
무엇을 배웠을까?💡
정답이 있는 문제는 어떻게 풀까?
Supervised Learning
가장 흔하고, 성공적인 학습 방식이고 정답 레이블이 있는 트레이닝 셋 {}이 주어진다. x는 input feature or input variable, y는 output variable or target variable 이라고 얘기한다. 여기서 y가 유한한 값인지, 연속적인 값인지에 따라 Classification, Regression으로 나뉜다. 학습 알고리즘은 어떤 모델을 쓰느냐에 따라 달라지기 때문에 데이터의 형태, 데이터 셋의 크기 등에 따라서 상황에 맞게 다른 알고리즘을 사용해야 한다.
Linear Model
다른 복잡한 방식의 기본이 되는 모델이다.
linear regression :
logistic regression : 분류를 위한 decision boundary를 찾는 것
Support Vector Machine (SVM)
딥러닝 이전에 가장 인기있던 학습 알고리즘으로 Maximum margin separator를 찾는 것이 목표이다. SVM은 수학적으로 잘 정의되기 때문에 Convex Optimization을 통해 해결할 수 있다.
Naive Bayes Classification
원리가 간단하고 구현이 쉬워서 많이 쓰이는 분류 알고리즘이다. Bayes Rule이라는 확률 공식을 이용하는데, 이는 조건부 확률을 계산하는 공식이다. B라는 사건이 일어났을 때 A라는 사건이 일어날 확률 즉, 이다. 이 Bayes Rule을 이용하면 input feature x가 y라는 클래스로 분류될 확률을 구할 수 있는데 input feature들이 서로 독립이라는 가정이 필요하다. 그러면 이다. 따라서 이다. Naive Bayes Classification은 적은 트레이닝 데이터로도 잘 작동하고 계산 속도가 매우 빠르다.
Gaussian Process
데이터 {}가 가우시안 프로세스에 의해 생성됐다고 가정한다. 즉 output variable이 gaussian분포를 이룬다고 가정하는 것이다. 새로운 input 에 대한 output 또한 Gaussian Process에 의해 생성되었다고 가정하면 이미 학습된 평균값과 분산값을 통해서 에 대해서도 똑같이 Gaussian 분포가 되기 때문에 조건부 확률에 의해서 의 평균값과 분산값을 예측할 수 있다. 하지만 input feature들이 고차원이거나 데이터가 많아지면 적용이 어려워진다.
K-Nearest Neighbors (KNN)
K-Nearest Neighbors 알고리즘은 어떤 model이 따로 있는 것이 아니라 트레이닝 데이터들을 모두 저장해 놨다가 새로운 인풋 데이터가 들어왔을 때 그 트레이닝 데이터에서 가장 가까운 Neighbors를 통해서 prediction한다. Classification에서는 k-nearest neighbors에서 다수결로, Regression에서는 k-nearest neighbors의 average 혹은 linear regression을 통해 prediction한다. KNN은 아주 쉽고 간단하게 적용할 수 있다는 장점이 있지만 Curse of Dimensionality, 즉 차원의 저주가 존재한다. input feature가 고차원이 되면 트레이닝 데이터가 아무리 많아도 그 고차원의 공간을 다 커버하기 어렵다는 뜻이다. 따라서 input feature가 저차원이고 학습 데이터가 많을 때 잘 작동하는데, 학습 데이터가 많으면 계산 cost가 커지는 문제가 있다.
