Attention Is All You Need 논문 출처
글 작성에 앞서 : 본 게시글은 개인 학습을 위한 것이므로 모델의 Architecuture에 관해 중점적으로 다루며, 모델의 학습 방법이나 성능에 대해서는 정리하지 않습니다.
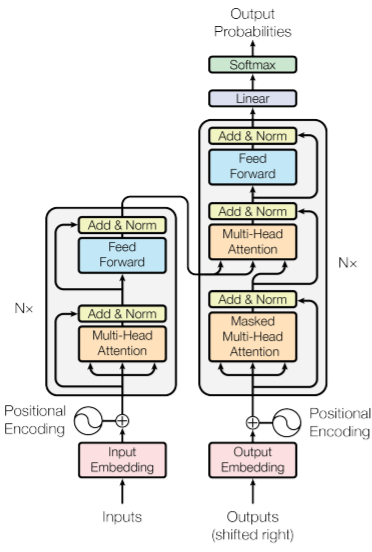
Model Architecture
Encoder
Encoder는 6개의 동일한 Layer의 stack으로 구성된다.
또한, 각 레이어는 (1) multi-head self-attention layer, (2) position-wise fully connected feed-forward layer 두 개의 sub-layer로 구성된다.
두 개의 sub-layer는 layer normalization을 거쳐 residual connection된다. 즉, 각 sublayer의 출력은 와 같이 표현된다. residual coneection을 위해 모든 sublayer의 출력은 embedding layer의 크기와 같은 512차원으로 생성된다.
Decoder
Decoder 역시 6개의 동일한 Layer의 Stack으로 구성된다.
Decoder는 Encoder의 두 가지 sub-layer 의외에도 한 가지 sub-layer를 더 가지고 있는데, 해당 sub-layer는 encoder stack의 출력에 대해 multi-head attention을 수행한다.
마찬가지로 각 sub-layer의 출력은 layer normalization을 거쳐 다음 sub-layer로 residual connection된다.
또한, self-attention sub-layer에선 특정 position 이후의 정보에 접근하지 못하도록, 즉, position 에서의 prediction은 보다 적은 값들의 output에만 의존하도록 masking을 해준다.
Attention
Attention은 query vector, key vector, value vector 쌍을 output으로 mapping하는 과정으로 정리할 수 있다.
output은 value vector 들의 가중합(weighted sum)으로 계산되며, 각 가중치는 query vector와 해당 query의 key vector로부터 계산된다.
Scaled Dot-Product Attention
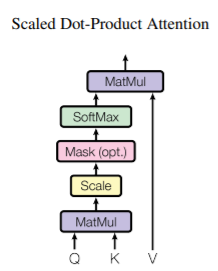
-
query vector와 모든 key vector 간의 내적(dot product)값을 구한 후, key vector의 크기의 제곱근 ()으로 나눠준다.
- 가 커질수록 weight vector의 분산이 커지기 때문에, 이를 상쇄(counteract)하기 위해 나눠준다.
-
해당 값에 softmax를 취하여 일종의 확률값으로 변환한 후, value vector와의 행렬곱을 취해준다.
실제 모델에서는 여러 개의 query가 동시에 들어가기 때문에, 해당 연산을 vector가 아니라 matrix를 기준으로 수식화하자면 다음과 같다.
Multi-Head Attention
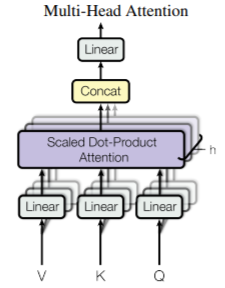
Multi-head Attention은 앞선 Scaled dot-product attention을 복수()번 수행하는 것이다. MHA를 통해 각각의 위치에서 다르게 표현된 정보들을 종합적으로(jointly) 고려할 수 있다.
Position-wise Feed-Forward Network
해당 네트워크에서는 두 번의 선형변환이 발생한다. 해당 모듈 이전의 Attention의 출력을 라고 가정했을 때, 해당 모듈의 연산을 수식으로 표현하자면 다음과 같다.
처음 선형 변환을 한 값에 ReLU를 취한 후에, 한 번 더 선형변환을 해준다.
Embeddings and Softmax
input token과 output token을 변환하는 과정에서 크기의 learned embedding을 사용한다. 또한, decoder의 output은 선형 변환과 softmax를 통해 각 token의 확률값으로 표현된다.
- input token과 output token을 변환하는 emedding layer와 decoder output에 softmax를 취하기 전의 embedding layer는 같은 건가...? (잘 모르겠습니다.)
Positional Encoding
문장은 단어의 절대적/상대적 위치에 따라서 그 의미가 변화할 수 있다. 그러나 Attention은 token sequence를 고려하지 않는다. 따라서 Positional Encoding을 통해 token sequence를 고려하도록 만들어준다.
pos는 position, i는 dimension을 의미한다.
(pos는 문장 내에 단어가 몇 번째 위치해 있는지를 의미하고, i는 해당 단어를 embedding했을 때 vector의 index로 이해했습니다만, 정확한 건 잘 모르겠습니다.)
이처럼 고정된 방법(fixed)로 positional Encoding을 하는 방법 외에도 learnable parameter로 positinal encoding을 할 수도 있으며, 두 PE는 거의 동일한(nearly identical) 결과를 보여주었다.
그러나 본 논문에서는 이처럼 파동형의 PE를 채용했는데, 학습한 데이터보다 더 길이가 긴 sequence에도 대처할 수 있을 것이라 판단했기 때문이다.
