우리는 여태까지
프로세스/스레드 -> CPU 스케쥴링 -> 동기/비동기 -> 블로킹/논블로킹
의 흐름으로 OS에 대해서 알아보았다.
이 내용들을 알고 있을 때 우리는 '멀티스레드 상태에서 CPU가 특정 변수를 동시에 수정하게되면 문제가 생기지 않는가' 하는 질문을 던져볼 수 있다.
예를 들면 이런 상황이다
만약 쇼핑몰에서 상품 데이터에 접근을 한다고 해보자.
상품 하나가 구매된다면 상품의 재고는 하나가 줄어들것이다.
그런데 사용자 2명이 동시에 상품을 하나씩 구매한다면 어떻게 될까?
우리의 생각대로라면 당연하게도 2개의 재고가 줄어드는데 맞다.
멀티 스레드를 사용하게 되면 CPU는 우리의 생각대로 행동하지 않는다. CPU는
1. 메모리에서 상품 재고 확인
2. 기존 재고에서 -1 계산
3. 재고 저장의 세가지 단계를 가지게 된다.
그런데 이때 A와 B, 두 개의 스레드가 동시에 재고에 접근하게 되면 어떻게 될까?
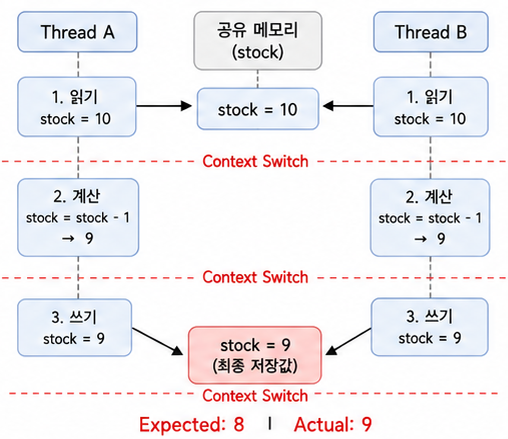
사진과 같은 단계를 거치게 되어 A와 B의 결과값은 우리가 기대하는 기존 재고 -2가 아닌 기존 재고 -1의 값을 갖게 될 것이다.
이러한 문제는 동시성 문제 라고 칭하는 것들 중 하나이다.
여기서 문제가 되는 공유 자원에 접근하는 코드 영역을 임계영역(Critical Section)이라고 칭하는데 임계영역은 동시에 여러 스레드가 실행하게되면 문제를 발생시키는 영역이다.
동시성 문제
- 멀티 스레드 환경에서는 여러 스레드가 같은 자원에 동시에 접근이 가능하다. stack을 제외하면 변수나 메모리, 파일, DB 데이터 등 여러가지 자원을 공유하고 있기 때문이다.
앞서 예시든 데이터의 일관성 문제를 가진 상태를 Race Condition(경쟁상태) 라고 한다.
Race Condition의 경우 여러 스레드가 공유 자원에 접근하여 동시에 수정하기 때문에 발생한다. 그렇다면 이외에 또 다른 문제가 있을까?
대표적으로 DeadLock과 저번에 언급되었던 Starvation이 있다.
DeadLock(교착 상태)
데드락은 서로 Lock을 잡고 기다리다가 영원히 멈추는 것을 이야기한다.
- Lock은 공유 자원에 접근할 때 다른 스레드가 접근하지 못하도록 잠그는 장치이다.
만약 자원 A와 B를 필요로하는 스레드 1과 2가 있다고 해보자.
스레드1은 자원 A를 먼저 접근하고 B를 필요로 한다.
스레드2는 자원 B를 먼저 접근하고 A를 필요로 한다.
이러한 상황에서 DeadLock은 아래와 같은 단계로 벌어지게 된다.
