member api 제작
1. 생성 (create)
1. 파라미터로 Entity 직접 받기 (사용 - X)
@PostMapping("api/v1/members") public CreateMemberResponse saveMemverV1(@RequestBody @Valid Member member ){ Long id = memberService.join(member); return new CreateMemberResponse(id); }2. DTO를 사용해서 받기
@PostMapping("api/v2/members") public CreateMemberResponse saveMemverV2(@RequestBody @Valid CreateMemberRequest response ){ Member member = new Member(); member.setName(response.name); Long id = memberService.join(member); return new CreateMemberResponse(id); }Entity와 비교했을 때 DTO로 받았을 때 장점
- 검증 BeanValidation 설정 시 파라미터 별 다양한 설정을 할 수 있다.
- Entity가 변경 되어도 api 스펙이 변경되지 않는다. (파라미터 객체로 json 데이터를 받음으로써)
@RequestMapping("/api/v2/members") public CreateMemberResponse saveMemberV2(@RequestBody @Valid CreateMemberRequest request){ Member member = new Member(); member.setName(request.getName()); Long id = memberService.join(member); return new CreateMemberResponse(id); }1) CreateMemberRequest를 만듬으로써 Member 엔티티의 변수명이 변경되더라도 api 스펙 변화에는 지장이 없다.
3. 파라미터 객체로 받을 경우 api 스펙이 어떻게 되어있는지 바로 알 수가 있다. (Entity로 매개변수를 받을 경우 내부의 값들 중 뭐가 넘어올 지 모르기 때문에)2. 조회 (SELECT)
1. 파라미터로 Entity 직접 받기 (사용 - X)
@GetMapping("api/v1/members") public List<Member> memberV1(){ return memberService.findMembers(); }1) 멤버와 관련 없는 테이블도 노출 될 수 있다.
(멤버와 연관 없는 Orders 노출)2. DTO와 Result로 한번 더 감싸기
@GetMapping("api/v2/members") public Result memberV2(){ List<Member> findMember = memberService.findMembers(); List<MemberDto> collect = findMember.stream() .map(m -> new MemberDto(m.getName())) .collect(Collectors.toList()); return new Result(collect); } @Data @AllArgsConstructor static class Result<T>{ private T data; } @Data @AllArgsConstructor static class MemberDto{ private String name; }1) DTO를 통해 외부에 노출하고 싶지 않는 데이터를 숨길 수 있다.
2) Result로 한번 감쌈으로써 [{},{}]와 같이 배열 타입의 Json형식으로 나가게 하는 것을 방지한다. (유연성 증가)
2-1) 전
2-2) 후



API 개발 고급 - 지연 로딩과 조회 성능 최적화
얻고자하는 엔티티와의 관계가 ..ToOne 관계들일 경우에 해당한다.
1-4번 중 어느것을 사용할 지 선택방법(숫자가 내려 갈 수록 성능 최적화 업)
- 엔티티를 파라미터로 직접 받는것이 아닌 DTO로 변환
- fetch join을 사용해서 성능 최적화
- DTO를 직접 방는 방식으로 전환한다.
- JDBC Template or Native Query를 사용해서 직접 쿼리를 실행한다.
요약
- 1) 엔티티 DTO를 JPA를 통해 바로 조회(+Join) , 2) 엔티티 DTO 조회 및 fetch Join 사용 둘 중 하나를 사용하자
- 엔티티 DTO 조회 및 fetch Join을 사용 시 재사용성이 높지만 DTO를 통한 API 응답을 위한 성능면에서는 필요한 데이터만 DB 조회 및 반환하는 JPA를 통해 바로 조회가 더 좋다.
- 즉, 많이 조회할 경우에는 1)을 최적화 차원에서 사용하며, 아닐 경우에는 2)을 권장한다.
