
링크: 중고차 가격 예측
전처리 과정
데이터 분석
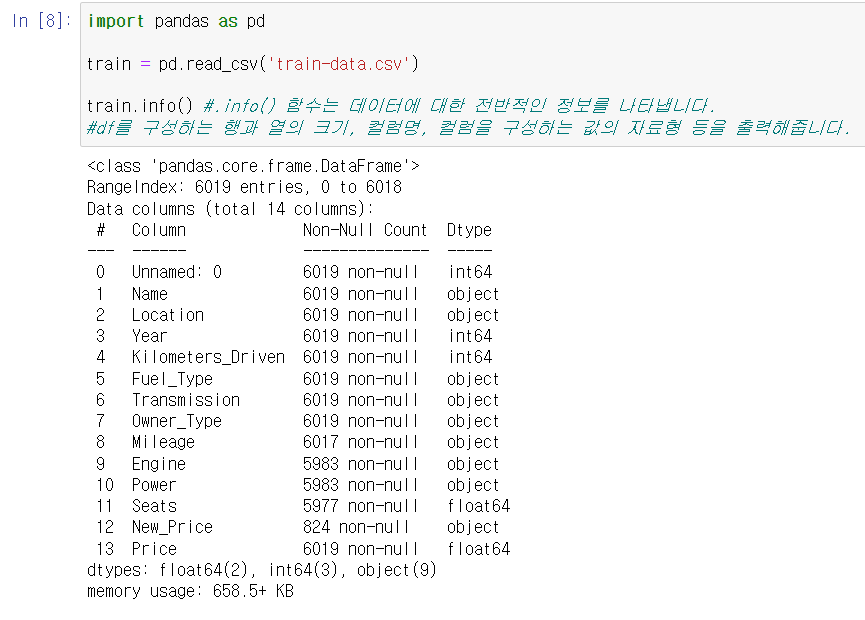
14개의 항목이 있고, 엔진 마력, 신차 가격, 좌석 수에 결측치가 있다.
8 Mileage 6017 non-null object
연비 Mileage 은 2개만 빠졌다.
9 Engine 5983 non-null object
10 Power 5983 non-null object
11 Seats 5977 non-null float64
12 New_Price 824 non-null object
신차 가격은 결측치가 많다.
13 Price 6019 non-null float64
Owner_Type 전처리 & csv 파일에서 인덱스 삭제
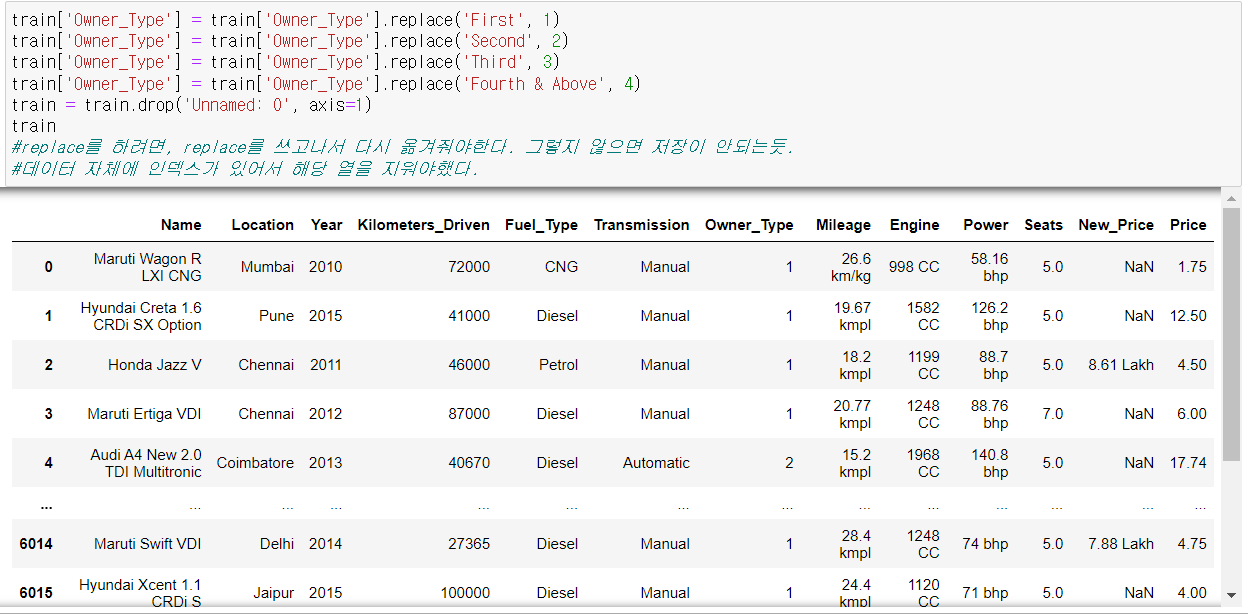