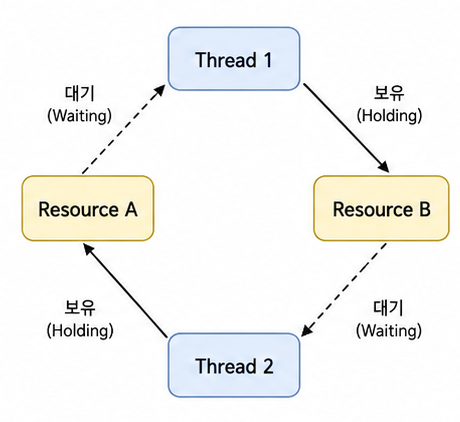
둘은 영원히 닿을 수 없는 평행 상태에서 닿고자 계속해서 뻗어가는 상태라고 볼 수 있겠다.
이러한 문제로 인해 프로그램이 멈추게 된다.
DeadLock의 경우 네가지 조건을 동시에 만족할 때 발생한다.
1. 상호 배제: 한 번에 한 프로세스만 자원을 사용하는 것.
2. 점유 대기: 자원을 점유한 채로 다른 자원을 기다리는 것.
3. 비선점: 다른 프로세스가 점유한 자원을 강제로 빼앗을 수 없는 것.
4. 순환 대기: 프로세스들이 서로 순환하며 자원을 기다리는 것.Starvation(기아 상태)
기아상태는 앞서 말했듯 계속해서 실행되지 않는 문제이다.
예를 들면, 저번시간에 이야기한 우선순위 스케쥴링에서 높은 우선순위 작업만 계속해서 실행되는 바람에 낮은 우선순위 작업은 영원히 대기될 수도 있는 경우를 뜻한다.
- 이외에도 LiveLock이나 Priority Inversion이라는 문제가 존재한다. 간략하게 설명하면 LiveLock은 서로 양보만 하다가 아무 작업도 진행이 안되는 것이며 Priority Inversion은 낮은 우선순위가 락을 잡고 있어서 높은 우선 순위 작업이 기다리는 문제이다. 이는 실시간 시스템에서 중요하다.
여러 스레드가 동시에 접근하고 실행 순서에 따라 결과가 달라지는 동시성 문제의 핵심이다.
이것을 해결하기 위해 우리는 저번 시간에 알아봤던 동기화라는 것을 통해 한 번에 하나에만 접근하게 할 수 있게 된다.
동기화 Lock기반 기법
Mutex
가장 기본적인 Lock을 활용한 동기화 기법이다.
단 하나의 키를 가지고있는 방에 접근한다고 생각을 하면 쉽다.
A라는 사람이 방에 접근한다고 해보자. 화분 밑에서 키를 가지고 방에 들어가게 된다.
그렇다면 B라는 사람은 어떻게 방에 들어갈 수 있을까?
A가 문을 열어주지 않는 이상 B는 방에 들어갈 수 없다.
이처럼 뮤텍스 기법은 Lock을 통해 오직 하나만 접근 가능한 상호 배제(Mutual Exlusion) 하는 기법이다.
그러나 스레드가 Lock을 얻지 못하면 대기상태로 들어가기 때문에 OS가 스케쥴링과 Context Switching을 수행해야한다. 이러한 이유로 Lock은 비용이 존재한다.
Semaphore
Mutex의 확장 버전이다.
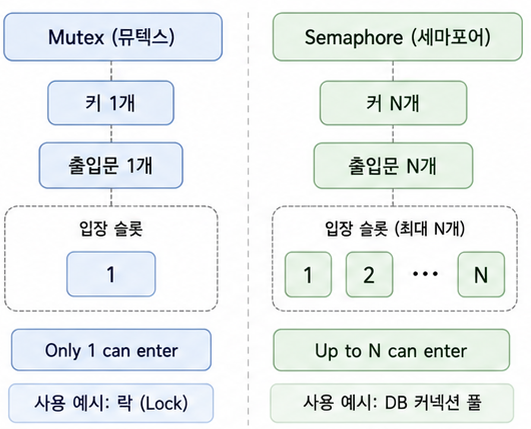
Mutex는 단 하나의 키를 가지고 있는 방이라면 Semaphore은 여러 개의 키를 가지고 있는 방이다.