1. 엔티티 DTO를 JPA를 통해 바로 조회(+Join)
//선언 package jpabook.jpashop.repository; public List<OrderSimpleQueryDto> findOrderDto(){ return em.createQuery("SELECT new jpabook.jpashop.api.dto.OrderSimpleQueryDto(o.id , m.name,o.orderDate,o.status,d.address) " + "FROM Order o " + "join fetch o.member m " + "join o.delivery d", OrderSimpleQueryDto.class).getResultList(); } //사용 @GetMapping("/api/v4/sample-orders") public List<OrderSimpleQueryDto> orderV4(){ return orderRepository.findOrderDto(); }1) 바로 DTO를 통해 가져올 경우 내가 원하는 데이터만 DB에서 가져 올 수 있다. (엔티티를 조회 후 DTO 사용 시 우선 모든 데이터를 가져와야 함으로써 추가 비용 발생)
2) Dto를 바로 뽑는 경우 해당 쿼리 코드를 repository에서 만드는 것이 아닌 repository 패키지 하위 폴더에 해당 Dto 쿼리용 클래스를 제작한다. ( repository의 API 스펙이 담긴 메서드를 두는 것이 아닌 객체를 분리한다. )
2-1) 별도의 패키지 분리@Repository @RequiredArgsConstructor public class OrderSimpleQueryRepository { private final EntityManager em; public List<OrderSimpleQueryDto> findOrderDto(){ return em.createQuery("SELECT new jpabook.jpashop.api.dto.OrderSimpleQueryDto(o.id , m.name,o.orderDate,o.status,d.address) " + "FROM Order o " + "join fetch o.member m " + "join o.delivery d", OrderSimpleQueryDto.class).getResultList(); } }2-2) OrderSimpleQueryRepository 작성
3) fetch Join 대신 Join 사용
3-1) fetch Join 사용할 경우 에러 발생
' query specified join fetching, but the owner of the fetched association was not present in the select list '
참고
fetch Join 사용 DTO 조회2. 엔티티 DTO 조회 및 fetch Join 사용 - 성능 최적화
package jpabook.jpashop.repository; public List<Order> orderfindAllwithMemberDelivery() { return em.createQuery("SELECT o FROM Order o " + "join fetch o.member" + "join fetch o.delivery", Order.class).getResultList(); }1) fetch Join을 통해 한번 쿼리를 통해 연관 엔티티의 모든 값들을 가져올 수 있다.
1-1) fetch Join으로 인해 지연로딩이 발생하지 않는다.3. 엔티티 DTO 조회
@GetMapping("/api/v2/sample-orders") public List<SimpleOrderDto> orderV2(){ List<Order> orders = orderService.findOrders(new OrderSearch()); List<SimpleOrderDto> result = orders.stream() .map(o -> new SimpleOrderDto(o)) .collect(Collectors.toList()); return result; } @Data static class SimpleOrderDto{ private Long id; private String name; private LocalDateTime orderDate; private OrderStatus orderStatus; private Address address; public SimpleOrderDto(Order o) { id = o.getId(); name=o.getMember().getName(); // LAZY orderDate =o.getOrderDate(); orderStatus = o.getStatus(); address = o.getDelivery().getAddress(); // LAZY } }1) order와 그에 관련된 Entity를 이와 같이 호출 할 경우 N+1 문제가 발생한다.
=> 이것을 해결하기 위해 fetch Join을 사용한다.4. 조회 시 엔티티를 직접 반환 할 때 발생 문제점- 사용 X
@GetMapping("/api/v1/simple-orders") public List<Order> orderV1(){ List<Order> orders = orderService.findOrders(new OrderSearch()); return orders; }1) GetMapping으로 해당 List를 Return할 경우
1-1) Order에서 Member을 참조하고, Member에서 Order을 참조하기에 무한 참조 Error가 발생할 수 있다.
=> 한쪽은 @JsonIgnore을 지정하자@JsonIgnore @OneToMany(mappedBy = "member") private List<Order> orders = new ArrayList<>();2) 지연로딩의 경우
@ManyToOne(fetch = LAZY) @JoinColumn(name = "member_id") private Member member;2-1) Order 엔티티의 Member의 경우 지연로딩이며 이럴 경우 값은 Proxy 객체를 넣어주게 되며 Json 변환 시 Error가 발생한다.
=> Json을 변형 시 Proxy의 경우 반환하지 않도록 하는 설정을 추가하자
1) implementation 'com.fasterxml.jackson.datatype:jackson-datatype-hibernate5' 라이브러리 추가
2) Bean 등록하면 지연로딩은 Json으로 반환하지 않게 된다.@Bean Hibernate5Module hibernate5Module() { return new Hibernate5Module(); }
API 개발 고급 - 컬렉션 조회 최적화
얻고자하는 엔티티와의 관계가 ..ToMany 관계들일 경우에 해당한다.