Decision Tree
Classifiaction, Regression에 모두 적용가능한 간단하지만 강력한 접근법이다. 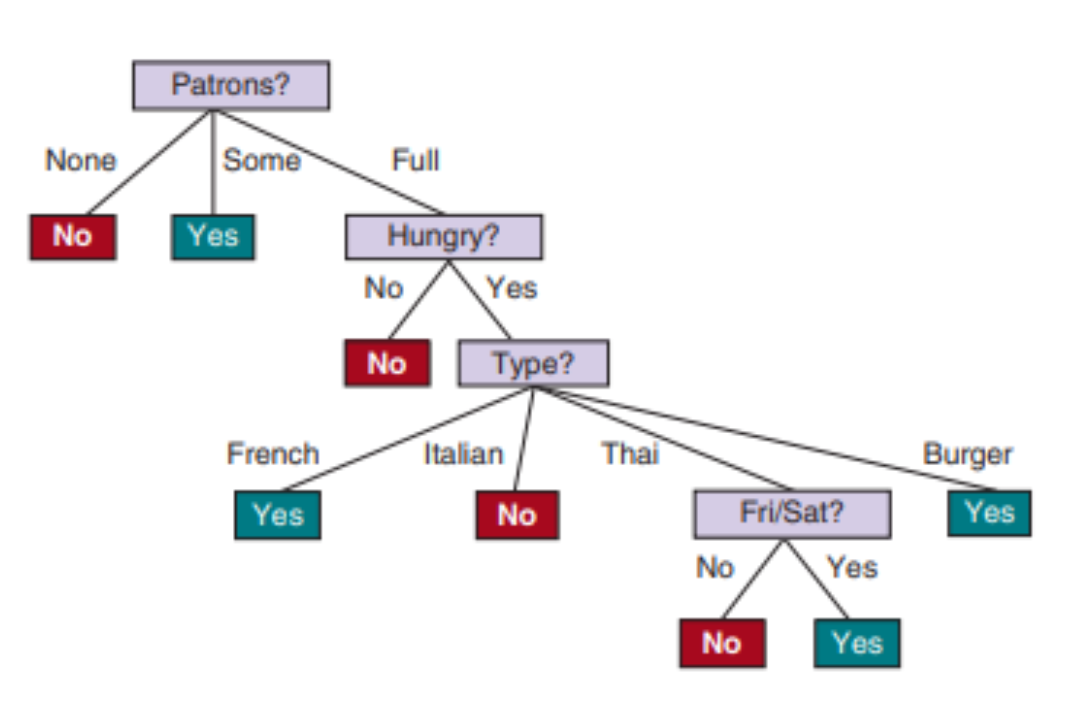 사람의 사고방식과 유사하고 explainable한 모델이다. 그러나 overfitting이 되기 쉽다는 단점이 있다. 그래서 random forest와 같은 방식으로 단점을 극복한다.
사람의 사고방식과 유사하고 explainable한 모델이다. 그러나 overfitting이 되기 쉽다는 단점이 있다. 그래서 random forest와 같은 방식으로 단점을 극복한다.
Neural Network
input layer에 input feature들이 들어가고 각각의 노드를 이전 레이어의 모든 노드들과 연결을 통해서 weighted sum을 하고 거기에 어떤 함수 를 거친 결과를 내도록 모델링을 해서 그 노드들을 한 레이어 안에서 여러 개를 모아서 hidden layer를 만들고 최종적으로 반복을 통해서 아웃풋을 계산한다. 예측한 output 와 트레이닝 데이터 셋의 output 를 가지고 손실 함수를 계산해서 각각의 노드에 대한 weight를 학습하기 때문에 Explainability가 떨어지는 model이라고 할 수 있다. Neural Network는 Gradient Descent를 통해 반복적으로 업데이트하고 학습을 진행하기 때문에 학습이 오래 걸리고, Overfitting이 잘 된다는 단점이 있다. 따라서 Regularization 기술들을 잘 써야하고, 학습 데이터가 많아야 한다.
Wrap-UP
