참고
https://sanghyu.tistory.com/16
https://untitledtblog.tistory.com/133
https://losskatsu.github.io/machine-learning/gmm/#%EA%B0%80%EC%9A%B0%EC%8B%9C%EC%95%88-%ED%98%BC%ED%95%A9-%EB%AA%A8%EB%8D%B8-%EC%A0%95%EC%9D%98
https://www.mygreatlearning.com/blog/gaussian-mixture-model/
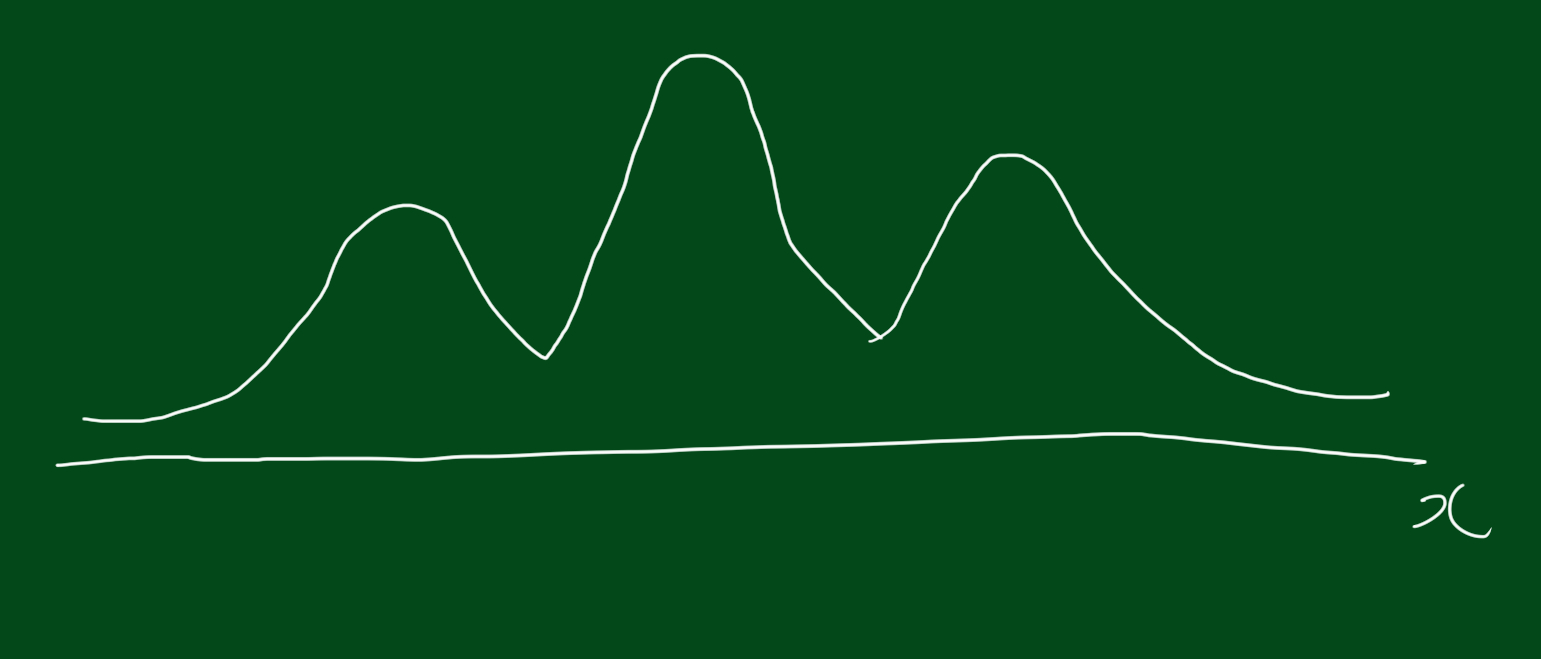
이런 식의 데이터 분포가 있다고 쳤을 때, 하나의 그룹이 있어서 그 분포를 따른다고 보는 대신, 여러개의 그룹을 쪼개 그 그룹에 확률적으로 분포한다고 보는 모형.
예를 들어, 여러번 측정을 통해 1이라는 데이터가 몇 번, 2라는 데이터가 몇번, 이런식의 데이터 분포를 해석할 때 유용하다.
K-평균 클러스터링과 마찬가지로 그룹의 수를 지정해 줘야 한다는 단점.
각 그룹의 개수마다, 3개씩의 변수 값을 계산해야 한다. 평균, 분산, 비율(데이터 중 몇 %가 해당 그룹에 속하는지)
확률 분포를 나타내는 수식은 아래와 같다.
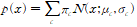
독립을 가정하지 않으면 covariance matrix를 써야 한다.
즉, x의 확률은 각 정규분포(N)에서 선택될 확률 pi를 더 더한 확률이다. 여기서 pi는 모든 그룹에 대해 합은 1이며, 모든 그룹에 대해 0이상 1이하의 값을 갖는다.
따라서 GMM에서의 학습은 pi, 평균, 분산 추정값을 고쳐나간다는 것을 의미한다. 베이즈 이론을 이용해 이를 계속 풀어나갈 것이다.
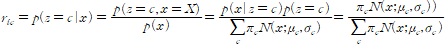
ric는 i번째 데이터가 c 그룹에 속할 확률이다. 이 확률 = x분포 이며 데이터가 c그룹일 확률/p(x) = 데이터가 c그룹일 때 p(x)데이터가 c그룹일 확률/p(x) (정규분포를 비중을 곱해 더한 식)= c그룹 정규분포서 x 확률 비중/p(x) 가 된다.
이 모델의 목적은, loglikelihood를 극대화하는 것이다. 즉, 어떤 모델에서 데이터들이 생성되었을 확률을 의미한다. 좀 더 직관적으로 데이터 셋을 생성했을 확률이 가장 높은 GMM을 찾는 것이다.
식을 보면 각 데이터셋이 생성될 확률을 모든 그룹에 대해 더해준 값에 로그를 씌우고 이걸 모든 데이터에 대해 더해주는 것.
ric를 다 계산했다면, 이제 M단계 넘어간다. k-평균 클러스터링의 EM알고리즘이다.
c집단의 데이터 수를 mc로 표현하며, 이는 위에서 계산한 ic들을 전부 더해준 값이 된다.
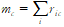
이제 처음 값들을 다시 갱신해준다. 이때 추정값은 아래 식이 된다. 구하는 방법은 라그랑주 승수법을 이용한다고 하는데 아직 공부가 안 됐다.
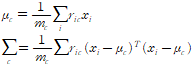
식을 보면 평균과 분산의 정의를 그대로 따른다.
loglikelihood의 수렴, 혹은 특정 횟수만큼 반복하면 가우시안 혼합 모델이 생성된다.
GMM 모델의 장점은, 각 데이터 포인트들이 어느 그룹에 속해야 하는지 같은 제약이 없다는 것이다. 또한, 자동으로 그룹에 대해 학습할 수 있다는 장점도 있다.(즉, 비지도 학습이다.)
GMM은 이런 곳에서 사용된다고 한다.
신호 처리
언어 인식
Customer Churn문제.
Anomaly detection
비디오 프레임에서 물체 인식
장르 바탕으로 음악 분류.
