📙 IP 주소란?
거대한 네트워크망에서 컴퓨터를 식별하기 위한 의치 주소
네트워크 상에서의 데이터 송/수신 은 이 주소를 기준으로 한다.
예시) 192.168.0.123
🌏 브라우저란?
크롬, 웨일, 엣지이같이 웹페이지, 이미지, 비디오 등의 컨텐츠를 송/수신 하고 표현해주는 소프트웨어를 말한다.
📙 DNS 란?
Domain Name Server 의 약자
www.naver.com같은 도메인 이름을 말하는 것이다.
원래는 서버의 IP 주소(192.168.0.123)로 가야 하는데 그게 아닌 도메인 이름을 중개해주는 전화번호부와 같은 서버가 중간에 있기 때문에 도메인 주소만으로 갈 수가 있다.
즉, 도메인 이름(사이트 주소)만으로 목적지를 알 수 있어 요청을 보낼 수 있는 것이다.
여기서 서버로 요청을 보낼때 사람마다 요청이 제각각이면 그 요청에 따라 다 다르게 코드를 짤 수는 없다.
그래서 여기서 송신자와 수신자가 공유하고 있는 "약속" 의 개념이 등장한다.
📙 HTTP 란?
데이터를 주고 받는 양식을 정의한
통신 규약중 하나가 HTTP 이다.
여기서 말하는 통신 규약이란, 컴퓨터끼리 데이터를 주고 받을 때 정해둔 약속을 의미한다.
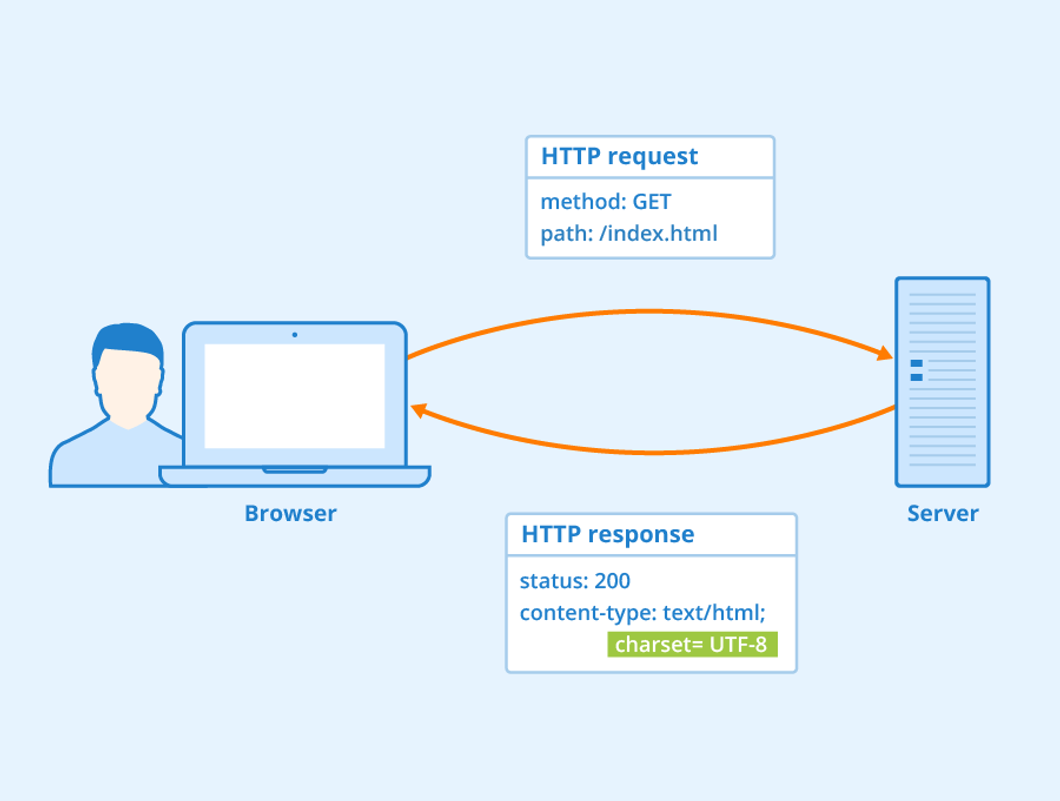
HTTP 에는 항상 Request 와 Response 라는 개념이 존재한다.