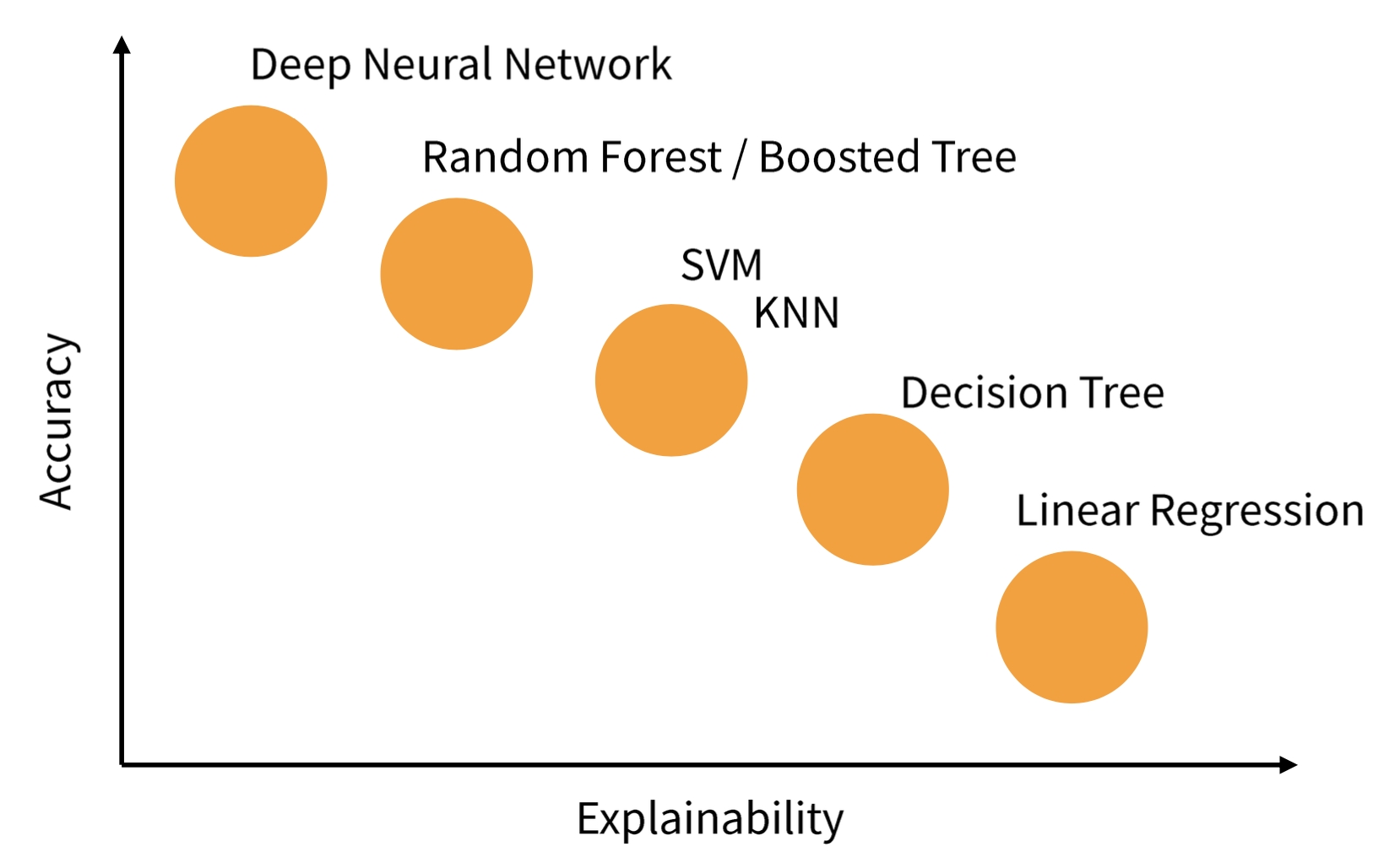
상황에 맞는 알고리즘을 사용해야 하고, 서비스의 신뢰도를 위해서는 Explainability도 중요하다.
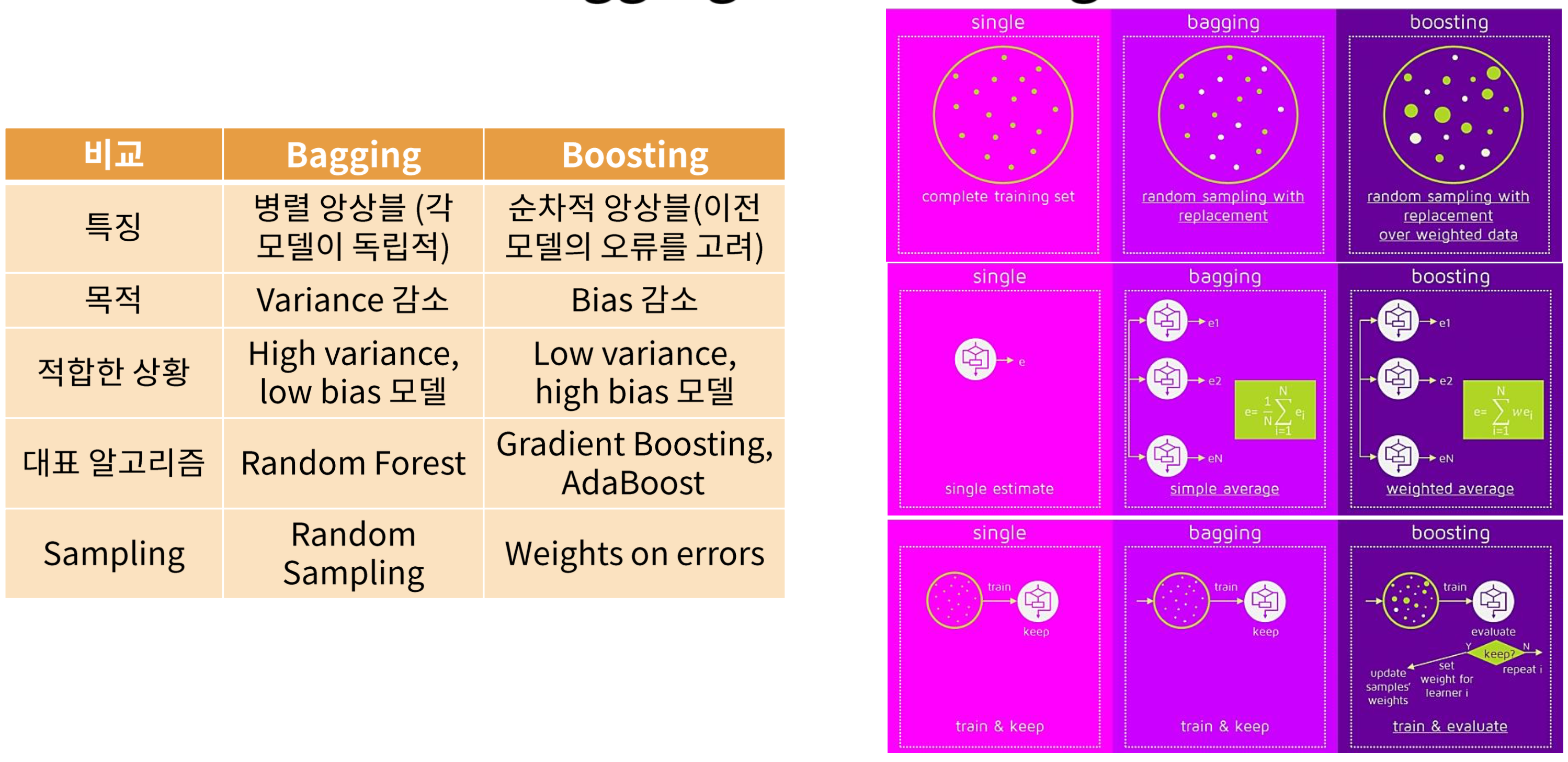
Ensemble: Bagging, Boosting
여러 개의 간단한 Building Block을 모아서 강력한 모델을 만드는 법이다. 특히 Decision Tree를 Building Block으로 활용하면 Bagging, Random Forest, Boosting 등의 Ensemble 기법을 활용할 수 있다.
Bagging - Bootstrap Aggregation
핵심 아이디어는 variance가 인 독립변수 n개가 있을 때 이들의 평균을 취한 의 variance는 이다. 따라서 여러 개의 Decision Tree의 결과를 평균해서 최종 예측을 하면 variance를 줄일 수 있다는 것이다.
Bootstrapping: 데이터셋에서 random하게 복원추출을 통해서 B개의 bootstrapped 데이터 셋을 만드는 것이다.
각각의 bootstrapped 데이터 셋에 모델을 학습을 시키고 전체 B개의 예측에 평균을 취해서 최종 예측값을 얻는다. 이 때 B개의 tree들은 pruning하지 않는다. 왜냐하면 Bagging을 통해서 variance를 줄여줄 것이기 때문에 low bias, high variance의 모델을 얻는다.
복원 추출을 하기 때문에 전체 데이터의 약 1/3은 한 번도 뽑히지 않게 된다. 이 데이터들을 OOB(Out of Bag)데이터라고 부르고 이들을 활용해서 validation error를 계산할 수 있다.