1. 최적화 (ToMany N+1 문제 해결)
1. 1번 쿼리로 모든 것을 불러낸다
public class OrderFlatDto { private Long orderId; private String name; private LocalDateTime orderDate; //주문시간 private OrderStatus orderStatus; private Address address; //OrderItem private String itemName;//상품 명 private int orderPrice; //주문 가격 private int count; public OrderFlatDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, String itemName, int orderPrice, int count) { this.orderId = orderId; this.name = name; this.orderDate = orderDate; this.orderStatus = orderStatus; this.address = address; this.itemName = itemName; this.orderPrice = orderPrice; this.count = count; } }public List<OrderFlatDto> findByDto_flash() { return em.createQuery( "select new "+ " jpabook.jpashop.api.dto.OrderFlatDto(o.id, m.name, o.orderDate, "+ " o.status, d.address, i.name, oi.orderPrice, oi.count)" + " from Order o" + " join o.member m" + " join o.delivery d" + " join o.orderItems oi" + " join oi.item i", OrderFlatDto.class) .getResultList(); }1) Dto에서 필요한 정보들을 풀어해친다 (ToMany 객체 안에 필요로 하는 정보 나열)
2) Dto문으로 join을 해서 작성한다.
3) ToMany임으로 DB안에서 데이터가 뻥튀기 되는 건 동일하기에 페이징은 안된다.2. ToMany를 요청 할때 쿼리를 튜닝해서 최적화한다.
public List<OrderQueryDto> findAllByDto_optimization() { List<OrderQueryDto> orders = findOrders();// 여기까지는 ToOne 한방쿼리 동일 List<Long> orderIds = orders.stream() .map(o -> o.getOrderId()) .collect(Collectors.toList()); List<OrderItemQueryDto> orderItems = em.createQuery("SELECT new jpabook.jpashop.api.dto.OrderItemQueryDto(oi.order.id , i.name , oi.orderPrice , oi.count) " + " FROM OrderItem oi " + " join oi.item i " + " WHERE oi.order.id in :orderIds", OrderItemQueryDto.class) //Where in으로 바꾼 후 쿼리를 최적화 한다. .setParameter("orderIds", orderIds) .getResultList(); Map<Long, List<OrderItemQueryDto>> colletions = orderItems.stream() .collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId())); orders.forEach(o->o.setOrderItems(colletions.get(o.getOrderId()))); return orders; }1) ToOne은 동일하게 fetch Join으로 가져온다. (Dto로 바로 조회일 경우 Join으로)
2) ToMany의 경우 Where = 문이 아닌 Where in을 써서 쿼리를 최적화한다.2. DTO를 직접 조회 - (ToMany에서 N+1 문제 발생)
- 리포지토리 작성
public List<OrderQueryDto> findOrderDto(){ List<OrderQueryDto> orders = findOrders(); orders.forEach(o -> { List<OrderItemQueryDto> orderItem = findorderItems(o.getOrderId()); o.setOrderItems(orderItem); }); return orders; } //To Many 조인 private List<OrderItemQueryDto> findorderItems(Long orderId) { return em.createQuery("SELECT new jpabook.jpashop.api.dto.OrderItemQueryDto(oi.order.id , i.name , oi.orderPrice , oi.count) " + " FROM OrderItem oi " + " join oi.item i " + " WHERE oi.order.id = :orderId", OrderItemQueryDto.class ) .setParameter("orderId",orderId) .getResultList(); } //여기서 페이징 사용 //ToOne 조인 private List<OrderQueryDto> findOrders() { return em.createQuery("SELECT new jpabook.jpashop.api.dto.OrderQueryDto(o.id , m.name,o.orderDate,o.status,d.address) " + "FROM Order o " + "join o.member m " + "join o.delivery d", OrderQueryDto.class).getResultList(); }
- 해당 쿼리는 1+N(컬랙션의 갯수) 만큼 쿼리가 나가게 된다.
- ToMany를 따로 분리한 이유는 DB에서 데이터가 뻥튀기 되기 떄문에 분리해서 set으로 데이터를 채워주는 방식을 사용했다.
3. 엔티티 페이징 해결 (ToOne과 ToMany 쿼리 분리 작업)
- @BatchSize or hibernate.default_batch_fetch_size(전체 적용)를 사용해서 데이터를 미리 가져오는 방안이다.
1-1) ToOne은 사실상 데이터 뻥튀기가 안됨으로 fetchJoin만 사용해도 페이징이 잘 된다.
1-2) size의 minimum은 없지만 maximum은 최대 1000개 이다. (1000개 이상이 되면 에러를 발생 시키는 쿼리들이 있다.)
