(self.ln2(output))
output = F.relu(self.ln3(output))
output = F.relu(self.ln4(output))
output = F.relu(self.ln5(output))
output = F.relu(self.ln6(output))
output = torch.sigmoid(
self.ln7(output)
) # 이진분류, loss함수로 BCE를 사용했기 때문에 출력층에 SIGMOID 적용
Network = network(input_channel=train_class_num, output_channel=label_class_num)
summary_model = summary(Network)
print(f"### model is ready!!!###\n\n{Network}")
가장 중요한 Network설정입니다. 위의 데이터가 label균형도 잘 맞고 이상치도 딱히 없으니 간단하게 MLP쌓아서 Network를 생성합니다. 주의할 점은 이제 label이 두개뿐이기 때문에 이진분류 이므로 마지막 함수에서 Simgoid함수로 최종 결과 값이 0 or 1로 도출되도록 마지막에 활성화함수를 설정해줍니다.
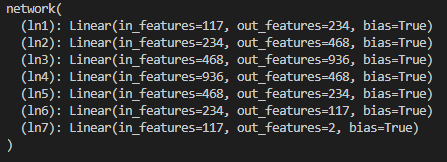
5) 학습 실시
lr = 0.00001
step_size = 30
gamma = 0.1
total_epoch = 30
save_path = "./model/mushroom_epoch30.pt"
## device설정 : Gpu가 없어서 cpu로 진행 ㅠㅠ
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(f"\n### The device is --{device}-- that we use ###")
Network = Network.to(device)
test_signal = input(str("Do you want to train ? (y or n) : "))
if test_signal == "y":
# 옵티마이저, 스케쥴러, 손실함수(이진분류라서 binary선택) 선택
optimizer = optim.Adam(Network.parameters(), lr=lr)
scheduler = optim.lr_scheduler.StepLR(
optimizer=optimizer, step_size=step_size, gamma=gamma
)
criterion = nn.BCELoss()
total_loss = {"val": [], "train": []}
for epoch in range(total_epoch):
Network.train()
epoch_train_loss = 0.0
for i, data in enumerate(train_dataloader,0):
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 초기화
outputs = Network(inputs)
loss = criterion(outputs, labels)
batch_train_loss = loss.item() # loss만 가져오기
loss.backward() # 역전파 기록 저장
optimizer.step() # 업데이트
epoch_train_loss += batch_train_loss
avg_train_loss = epoch_train_loss / len(train_dataloader)
Network.eval()
val_epoch_loss = 0.0
for i, data in enumerate(valid_dataloader, 0):
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = Network(inputs)
loss = criterion(outputs, labels)
val_batch_loss = loss.item()
val_epoch_loss += val_batch_loss
avg_val_loss = val_epoch_loss / len(valid_dataloader)
total_loss["train"].append(avg_train_loss)
total_loss["val"].append(avg_val_loss)
print(
f"epoch : {epoch} The train loss is {avg_train_loss}, valid loss is {avg_val_loss}"
)
scheduler.step()
x = np.arange(1, total_epoch + 1)
plt.plot(x, total_loss["train"], "r", label="train")
plt.plot(x, total_loss["val"], "b", label="val")
plt.legend()
plt.title("Mushroom Deeplearning")
plt.yscale("logit")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
torch.save(Network.state_dict(),save_path)1) parameter 지정
코드가 쪼매 기네요 차근차근 말하면 우선 학습에 필요한 learningrate, 스텝러닝레이트 스케쥴러를 사용할거기 때문에(step=30마다 gamma값만큼 곱해져서 lr줄어듦) step_size, gamma 설정하고 몇번 학습할건지 설정합니다.
후에 device를 설정합니다. gpu달려있으면(cuda, cudnn설정) 없으면 cpu로 연산 진행
2) 딥러닝에 필요한 옵티마이저, 스케쥴러, 손실함수 설정
train 할거면 input으로 y로 신호를 줍니다. y로 입력이 있으면 옵티마이저(아담), 스케쥴러(스텝 스케쥴러), 이진분류이기 때문에 손실함수(BCE)를 설정합니다.
3) 학습(Train), 검증(Validation) 실시
인스턴스 Network를 train으로 설정한 뒤 Optimzer를 초기화 하고 train_dataloader로 데이터를 batch 만큼 Network에 입력시킵니다. 그 뒤 output 값(0아니면 1이겠죵 sigmoid이니) 값과 실제 값을 설정한 loss 함수로 loss를 계산한뒤 backward로 미분합니다. 후에 저장된 gradient값을 optimizer로 업데이트 하고 loss를 loss저장 딕셔너리에 저장합니다. 이러면 one epoch train이 마무리 되네요
후에 validation을 진행하는데 일단 network를 eval모드로 설정합니다. 사실 MLP라서 상관없을 것 같긴한데 일단 진행하고 검증에선 가중치를 업데이트할 필요가 없으니 with_no_grad로 자동 gradient추적을 멈춥니다. 그리고 input 데이터를 valid batch=1 만큼 Network에 결과를 도출한뒤 똑같이 loss를 계산하고 loss저장 딕셔너리에 저장합니다. 이렇게 하면 one epoth validation이 끝!