이것을 위 이미지 처럼 관계로 가볍게 보자면
- 브라우저는 서버에게 자신이 원하는 페이지(URL 등의 정보) 를 요구(Request) 한다.
- 서버는 브라우저가 원하는 페이지가 있는지 확인, 해당 페이지에 데이터를 실어서 응답(Response)한다. 없다면 없는 페이지에 대한 데이터를 반환
- 브라우저는 서버에게 전달 받은 데이터를 기반으로 브라우저에 그려준다.
이렇게 간단하게 정리가 된다.
위에서 주고 받는 데이터는 어떠한 데이터든 주고 받는 것이 가능하다.
지금까지 계속 공부해왔으면 알 수 있는 대목인 개발자 도구 즉, F12 번을 누르면 볼 수 있는 창에 대한 설명을 해보자
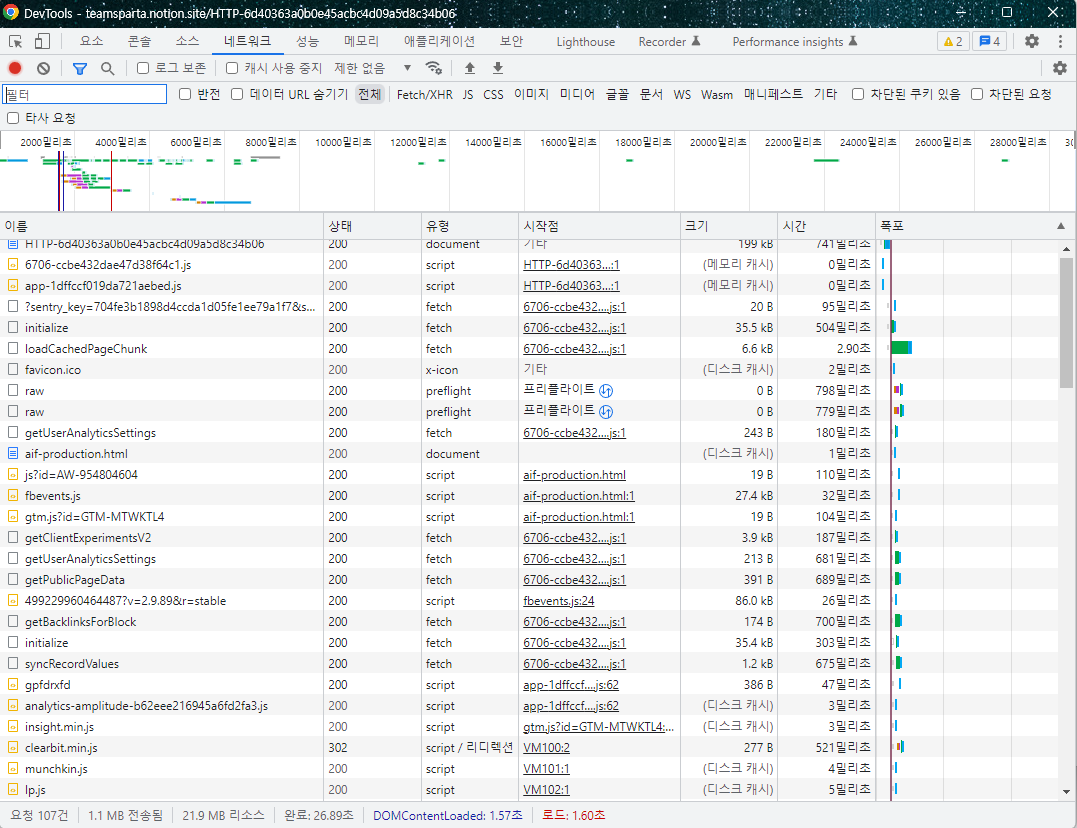
개발자 도구에 진입하고 나서 네트워크 창을 진입한 다음 새로고침을 해주면 뭔가 아래에 쭈욱 나오는 것을 볼 수 있다.