1-3) 개인적으로 대략 100-1000 사이가 적당하다고 생각한다.3-1. 구현
- ToOne에 해당하는 엔티티는 fetch join으로 사용하기 위해 따로 분리 작업
public List<Order> orderfindAllwithMemberDelivery() { return em.createQuery("SELECT o FROM Order o " + "join fetch o.member m " + "join fetch o.delivery d", Order.class).getResultList(); }
- 적용 및 글로벌 batch 변수 적용
2-1) 적용@GetMapping("/api/v4/orders") public List<OrderDto> ordersV4(){ List<Order> orders = orderRepository.orderfindAllwithMemberDelivery(); List<OrderDto> result = orders.stream() .map(OrderDto::new) .collect(Collectors.toList()); return result; }2-2) 글로벌 변수 추가 (application.yml)
spring: jpa: hibernate: properties: hibernate: default_batch_fetch_size: 1003-2. 4번과의 비교
1) 4번은 페이징의 문제가 있지만 한방 쿼리로 모든 내역이 나가며, 2번의 경우에는 ToOne으로 엔티티와 연관 되어 있는 ToOne 엔티티 한번 orderItems =o.getOrderItems();관련 orderITem 1번 , o.getOrderItems().stream().forEach(n ->n.getItem().getName());에서 orderItem.item 관련 1번 총 3번의 쿼리가 나가게 된다. 그러면 4번이 더 좋은게 아닐까?
2) Application에서만 보면 그럴지도 모르지만 DB입장에서는 이야기가 나간다. 해당 3번 쿼리를 DB에서 실행하면 데이터가 뻥튀기 되어서 출력이 된다. 즉 DB 측면과 네트워크 및 페이징을 사용할 수 있음으로 2번이 효율성이 높다고 할 수 있다4. 엔티티 DTO+fetch Join -> (사실상 3번을 사용하는 것이 좋을 것 같다)
- orders Dto 변환해서 반환
@GetMapping("/api/v3/orders") public List<OrderDto> ordersV3(){ List<Order> orders = orderRepository.findAllWithItem(); List<OrderDto> result = orders.stream() .map(OrderDto::new) .collect(Collectors.toList()); return result; }
- join fetch 사용
public List<Order> findAllWithItem() { return em.createQuery("SELECT distinct o FROM Order o " + " join fetch o.member m " + " join fetch o.delivery d " + " join fetch o.orderItems oi " + " join fetch oi.item i", Order.class).getResultList(); }2-1) toMany의 경우 데이터가 뻥튀기가 된다. 중복되는 값을 방지 하기 위해 distinct를 필수로 넣어줘야 한다.
2-2) JPA의 Distinct의 경우 Order의 id가 동일하면 중복을 제거해준다. (DB는 완벽이 값이 같아야 중복을 제거한다.)
3. 단점
3-1) 페이징 사용 불가 : 사실상 fetch join을 1대 다에서 사용하게 되면 데이터가 뻥튀기가 돼서 실질적 페이징 규칙이 어긋나게 되기에 사용이 불가능 해진다. (일대다 아닐 경우 상관없다.) 그래서 하이버네이트에서는 해당 경우에 대한 데이터를 모두 메모리에 가져온 후 페이징을 진행한다. (메모리 초과가 날 수 있음으로 위험하다.)
3-2) 일대다 컬렉션 조인은 1개만 : 만약 2개 이상을 할 경우 1NM와 같은 데이터가 뻥튀기가 되어서 짐작을 할 수가 없게된다.5. 조회 시 엔티티를 직접 반환 - X
API 개발 정리
엔티티 조회 방식으로 우선 접근
1. 페치조인으로 쿼리 수를 최적화
2. 컬렉션 최적화
1. 페이징 필요 hibernate.default_batch_fetch_size , @BatchSize로 최적화
2. 페이징 필요X 페치 조인 사용