파이썬의 replace를 사용하려면, replace를 쓰고나서 해당 데이터에 replace한 데이터를 다시 입력시켜줘야한다. 그렇지 않으면 데이터에 수정된 정보가 저장이 안되기 때문이다.
그리고 csv파일 자체에 인덱스가 있어가지고 해당 열을 지웠다. (.drop)
Name 전처리

Mileage 전처리
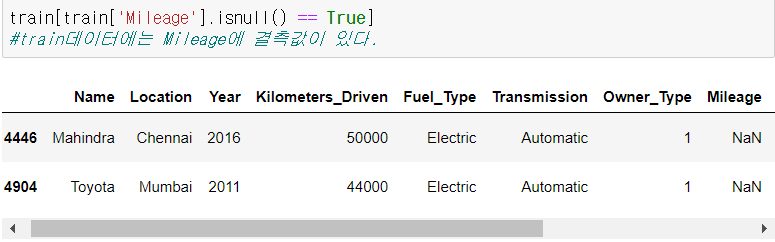
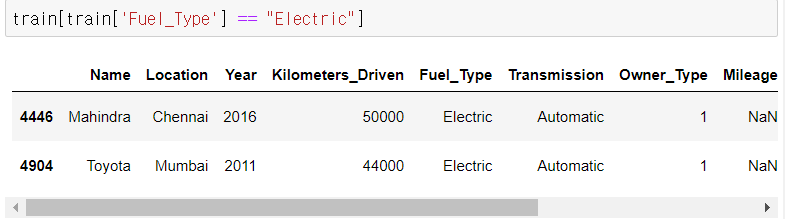
Madindra E verito D4 만이, 전기차이다.
따라서 연비가 리터당이 아니라 완충시 거리로 나오기 때문에 연비가 결측치로 나타난 것이다.

이런 경우, 데이터가 한 개뿐이라서 전체 모델에 미치는 영향은 아주 미미할 것으로 생각했다.
따라서 마힌드라 차량의 데이터는 지우기로 결정했다.
반면, 도요타 프리우스 2011년식은 29.3으로 연비가 존재한다.
따라서 이 경우에는 연비를 새로 입력해줬다.