이것이 바로 지금 보고있는 페이지를 보여주기 위해 서버에서 받아온 데이터 목록 이라고 이해하면 된다.
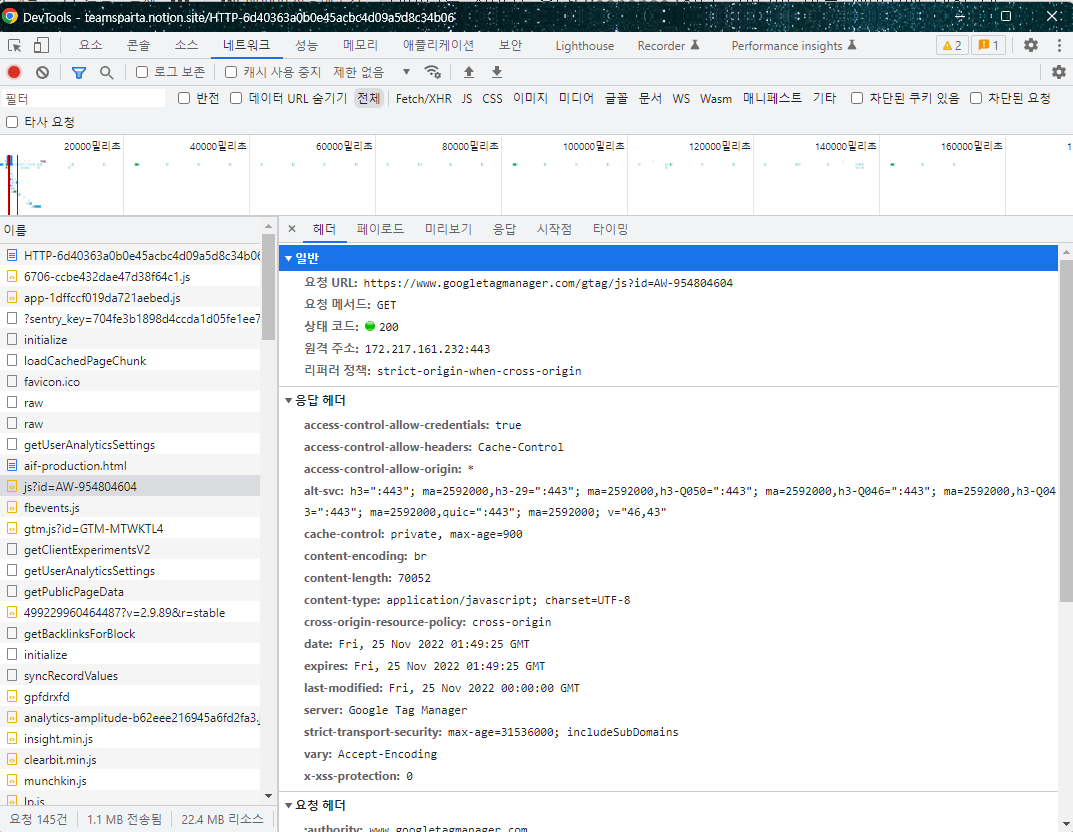

📌 헤더(Headers)탭
안의 정보가 브라우저에서 서버로 보낸 Request 데이터 라고 보면 된다.
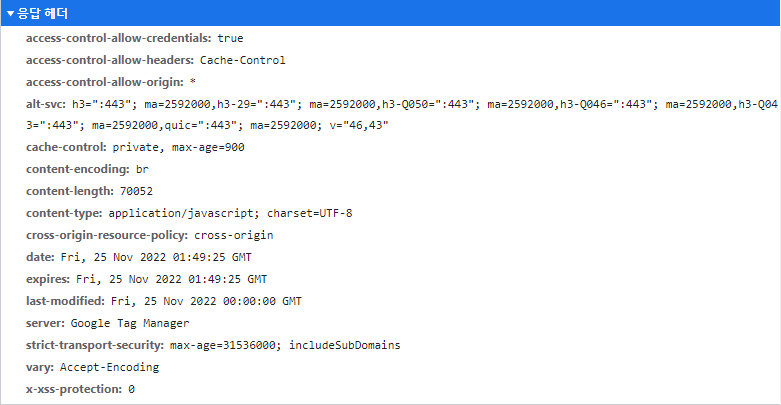
📌 응답 헤더 Requset Header 탭
이것도 브라우저애서 서버로 보낸 Requset 데이터 라고 보면 된다.
