참고:
https://datascienceschool.net/02%20mathematics/03.05%20PCA.html
http://matrix.skku.ac.kr/math4ai-intro/W12/
https://ko.wikipedia.org/wiki/%EC%A3%BC%EC%84%B1%EB%B6%84_%EB%B6%84%EC%84%9D
https://darkpgmr.tistory.com/110
요약: 여러 데이터가 모인 데이터 분포가 있을 때, 그 데이터의 주 성분을 분석해 주는 기법. 주성분이란, 그 방향을 따른 데이터의 분산이 가장 큰 벡터를 의미한다. 예를 들어 타원 데이터면, 가장 긴 부분을 따른 벡터 하나, 그리고 그에 수직인 벡터 하나로 주성분이 나오게 될 것이다.
특히 데이터의 변수가 너무 많아서 분석이 어려울 때, 요소들을 하나로 합침으로써 데이터의 분포 상당수를 설명할 수 있다면 계산과 시각화가 용이하게 된다.
M차원의 데이터가 N개 있을 때, N*M으로 행렬로 표현할 수 있다.(즉, 열이 벡터)
원래 PCA는 원점을 중심으로 분포해 있을 때 전개할 수 있다. 그래서 각 열별로, 각 벡터의 평균을 빼준다. 즉
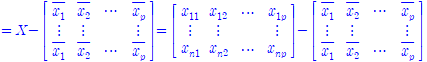
이 연산을 수행해 준다. 이를 통해 X의 열들은 평균이 모두 0이 되고, 기하학적으로 원점 중심으로 벡터들이 분포하게 된다. 이 아래로 X는 모두 위와 같은 상태라 가정한다.
이후, X에 SVD를 적용해 특잇값들을 구한다. 특잇값들을 각각 s1...sn이라고 하면,
(si)^2/n은 i번째 pc의 분산이 되며, (si)^2/(si^2들의 합)은 전체 분산 중에서 i번째 pc가 설명하는 분산의 정도를 알려준다.
따라서, 몇%까지 데이터를 남길것인지에 따라 사용하는 PC의 수가 달라진다.
아직 이해하기 어려운 개념이 많아, 이 정도로 요약하고 나중에 돌아오기로 한다. 이번학기에 선대를 수강할 수 있기를 꼭 바란다...