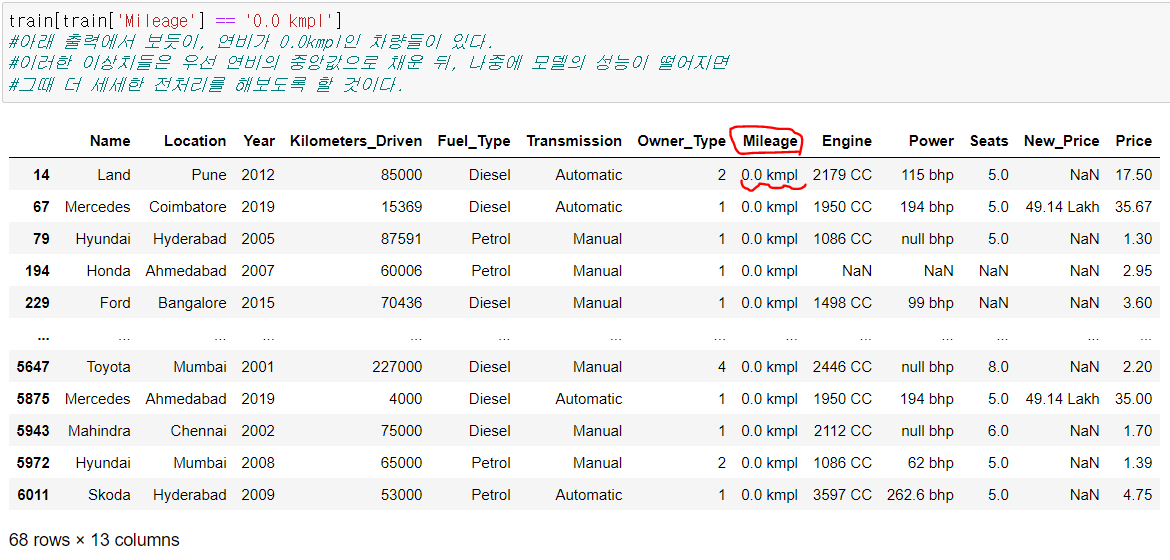
위의 출력에서 보듯이, 연비가 0.0kmpl인 차량들이 있다.
이러한 이상치들은 우선 연비의 중앙값으로 채운 뒤, 나중에 모델의 성능이 떨어지면 그때 더 세세한 전처리를 해보도록 할 것이다.

Engine 전처리
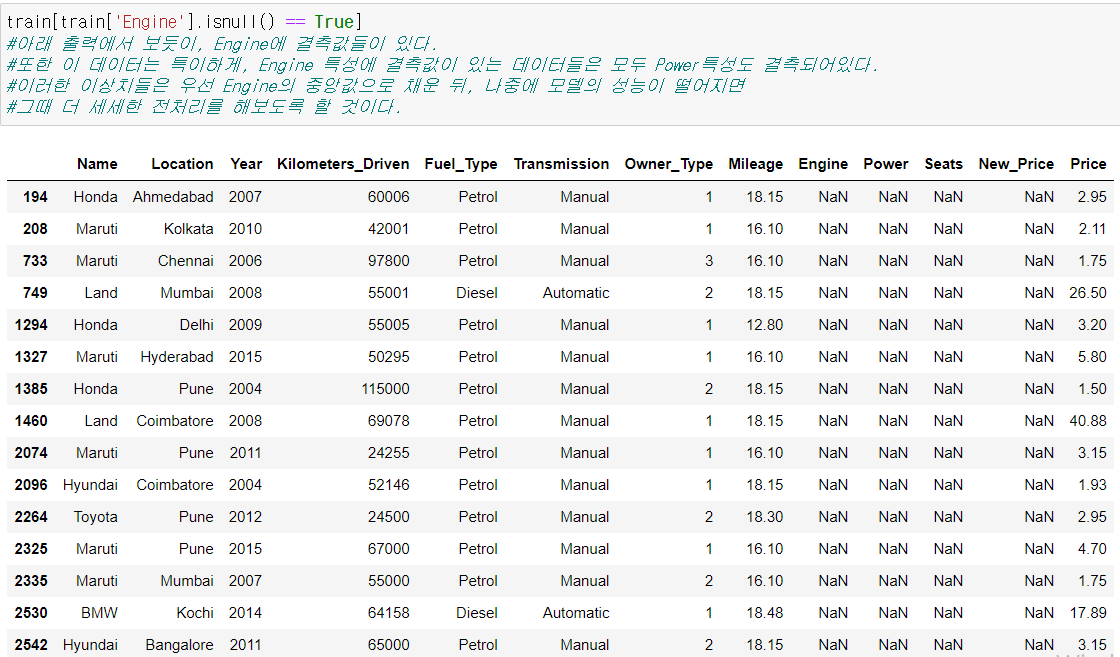
(Engine에 결측값이 있는 데이터들이 사진에서 보이는 것 이외에 훨씬 많다.)