📌 요청 헤더 Response Headers 탭
이는 서버가 웹 페이지 데이터와 함께 보낸 추가 데이터이다.
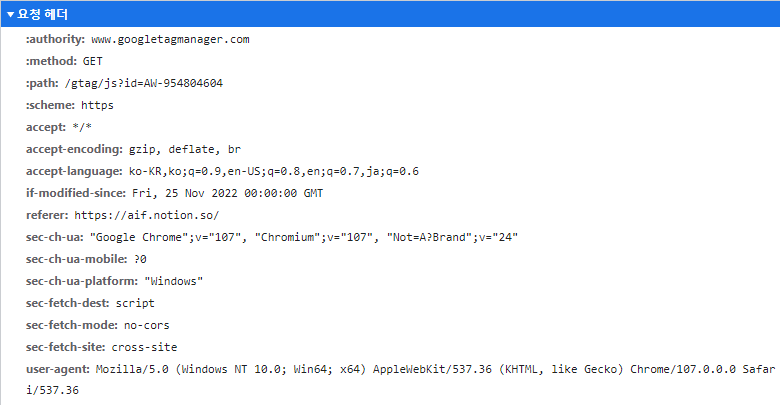
📌 Response 탭
이것은 서버에서 내 브라우저로 반환해준 웹 페이지를 그려주기 위한 데이터 이다.
📌 추가 데이터
Headers 탭 에서 말한 추가 데이터라는 것에 대해 좀 더 알아보자면...
HTTP 에는 다음과 같은 구성요소가 존재한다.
- Mehod(호출/요청 방식)
GET: 이름 그대로 어떤 리소스를 얻을 때 사용된다. 브라우저의 주소창에URL을 입력하면GET메소드를 사용해서 서버에 요청을 보낸다.
POST: 웹 서버에 데이터를 게시할 때 사용하는게 일반적이다. (ex : 회원가입, 게시글 및 댓글 작성) - Header(추가 데이터, 메타 데이터)
브라우저가 어떤 페이지를 원하는지
요청 받은 페이지를 찾았는지
요청 받은 데이터를 성공적으로 찾았는지
어떤 형식으로 데이터를 보낼지 - Payload(데이터, 실제 데이터)
서버가 응답을 보낼 때에는 항상 페이로드를 보낼 수 있다.
클라이언트(브라우저)가 요청을 할 때에도 페이로드를 보낼 수 있다.
GET메소드를 제외하곤 모두 페이로드를 보낼 수 있다 는게 HTTP 에서의 약속이다.
🔖 정리
웹 서버란?
- 인터넷을 통해
HTTP를 이용하여 웹상의 클라이언트의 요청을 응답해 주는 통신을 하는 일종의 컴퓨터- 오늘날 우리가 자주 사용하는 이메일이나 SNS 등 대부분의 서비스는 웹 서버를 통해 우리가 사용할 수 있게 되었다.
웹 서버의 기본 동작 원리
- 브라우저를 통해
HTTP Request로 웹 사이트를 웹 서버에 요청한다.
이후 웹 서버는 요청을 승인하고HTTP responser를 통해 웹 사이트 데이터를 브라우저에 전송한다.
마지막으로 브라우저는 서버에서 받아온 데이터를 이용해 웹 사이트를 브라우저에 그려내는 일을 한다.- 기본적으로 브라우저가 웹 서버에 요청을 할 때에는 항상
GETmethod로 요청을 한다.
위 과정을 통해 요청이 서버에 도달했다면 !!