2. 엔티티 조회 방식으로 해결이 안되면 DTO 직접 조회 방식 사용
2.1 1-2번 사용
2.2 2번 사용
3. DTO 조회 방식으로 해결이 안되면 NativeSQL or 스프링 JdbcTemplate참고
엔티티 조회 방식은 페치 조인이나, @BatchSize , hibernate.default_batch_fetch_size 같이 코드를 거의 수정하지 않고, 옵션만 약간 변경해서, 다양한 성능 최적화를 시도할 수 있다. 반면에 DTO를 직접 조회하는 방식은 성능을 최적화 하거나 성능 최적화 방식을 변경할 때 많은 코드를 변경해야 한다.( 또한 DTO를 직접 조회할 수준까지 오면 이것을 적용하는 것보다는 Redis같은 캐시 저장 기능을 사용해야 된다고 생각한다. )
OSIV(Open Session in view)와 성능 최적화
- Open Session in view : 하이버네이트
- open EntityManage in view : Jpa
- spring.jpa.open-in-view : true 기본값
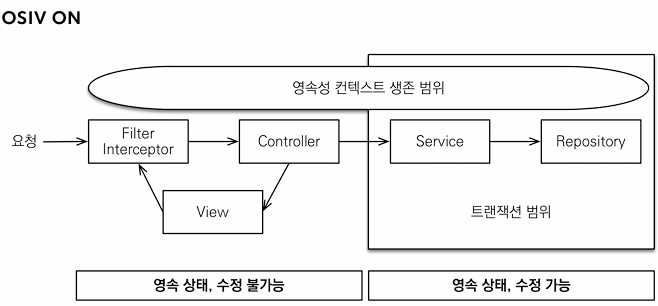
OSIV true 시
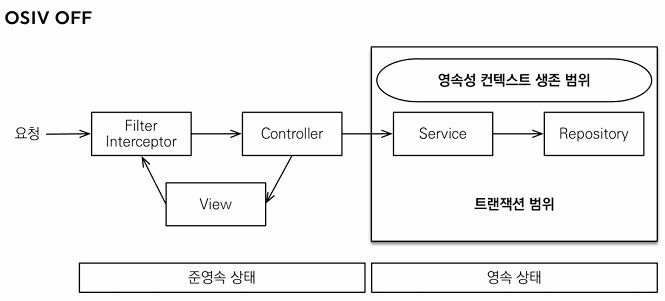
OSIV가 true일 경우 영속성 컨텍스트와 DB 커넥션을 응답이 나갈때 까지 유지한다. 이로 인해 Controller에서 지연로딩을 사용하는 등의 장점을 가질 수 있지만, 그만큼 DB 커넥션을 길게 가지고 있기에 트래픽이 높을 경우 커넥션이 금방 부족해지는 에러가 발생 할 수 있다.OSIV false 시
OSIV를 끄면 트랜잭션을 종료할 때(보통 서비스에서 트랜잭션을 걸어 둠으로) 영속성 컨텍스트를 닫고, 데이터베이스 커넥션도 반환한다. 따라서 커넥션 리소스를 낭비하지 않게 된다. 하지만 Controller , view 영역에서 지연로딩을 사용할 경우 영속성 컨텍스트가 존재하기 않기에 프록시 초기화 에러등이 발생 한다.해결 방안
- 트랜잭션 범위(서비스)에서 필요한 엔티티의 값을 모두 가져온다.
- fetch join을 사용한다.
- 커멘드와 쿼리 분리
보통 비즈니스 로직은 특정 엔티티를 등록하거나 수정하는 것이므로 성능이 크게 문제가 되지 않는다. 그런데 복잡한 화면을 출력하기 위한 조회용 쿼리는 성능을 최적화 하는 것이 중요하다. 그래서 크고 복잡한 애플리케이션을 개발한다면, 이 둘의 관심사를 명확하게 분리하는 선택은 유지보수 관점에서 충분히 의미 있다.
단순하게 설명해서 다음처럼 분리하는 것이다.
OrderService라면
OrderService: 핵심 비즈니스 로직()
OrderQueryService: 화면이나 API에 맞춘 서비스 (주로 읽기 전용 트랜잭션 사용)
true vs false
필자는 고객 서비스의 실시간 API는 OSIV를 끄고, ADMIN 처럼 커넥션을 많이 사용하지 않는 곳에서는 OSIV를 켠다.
API 개발 시 발견한 참고 사항
1. Entity는 외부 노출을 금지해라
1. Entity 변경 할 경우 api 스펙의 변경문제가 발생한다.
2. Entity 정보가 노출 되는 것은 좋지 않다.
3. 실수 할만한 Point
@Getter static class OrderDto{ private Long orderId; private OrderStatus status; private Address address; private List<OrderItem> orderItems; public OrderDto(Order o){ orderId = o.getId(); status = o.getStatus(); address = o.getDelivery().getAddress(); orderItems =o.getOrderItems() ; o.getOrderItems().stream().forEach(n ->n.getItem().getName()); } }해당 코드에서 OrderItem도 Entity임으로 이것 또한 DTO로 변경하는 것이 중요하다.
2. 지연로딩(LAZY)로 인한 proxy 객체를 Json 변환 시 에러 발생
- 엔티티를 바로 반환할 때 Json으로 변환 과정에서 InvalidDefinitionException가 발생했다. Proxy 객체를 Json으로 변환 시 발생한다는 메세지를 담고 있었다.
- 해결
@Bean Hibernate5Module hibernate5Module() { return new Hibernate5Module(); }2-1) 해당 Bean을 추가해서 LAZY Loading 관련 문제를 해결한다.
참고
