
0. 서론
이번 주는 두 번째 프로젝트가 진행되었기 때문에, 프로젝트 후기로 주간 학습정리를 대체한다.
1. 프로젝트 목표
이번 프로젝트는 수정된 KLUE-RE 데이터셋을 활용하여 두 개체(Entity)간의 관계를 추측하는 문제(Task), 즉 관계 검출 문제(Relation Extraction)를 해결하는 것이었다.
가령, “윤동주 시인은 1917년 12월 30일 북간도 명동촌에서 태어나 1945년 2월 16일 오전 3시 36분 후쿠오카 형무소에서 옥사하였다.” 라는 문장과, “윤동주”라는 주체(subject entity), “후쿠오카 형무소”라는 객체(object entity)가 주어졌을 때, 두 개체 사이의 관계는 “사망장소(PER:place of death)”가 되는 것이다.
사실 이번 프로젝트의 목표는 광물티어에 자리매김하는 것이었다. 저번 프로젝트(마스크 이미지 분류)때 광물티어에 진입하지 못한 게 큰 한이 되었기 때문에, 브론즈라도 안착했으면 좋겠다고 생각했는데 다행히 좋은 팀원분들을 만나 개인적인 목표를 달성할 수 있었다. 그러나 처음에는 4위였는데 최종적으로 14위(private 기준)로 미끄러진 것은 큰 아쉬움이 남는다.
2. 프로젝트 참여
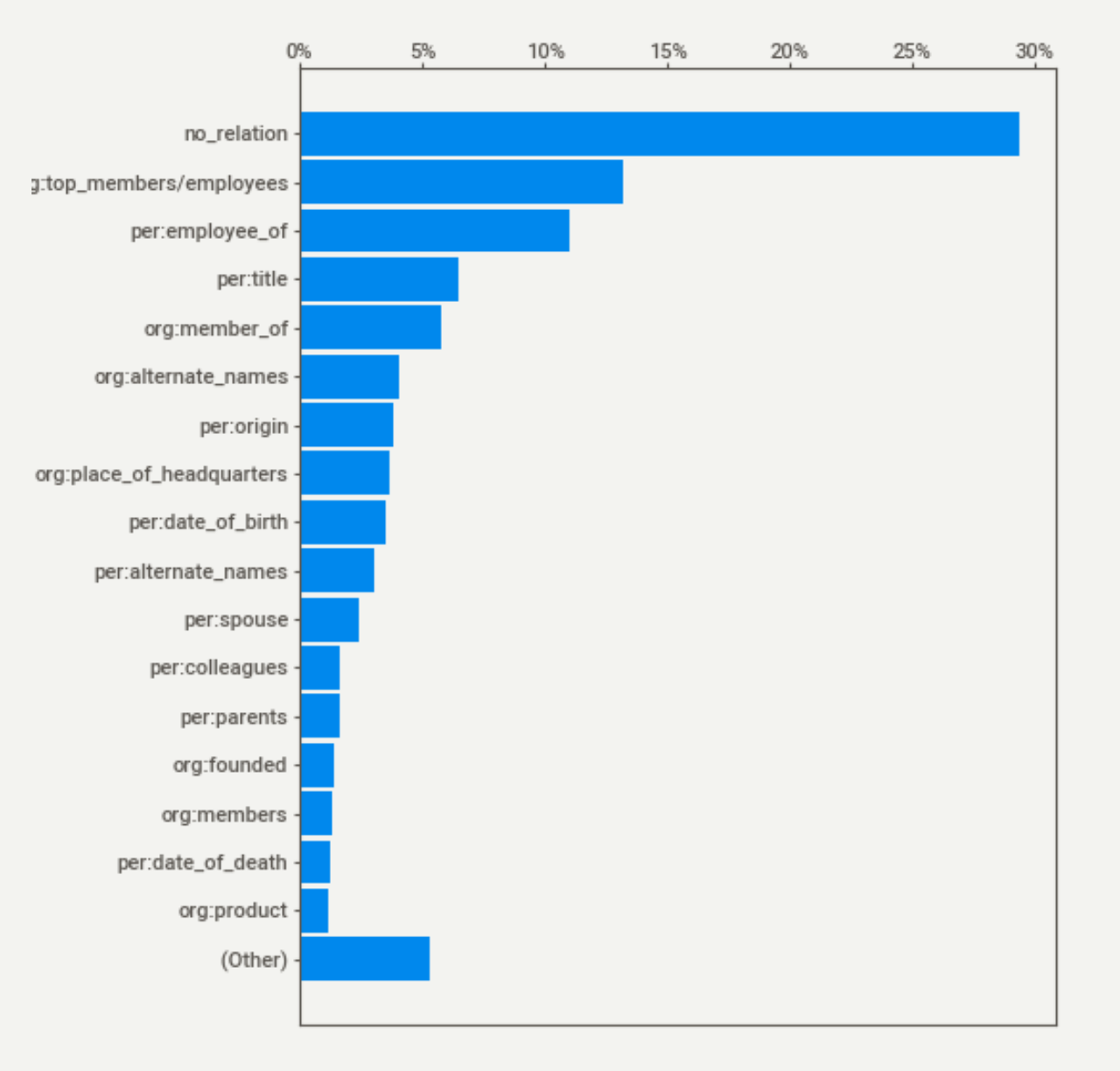
데이터셋을 살펴보면 관계 없음(no_relation)이 가장 큰 비중을 차지하는 등, 데이터 간의 분포가 상당히 불균형한 것을 확인할 수 있다. 