요청이 서버에 도달했고 API 라는 서버의 창구와 같은 곳에 도달한다.
📙 API
Application Programming Interface 의 약자이다.
다른 소프트웨어 시스템과 통신하기 위해 따라야 하는 규칙을 정의한다.
클라이언트와 웹 리소스 사이의 게이트웨이 라고 생각하자
📙 인터페이스
Interface 는 서로 다른 두 개의 시스템, 장치 사이에서 정보나 신호를 주고받는 경우의 접점이나 경계면이다.
즉, 사용자가 기기를 쉽게 동작시키는데 도움을 주는 시스템을 의미한다.
그렇다면 서버는 htmnl/css/js 파일을 반환해주는게 주 업무인가...?
꼭 그렇다는 것은 아니지만 최근의 경향으로는 서버가 직접 뷰(html/css/js)를 반환하기 보다는 요청에 맞는 정보만을 반환하는 것을 좀 더 선호한다.
아래의 사진처럼 JSON 이라는 형태로 데이터만 반환하기도 한다.
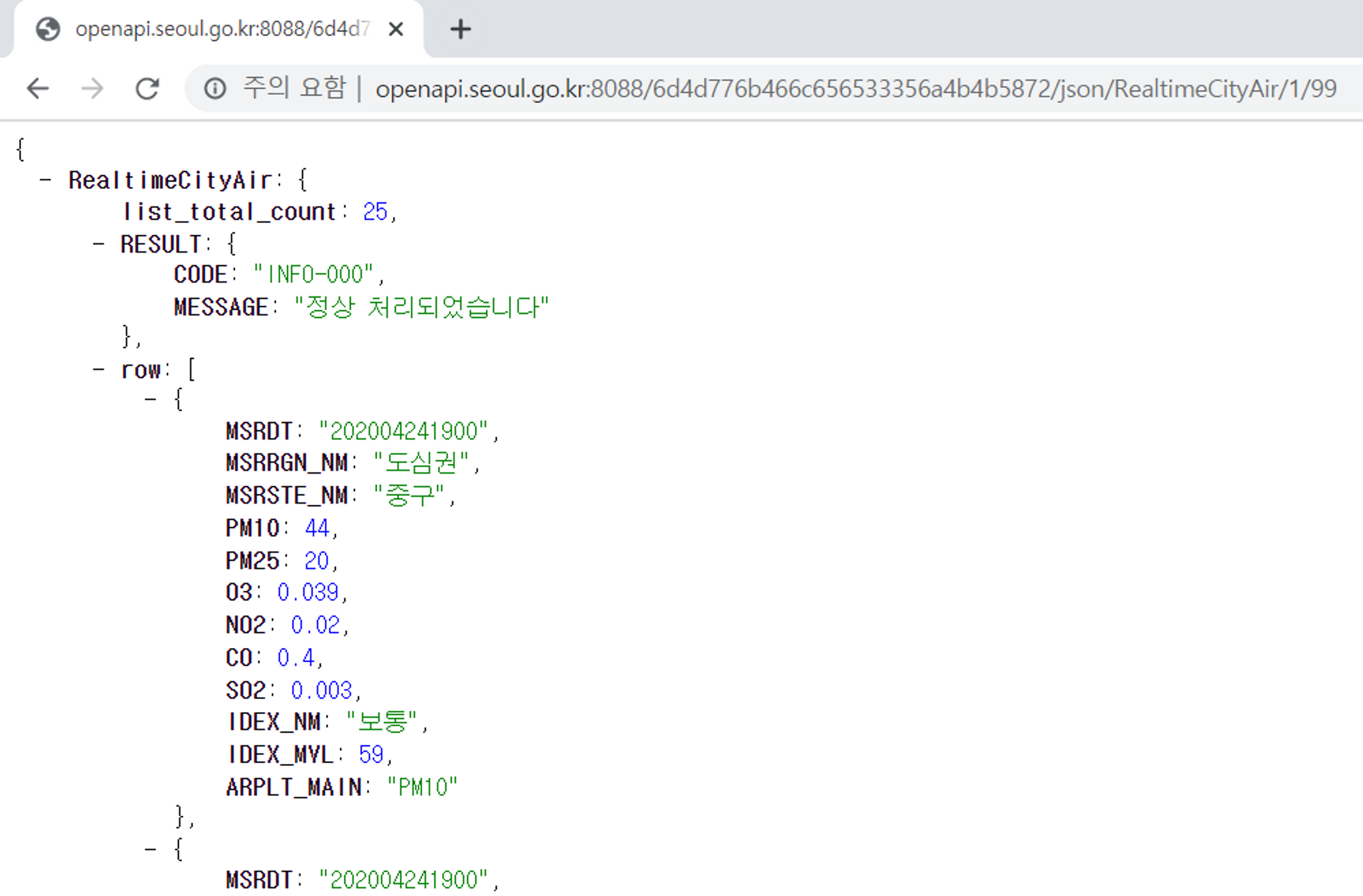
📙 RESTful API란?