Random Forest
Bootstrapped 데이터셋은 서로 correlation이 높기 때문에 Bagging을 해도 독립된 모델을 얻지 못한다. 따라서 Random Forest에서는 split을 진행할 때 마다 전체 p개의 예측변수 중 랜덤하게 m개의 변수를 뽑고 이들만 고려하여 split을 진행한다. ( 를 주로 사용한다.)
Boosting
각 트리들의 학습이 독립적으로 이루어지는 Bagging과 달리 이 전에 학습한 트리들의 정보를 이용해서 순차적으로 트리를 학습시킨다. 특히 전체 데이터셋을 사용하되, 잘못 예측된 데이터에 집중하여 반복 학습 시킨다. Boosting에는 3개의 Hyperparameter가 있다.
1. Tree의 개수 B : B가 크면 overfitting될 수 있다. cross validation을 통해 B를 선택한다.
2. Shrinkage parameter : 학습 속도를 조절. 작아지면 B가 커져야한다.
3. split 횟수 d : boosted tree의 complexity를 조절, boosting을 통해 bias를 줄이므로 d가 클 필요가 없다.
Bagging vs Boosting
느낀점 ✏️
이론 강의를 들을 때는 그렇구나,, 하면서 대충 잘 이해했다고 생각했는데 실습 강의를 듣다 보니 강의 따라서 코딩을 하니까 실제로 내가 혼자서 코딩을 직접 해보면 백지에서도 할 수 있을까? 하는 걱정이 밀려왔다. 구글 없이 코딩하는 사람이 어디 있겠냐마는 전체적인 플로우는 이해하겠지만 디테일한 파라미터나 함수들을 잘 쓸 수 있을 지 모르겠다.