4) 결과 시각화(loss)
이제 epoch마다 위 과정을 반복하면서 매 epoch_loss값들을 저장한뒤 시각화 할게요
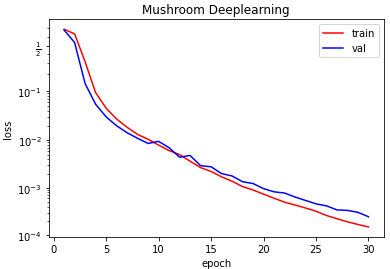
아주 loss 값이 0으로 수렴하면서 작게 잘나오는 군요 또한 val_loss가 증가하지 않는 걸 보아 과적합도 아닌듯 합니다.
5) 모델 저장
결과가 잘나왔으니 torch.save를 통해 모델을 저장합니다.
6) 테스트 실시
elif test_signal == "n":
Network = network(input_channel=train_class_num,output_channel=label_class_num)
Network.load_state_dict(torch.load(save_path))
Network.eval()
result = []
for i, data in enumerate(test_dataloader):
inputs, labels = data
with torch.no_grad():
outputs = Network(inputs)
percent, predicted = torch.max(outputs.data, 1)
if predicted == 0:
if labels[0][0] == 1:
result.append(True)
elif labels[0][1] == 1:
result.append(False)
elif predicted == 1:
if labels[0][0] == 1:
result.append(False)
elif labels[0][1] == 1:
result.append(True)
ok = result.count(True)
ng = result.count(False)
accuracy = ok / (ok + ng) * 100
print(f"model result ok : {ok}, ng : {ng} accuracy is {accuracy}")
train signal을 n으로 줘서 test만 한다고 설정했을 때 실행 되는 구문입니다. 이미 train을 했으니 모델만 사용하면 되니 n을 주면 되죠
우선 train Network와 동일한 Structure를 구성하기 위해 같은 instantce를 생성한 뒤 저장한 모델(weight)들을 뒤집어 씌웁니다.
validation과 유사하게 Network를 eval모드로 바꾸고 input을 test 데이터들을 Dataloader로 Network에 입력시켜 test를 실시합니다.후에 predicted 값들과 실제 라벨값들을 비교해서 예측을 얼마나 잘했는지 accuracy를 측정합니다.
결과를 확인하면

데이터가 좋으니 1625개 전부 잘 예측했군요.
아주 좋은 정형데이터 classification에 대해 코드를 짜봤습니다.
전체코드
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torchinfo import summary
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
# dataset class
class dataset(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __len__(self):
return len(self.y)
def __getitem__(self, index):
single_x = self.x.iloc[index]
single_y = self.y.iloc[index]
single_x = torch.tensor(
single_x, dtype=torch.float32
) # covert dataframe to Tensor
single_y = torch.tensor(single_y, dtype=torch.float32)
return single_x, single_y
def normalization(self):
pass
class network(nn.Module):
def __init__(self, input_channel, output_channel):
super().__init__()
self.input_channel = input_channel
self.output_channel = output_channel
self.ln1 = nn.Linear(in_features=input_channel, out_features=input_channel * 2)
self.ln2 = nn.Linear(
in_features=input_channel * 2, out_features=input_channel * 4
)
self.ln3 = nn.Linear(
in_features=input_channel * 4, out_features=input_channel * 8
)
self.ln4 = nn.Linear(
in_features=input_channel * 8, out_features=input_channel * 4
)
self.ln5 = nn.Linear(
in_features=input_channel * 4, out_features=input_channel * 2
)
self.ln6 = nn.Linear(in_features=input_channel * 2, out_features=input_channel)
self.ln7 = nn.Linear(in_features=input_channel, out_features=output_channel)
def forward(self, x):
output = F.relu(self.ln1(x))
output = F.relu(self.ln2(output))
output = F.relu(self.ln3(output))
output = F.relu(self.ln4(output))
output = F.relu(self.ln5(output))
output = F.relu(self.ln6(output))
output = torch.sigmoid(
self.ln7(output)
) # 이진분류, loss함수로 BCE를 사용했기 때문에 출력층에 SIGMOID 적용
return output
if __name__ == "__main__":
## devide label and train_data
data = pd.read_csv(
"C:/Users/PC_1M/Desktop/코딩/kaggle/mushroom/mushrooms.csv"
)
# 피쳐,라벨 분리
train_data = data.drop(["class"], axis=1)
label = data.loc[:, "class"]
## 결측치, 결손값 확인 --> 각 column null이 존재 하지 않음
nan1 = train_data.isnull().sum()
nan2 = label.isnull().sum()
# 피쳐 원핫인코딩 실시, 피처개수 반환
train = pd.get_dummies(train_data)
train_class_num = len(train.columns)
## 라벨 class 균형 확인 : edible(4208), poison(3916)
class_count = label.value_counts()