Year, Kilometers_Driven 전처리

Kilometers_Driven이 문자열 데이터이기 때문에 float형으로 바꿔주고,
SimpleImputer를 이용해서 결측치를 중앙값으로 채운다.
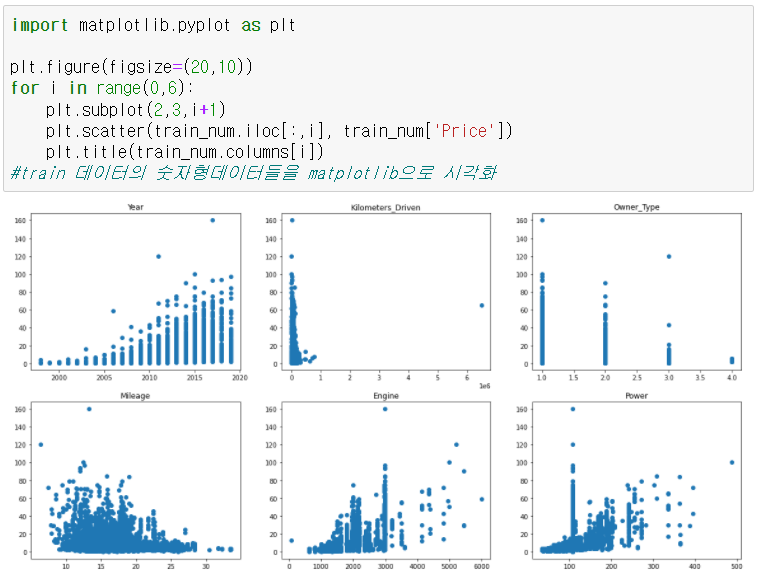
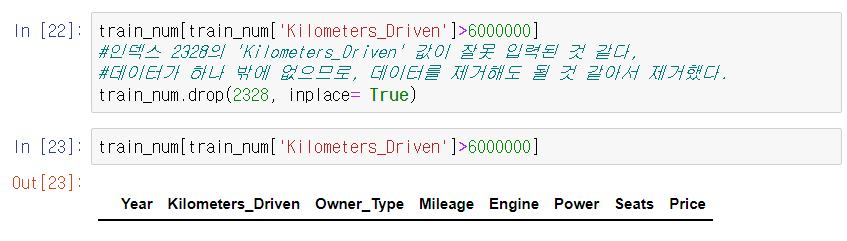
위의 사진처럼 Kilometers_Driven의 이상치를 제거한 것을 확인할 수 있다.

그래서 plot을 다시 그리면 위와 같이 되면서, 경향성을 보인다.