불균형한 데이터로 학습한 모델은 결국 편향된 결과를 낳을 수밖에 없기에, 데이터간의 분포를 균등하게 하는 것과 절대적인 데이터의 양을 증가시키는 것이 우선적으로 선행되어야 한다는 것을 알 수 있었다. 따라서 “데이터 간의 불균형 문제를 해결하자!”를 1차적인 목표로 두고, 이를 해결하고 난 뒤에 모델을 돌려보기로 하였다. 데이터 간의 불균형 문제를 해결하는 방법으로는 다양한 방법이 제시되었지만, 개인적으로는 두 가지 방법을 이용하여 문제를 해결하고자 하였다.
I. 모델을 통한 데이터 증강
첫 번째는 모델을 통한 데이터 증강이었다. 앞서 언급했듯이 이번 주제는 문장과 문장 내 주체와 객체를 입력값으로 하여 두 개체 사이의 관계를 도출하는 것이다. 그러나 한 문장 내에선 여러 가지 개체가 존재한다. 가령, 앞서 언급했던 문장에서도 “윤동주”와 “형무소” 사이의 “사망장소” 이외에, “1945년 2월 16일”이라는 “사망 시간”, “북간도 명동촌”이라는 “출생장소” 등의 객체와 관계들을 도출해낼 수 있다. 즉, 주어진 개체들 말고도 문장 내에서 자체적으로 개체를 뽑아내는 과정이 필요했다.
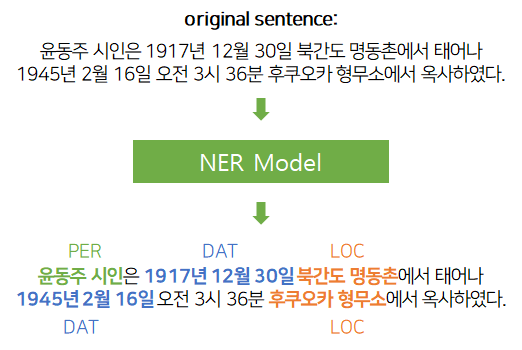
우선 사전 학습된 NER(Named entity recognition) 모델을 통해 문장 내 단어들의 타입을 매핑한 후, 이를 RE 모델에 넘겨주어 일정 확률 이상의 값을 가진 데이터들을 학습데이터로 사용하는 pseudo-labeling 작업을 진행하고자 하였다. NER 모델로는 monologg님이 제작한 KoBERT-NER 모델을 사용하였다.