# 라벨 원핫인코딩
label = pd.get_dummies(label)
label_class_num = len(label.columns)
## train, valid, test 데이터 분리 : train:4874, valid:1625, test:1625(stratify = label로 설정)
x_train, x_valid, y_train, y_valid = train_test_split(
train, label, test_size=0.4, shuffle=True, stratify=label, random_state=777
)
x_valid, x_test, y_valid, y_test = train_test_split(
x_valid,
y_valid,
test_size=0.5,
shuffle=True,
stratify=y_valid,
random_state=777,
)
train_data = dataset(x_train, y_train)
valid_data = dataset(x_valid, y_valid)
test_data = dataset(x_test, y_test)
train_batch_size = 32
train_dataloader = DataLoader(train_data, batch_size=train_batch_size,shuffle=True)
valid_dataloader = DataLoader(valid_data, batch_size=1)
test_dataloader = DataLoader(test_data, batch_size=1)
Network = network(input_channel=train_class_num, output_channel=label_class_num)
summary_model = summary(Network)
print(f"### model is ready!!!###\n\n{Network}")
lr = 0.00001
step_size = 30
gamma = 0.1
total_epoch = 30
save_path = "./model/mushroom_epoch30.pt"
## device설정 : Gpu가 없어서 cpu로 진행 ㅠㅠ
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(f"\n### The device is --{device}-- that we use ###")
Network = Network.to(device)
test_signal = input(str("Do you want to train ? (y or n) : "))
if test_signal == "y":
# 옵티마이저, 스케쥴러, 손실함수(이진분류라서 binary선택) 선택
optimizer = optim.Adam(Network.parameters(), lr=lr)
scheduler = optim.lr_scheduler.StepLR(
optimizer=optimizer, step_size=step_size, gamma=gamma
)
criterion = nn.BCELoss()
total_loss = {"val": [], "train": []}
for epoch in range(total_epoch):
Network.train()
epoch_train_loss = 0.0
for i, data in enumerate(train_dataloader,0):
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 초기화
outputs = Network(inputs)
loss = criterion(outputs, labels)
batch_train_loss = loss.item() # loss만 가져오기
loss.backward() # 역전파 기록 저장
optimizer.step() # 업데이트
epoch_train_loss += batch_train_loss
avg_train_loss = epoch_train_loss / len(train_dataloader)
Network.eval()
val_epoch_loss = 0.0
for i, data in enumerate(valid_dataloader, 0):
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = Network(inputs)
loss = criterion(outputs, labels)
val_batch_loss = loss.item()
val_epoch_loss += val_batch_loss
avg_val_loss = val_epoch_loss / len(valid_dataloader)
total_loss["train"].append(avg_train_loss)
total_loss["val"].append(avg_val_loss)
print(
f"epoch : {epoch} The train loss is {avg_train_loss}, valid loss is {avg_val_loss}"
)
scheduler.step()
x = np.arange(1, total_epoch + 1)
plt.plot(x, total_loss["train"], "r", label="train")
plt.plot(x, total_loss["val"], "b", label="val")
plt.legend()
plt.title("Mushroom Deeplearning")
plt.yscale("logit")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
torch.save(Network.state_dict(),save_path)
elif test_signal == "n":
Network = network(input_channel=train_class_num,output_channel=label_class_num)
Network.load_state_dict(torch.load(save_path))
Network.eval()
result = []
for i, data in enumerate(test_dataloader):
inputs, labels = data
with torch.no_grad():
outputs = Network(inputs)
percent, predicted = torch.max(outputs.data, 1)
if predicted == 0:
if labels[0][0] == 1:
result.append(True)
elif labels[0][1] == 1:
result.append(False)
elif predicted == 1:
if labels[0][0] == 1:
result.append(False)
elif labels[0][1] == 1:
result.append(True)
ok = result.count(True)
ng = result.count(False)
accuracy = ok / (ok + ng) * 100
print(f"model result ok : {ok}, ng : {ng} accuracy is {accuracy}")
정형데이터로 Classification할 때 도움이 되었으면 좋겠네요