Semaphore는 Binary와 Counting 방식이 있다.
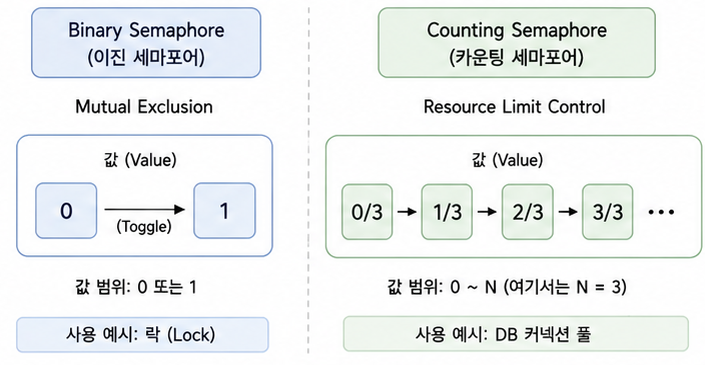
Binary 방식은 값을 0과 1만 가지고 있어 사실상 Mutex와 동일하게 동작한다.
공유 자원에 오직 하나의 스레드만 접근해야 할 때 다른 스레드를 완전히 차단하기 위해 사용된다.
Counting 방식은 값을 0부터 N까지 여러개 가질 수 있어 N개의 스레드가 동시 접근을 허용한다.
Counting 방식의 경우 DB에서 최대 연결 수를 제한하거나 스레드 풀에서 동시 실행 가능한 작업 수를 제한할 때 등에서 사용하게 된다.
- Binary Semaphore vs Mutex: Mutex는 소유권의 개념이 존재하고 Binary Semaphore은 소유권의 개념이 존재하지 않는다. 그래서 Mutex의 경우 Lock을 건 스레드가 Lock을 해제할 수 있고 Binary Semaphore의 경우 Lock을 걸지 않은 다른 스레드가 Lock을 해제할 수 있다.
- Counting Semaphore은 Mutex나 Binary Semaphore방식이 데이터 일관성을 보호하기 위한 목적을 가지고 있는 것과 달리 시스템 자원의 고갈을 방지하기 위해 사용된다. 예를들어, DB서버가 감당하지 못할 1억개의 요청이 동시에 들어오게 되면 서버는 다운된다. 그러나 DB서버가 감당할 수 있는 1000개의 요청만 먼저 처리하도록 하게 된다면 서버가 다운되지 않고 순차적으로 처리된다.
Synchronized
Java에서 가장 기본적이고 많이 사용하는 동기화 방식이다.
여러 스레드가 동시에 같은 데이터에 접근할 때, 한 번에 한 스레드만 작업하도록 막아준다.
예를 들어 은행 계좌에 동시에 입금이 일어난다고 가정해보자.
두 사람이 동시에 같은 계좌 금액을 수정하면 계산이 꼬일 수 있다.
Synchronized는 이런 상황에서 “지금 이 작업은 한 사람만 사용 가능합니다.”라고 문 앞에 잠금장치를 거는 느낌이다.
Java에서는 아래처럼 간단하게 사용할 수 있다.
public synchronized void income() {
balance += 500000;
}메서드가 실행되면 Java가 자동으로 Lock(잠금)을 걸고,
작업이 끝나면 자동으로 Lock을 해제한다.
그래서 사용법이 매우 간단하고 실수할 가능성이 적다.
다만 단점도 있다.
누군가 작업 중이면 다른 스레드는 기다려야 하기 때문에,
동시에 요청이 많아지면 성능 비용이 발생할 수 있다.
즉, 안전하지만 사람이 많아지면 줄 서서 기다리는 방식이다.
ReentrantLock
ReentrantLock도 역할 자체는 비슷하다.
여러 스레드가 동시에 데이터를 수정하지 못하도록 막는다.