범주형 데이터의 처리
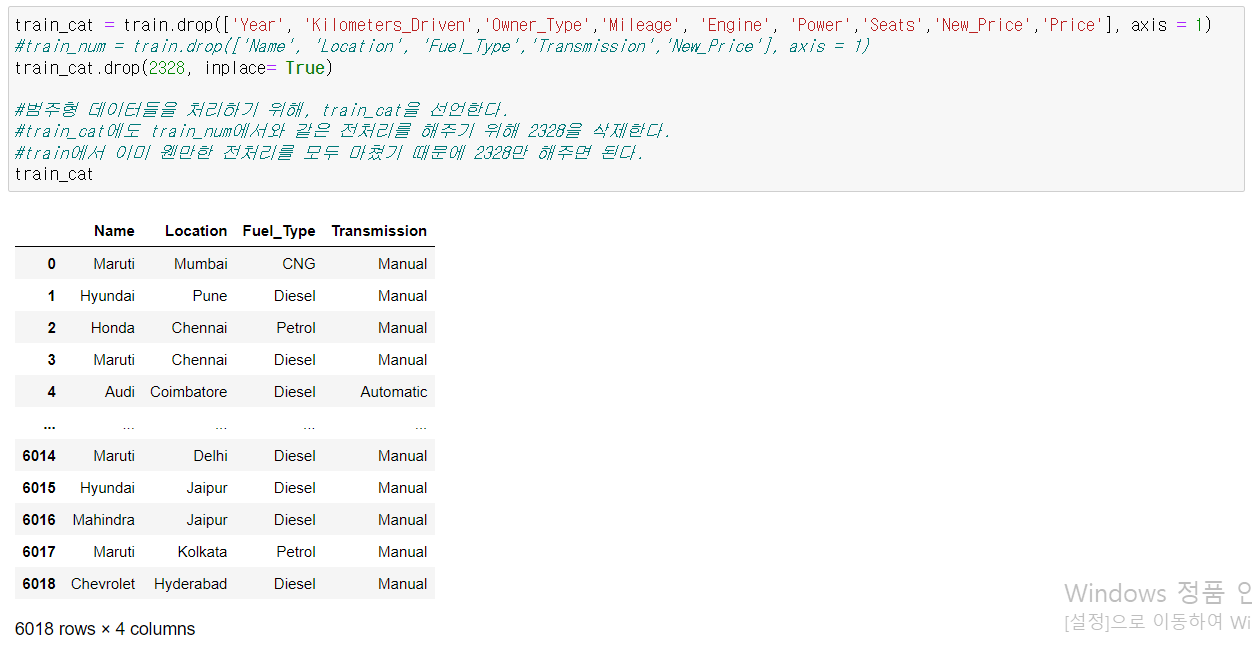

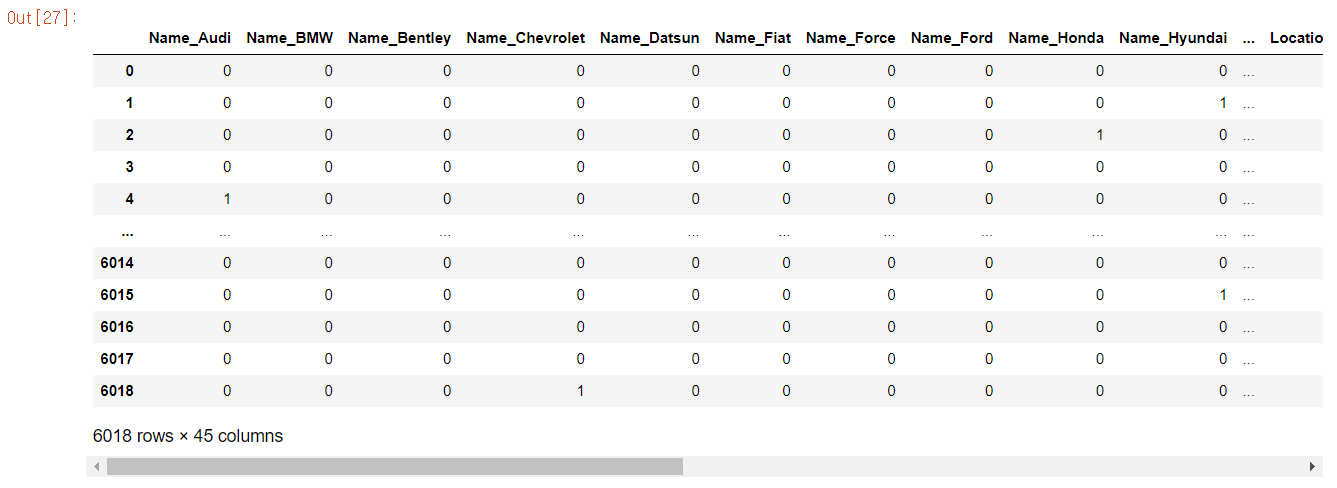