Representational State Transfer(REST)는 API 작동 방식에 대한 조건을 부과하는 소프트웨어 아키텍처입니다. REST는 처음에 인터넷과 같은 복잡한 네트워크에서 통신을 관리하기 위한 지침으로 만들어졌습니다. REST 기반 아키텍처를 사용하여 대규모의 고성능 통신을 안정적으로 지원할 수 있습니다. 쉽게 구현하고 수정할 수 있어 모든 API 시스템을 파악하고 여러 플랫폼에서 사용할 수 있습니다.
API 개발자는 여러 아키텍처를 사용하여 API를 설계할 수 있습니다. REST 아키텍처 스타일을 따르는 API를 REST API라고 합니다. REST 아키텍처를 구현하는 웹 서비스를 RESTful 웹 서비스라고 합니다. RESTful API라는 용어는 일반적으로 RESTful 웹 API를 나타냅니다. 하지만 REST API와 RESTful API라는 용어는 같은 의미로 사용할 수 있습니다.
참고 링크 1 : https://aws.amazon.com/ko/what-is/restful-api/
참고 링크 2 : https://velog.io/@jisung5889/REST-API

예를들어 여러분이 api의 리소스 식별자를 ex - (”/”) 중복 없이 고유하게 잘 만들고,
해당 api에 적절하게 http메서드를 사용했다면, RESTful하게 설계했다고 볼 수 있다.
서버가 요청을 처리하 위한 자료
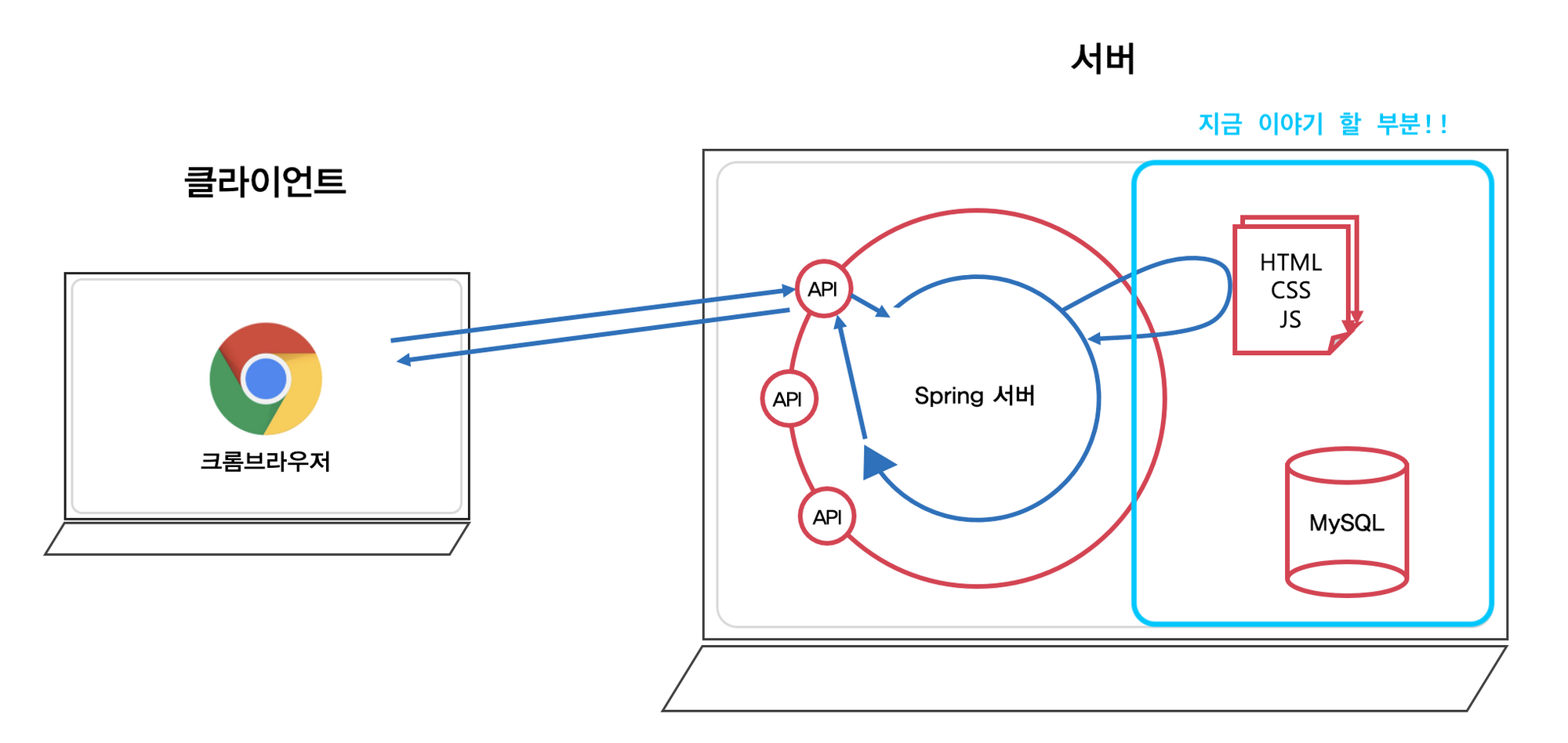