원본 문장(original sentence)는 이미 "윤동주"라는 주체와 "후쿠오카 형무소"라는 객체의 타입과 위치가 있기 때문에, 원본 데이터를 통해 Fine Tuning을 진행하면 NER 모델이 "윤동주"와 "후쿠오카 형무소" 외의 다른 개체는 뽑아내지 못할 것 같아 Fine Tuning 과정은 생략했다.
결과적으로 모델이 추론한 데이터는 데이터 증강에 활용하지 못했다. 얻은 데이터들은 “윤동주” 대신 “윤동주는”, “형무소” 대신 “형무소에서” 등과 같이 조사를 포함하는 경우가 많았기 때문이다.
K-fold cross validation에서 아이디어를 차용하여 데이터의 일부는 fine-tuning에 사용하고 나머지 데이터를 inference에 사용하는 것을 K번 반복하여 데이터를 얻었으면 어땠을까 하는 아쉬움이 남는다.
II. 치환을 통한 데이터 증강
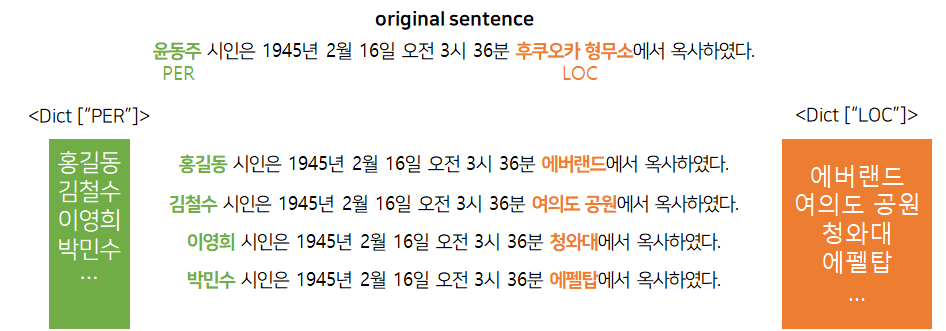
두 번째는 치환을 통한 데이터 증강이었다. 각 개체를 개체들과 타입이 일치하는 다른 단어로 바꾸는 것이다. 가령, “윤동주” 개체의 타입은 “인물(PER)”이며, “후쿠오카 형무소” 개체의 타입은 “장소(LOC)”인데, 같은 타입을 가진 다른 단어로 바꾸자면 “홍길동은 … 에버랜드에서 옥사하였다.”와 같은 문장을 만들어낼 수 있다.
물론 문장은 거짓이며 뒤에 붙는 "옥사하였다"와 호응이 되지 않지만, 문장 내 개체 사이의 관계를 판별하는 데에 문장의 참거짓은 중요하지 않다는 판단 하에 나온 생각이었다. 이를 통해 성공적으로 데이터의 양을 증가시킬 수는 있었지만, 프로젝트 마감일에 작업을 완료했기 때문에 증강된 데이터를 모델에 넣어보지 못했다.
3. 프로젝트 후기
지난 프로젝트 때 데이터 간의 불균형을 제대로 맞춰주지 못해서 모델이 특정 클래스를 제대로 구분하지 못하는 문제가 있었다. 이에 데이터 간의 불균형을 맞추는 것이 중요하다 생각했고, 해당 문제에 집중하여 프로젝트를 진행하다보니 프로젝트 전반적인 과정에 제대로 집중하지 못했다. 그러나 좋은 팀원분들이 있었기에 프로젝트를 잘 마무리 할 수 있었다. 좋게 말하자면 나는 데이터 전처리에 집중을 했고, 다른 팀원은 모델링에 집중을 한 것이기에 팀원들 간의 분업을 효율적으로 했다고 말할 수도 있겠지만, 결론적으로는 팀에 도움이 되지 못했기에 큰 아쉬움이 남는다. 목표한 대로 결과가 잘 나오지 않더라도, 프로젝트 기간에 따라 유동적으로 진행중인 작업을 포기할 수 있는 용기를 가져야겠다고 생각했다.
참조
thumbnail : https://velog.io/@oneook/썸네일-메이커Thumbnail-Maker-Toy-Project