하지만 Synchronized보다 조금 더 “직접 제어”하는 방식이다.
lock.lock();
try {
balance += 500000;
} finally {
lock.unlock();
}여기서는 개발자가 직접:
- Lock을 걸고
- 작업이 끝나면
- Lock을 풀어줘야 한다.
조금 더 복잡하지만 대신 기능이 더 많다.
예를 들어:
- 일정 시간만 기다렸다가 포기하기
- 먼저 기다린 스레드부터 처리하기(Fairness)
- Lock 획득 실패 시 다른 작업 수행하기
같은 고급 기능들을 지원한다.
Reentrant는 '같은 스레드가 이미 가진 Lock을 다시 획득할 수 있다'는 뜻이다.
쉽게 말하면
- 내가 이미 회의실 열쇠를 가지고 있는데
- 잠깐 다시 문을 열어도
- “너 이미 사용 중이니까 괜찮아”
라고 허용해주는 개념이다.
내부적으로는 '이 스레드가 몇 번 Lock을 걸었는지'를 숫자로 관리한다.
그리고 마지막까지 unlock 해야 완전히 해제된다.
지금까지 Lock 기반 기법을 살펴보았다. 이번엔 Lock을 사용하지 않는 방식을 알아보자.
동기화 Lock-Free기반 기법
- Atomic(원자적)
동시성 문제를 CPU 명령 자체를 원자적으로 처리하는 기법이다.
AtomicInteger count = new AtomicInteger();
count.incrementAndGet();의 형식으로 사용된다.
Atomic은 CAS(Compare And Swap)을 통해 이루어진다.
CAS는 현재 값이 내가 예상한 값이면 변경하는 형태로 동작한다.
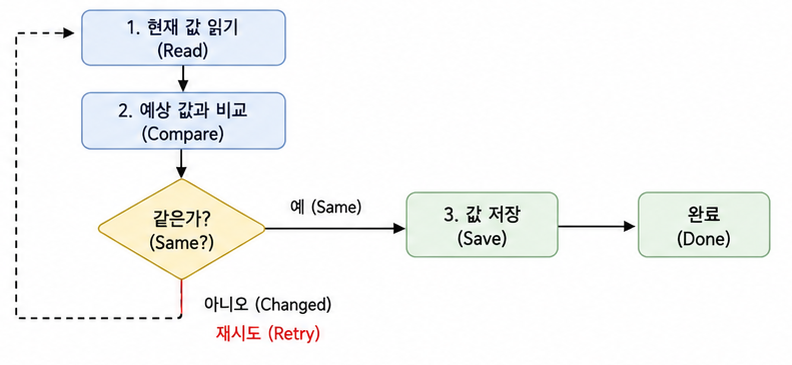
처음 들었던 예시로 보자면 아래와 같다.
1. A가 재고 확인
2. B가 재고 확인
3. A가 -1 연산
4. B가 -1 연산
5. A가 결과값을 예상 값과 비교 (맞아서 저장)
6. B가 결과값을 예상 값과 비교 (틀려서 다시 시도)
7. B가 재고 재확인
8. B가 -1 재연산
9. B가 결과값을 예상 값과 비교 (맞아서 저장)예시만 보아도 알겠지만 CAS를 사용하는 Atomic은 복잡한 작업에서는 사용하기 어려워진다. 여러 연산을 하나의 원자적 작업으로 묶기 어렵기 때문이다.
대신 Lock이 없고, Context Switching이 적으며, 빠르다는 장점을 가진다.
- Lock방식의 경우 대기상태와 컨텍스트 스위칭/스케쥴링이 계속해서 발생하고, CAS방식은 블로킹 없이 재시도하기 때문에 문맥교환 비용이 없어 빠르다.
마무리
결국 동시성 문제는 멀티 스레드 환경에서 공유 자원을 안전하게 관리하기 위한 문제이며 이를 해결하기 위해서는 Lock 기반 또는 Lock Free 기반의 다양한 동기화 기법이 사용된다.