웹개발 프로젝트를 진행하면서 회원가입 및 로그인을 진행했었다.
그 때 필요한 것은 클라이언트의 요청을 네트워크를 타고 들어와서 새로운 정보 인 유저의 ID/Password 를 들고 들어왔다.
하지만 이 때 더 필요한 것이 기존의 정보 이다.
기존의 정보가 있어야 유저가 로그인을 시도하려는 아이디 비밀번호와 대조가 가능하다.
이러한 경우 때문에 서버는 데이터를 저장고 관리하는 DB(데이터베이스) 를 사용하게 된다.
데이터베이스는 왜 있으며, 왜 다양한 종류가 있나요?
처음 접하는 분들이 가장 쉽게 오해하기로는, “정해진 공간에 최대한 많은 데이터를 저장하기 위해서” 일 겁니다. 하지만 사실 데이터베이스는 데이터를 “효율적으로 성능 좋게” 다루기 위해 존재합니다.
즉 더 많이 저장하기 위해서가 아니라, 저장 조회 수정 삭제등을 더 빠르고 효율적으로 처리하기 위해서, “성능상의 이점”을 얻기 위해서 사용한다고 생각하면 좋을 것 같습니다.
이러한 맥락에서 데이터를 사용,활용하는 주체에 따라서 더 효율적인 방법이 각각 다르다 보니 다양한 형식의 데이터베이스가 존재하게 됩니다.
결론적으로 서버 개발에서 그래도 가장 많이 하는 일은, “새로운 정보”와 “기존의 정보”를 가지고 “정해진 로직”을 수행하는 일 입니다.
위와같은 이야기를 하기 위해서,
- 기존에 알고있던 웹 프로그램이 어떻게 동작하는지를 살펴봤고
- 어떻게 새로운 정보인 클라이언트의 요청이 서버로 도달하는지를 살펴봤고
- 어떻게 기존의 정보를 저장하는지를 살펴봤다.