데이터 표준화
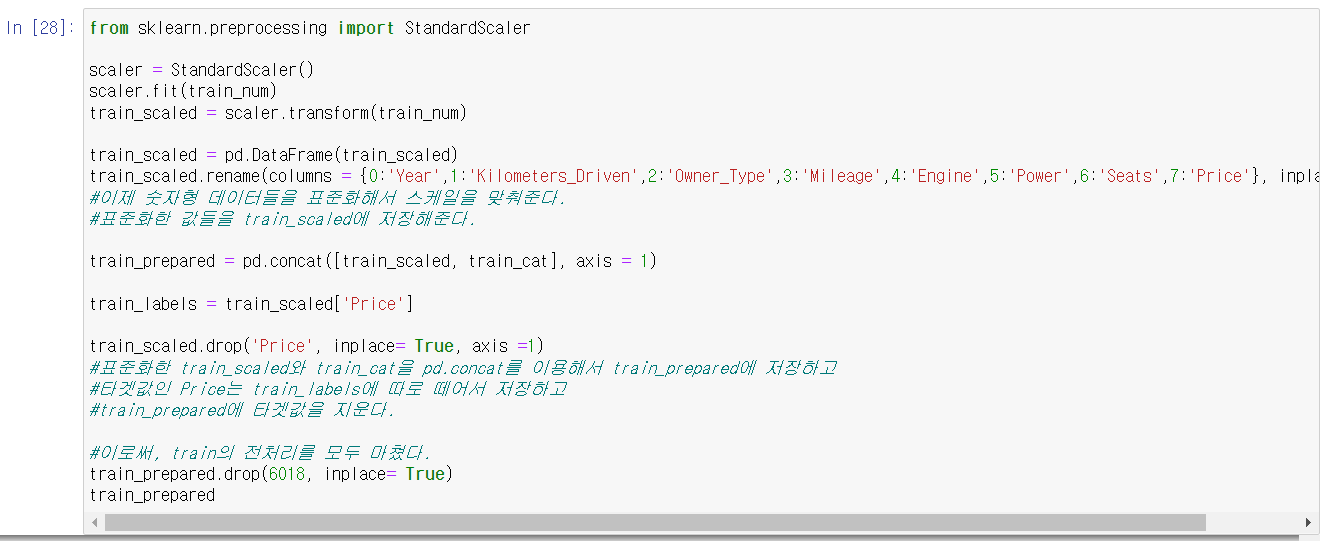
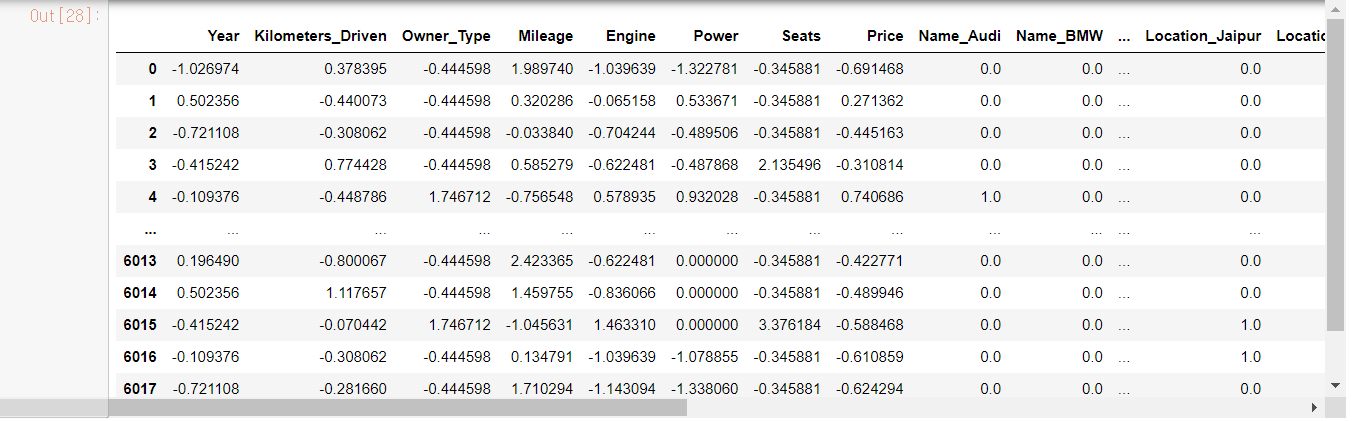
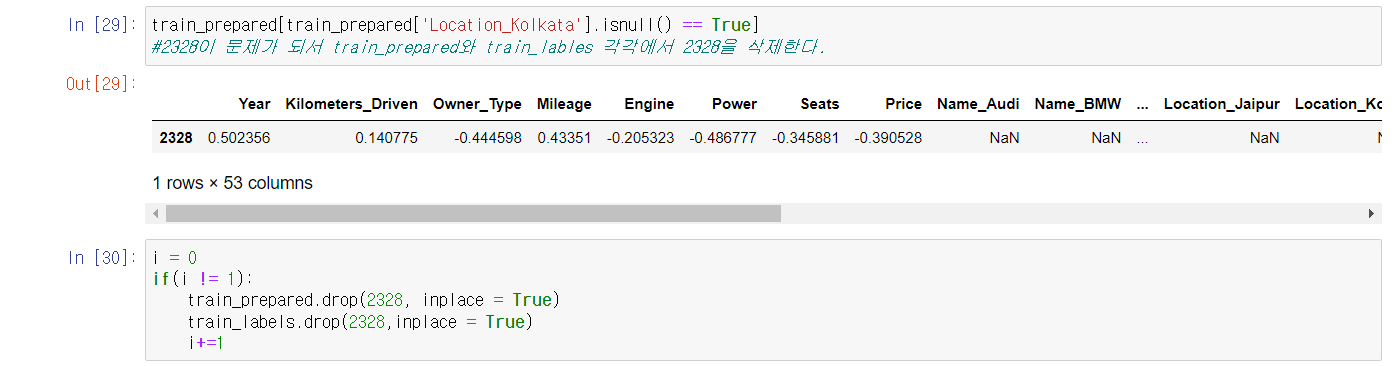
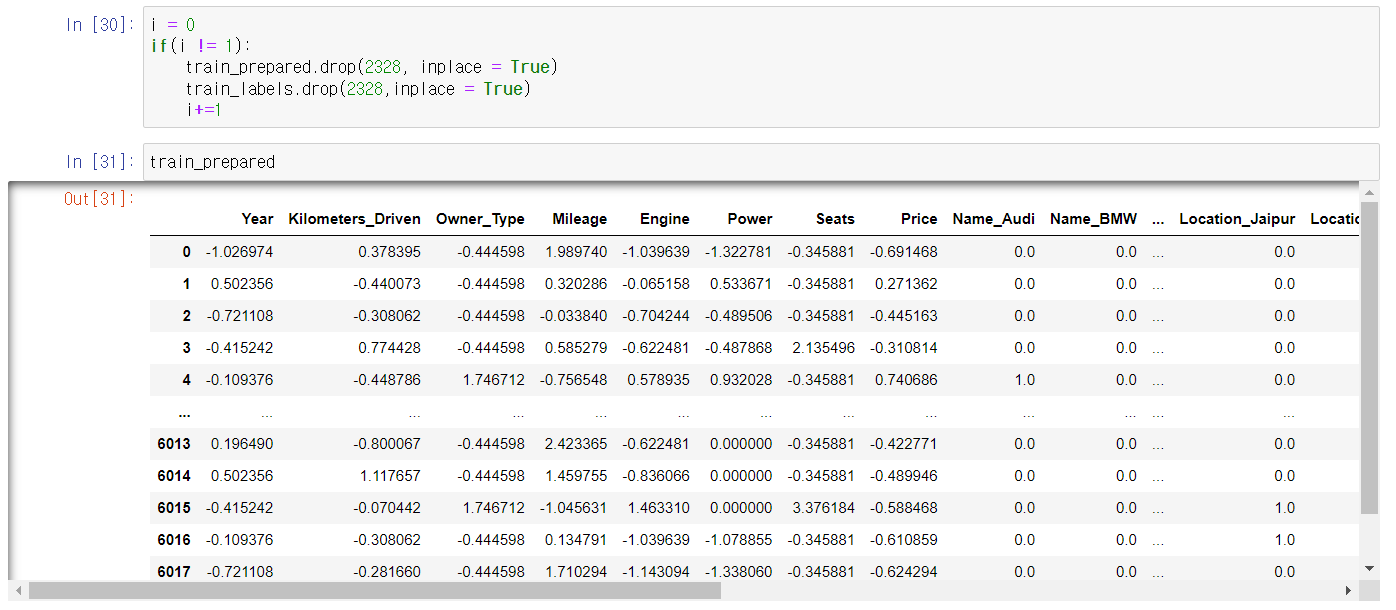
전처리 결과

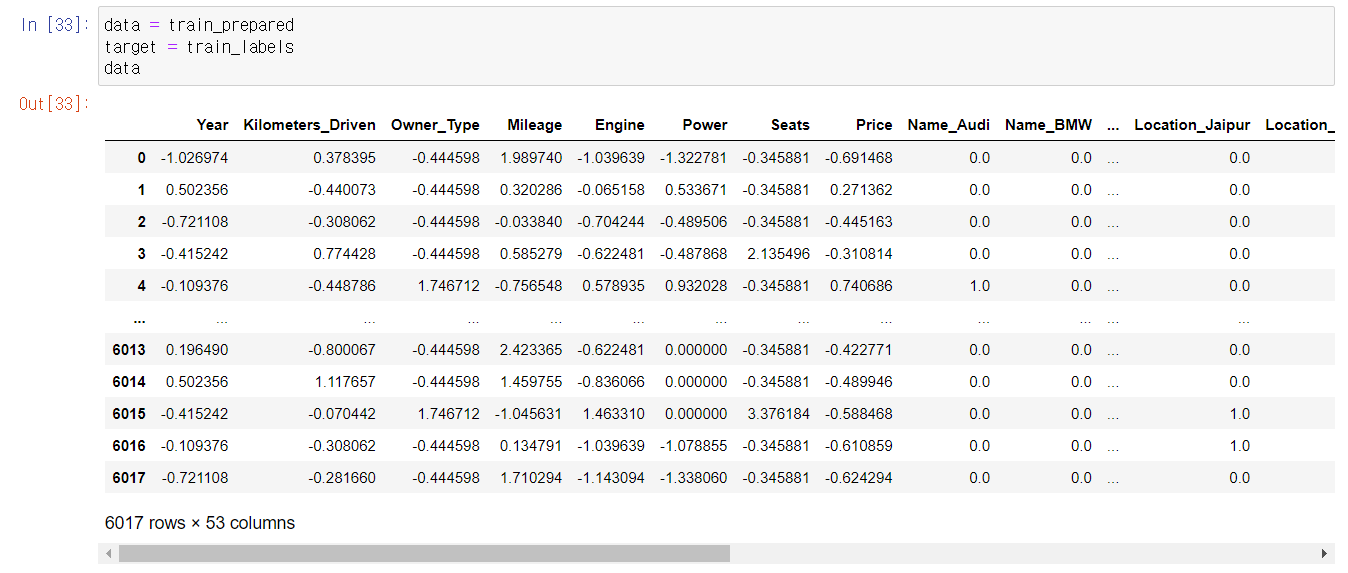
전처리된 데이터를 훈련 데이터와 테스트 데이터로 나누기

