.png)
0. 서론
NLP 6주차부터는 RE(Relation Extraction) 프로젝트를 마감하고 새로운 프로젝트에 참가하였다.
MRC(Machine Reading Comprehension; 기계독해)는 주어진 context를 이해하고 주어진 문제를 처리하는 모델을 만드는 기술이다. 이 중에서 ODQA(Open Domain Question and answering)는 문제(query)가 주어졌을 때, 문제에 대한 답을 구할 수 있는 context를 찾고(retrieve) 이에 대한 답을 구하는(reader) 문제이다.
따라서 NLP 6주차는 MRC와 관련된 강의를 다루며 이를 중심으로 학습정리를 전개한다. 또한, 이전 강의들과 겹치는 부분은 생략하고 새로운 부분을 위주로 학습정리를 진행한다.
1. 학습정리
I. MRC Intro
MRC(기계독해)는 주어진 지문을 이해하고, 주어진 질의의 답변을 추론하는 문제다. 가령, 구글에 "아이유의 생일은 언제인가"라고 물어봤을 때 "1993년 5월 16일"이라고 결과를 보여주는 것이 예시라고 할 수 있다.
MRC 문제 내에서도 다양한 소분류가 존재한다.
- Extractive Answer Datasets
- 문제(query)에 대한 답이 항상 지문(context)의 내부에 존재
- SQuAD, KorQuAD, NewsQA 등
- Descriptive / Narrative Answer Datasets
- 답이 지문 내에서 추출한 것이 아니라, 질의를 보고 생성된 문장의 형태
- MS MARCO, Narrative QA 등
- Multiple-choice Datasets
- 질의에 대한 답을 여러 개의 answer candidates 중 하나로 고르는 형태
- MCTest, RACE, ARC 등
i. challenges in MRC
MRC 문제를 풀다보면 다양한 어려움에 직면하게 된다. 좋은 MRC 모델은 다음과 같은 문제를 효율적으로 해결할 수 있어야 한다.
-
Paraphrasing
아인슈타인은 대동맥 파열에 의한 치료를 거부하다 세상을 떠났다.
아인슈타인이 사망했다.
두 문장의 단어의 구성은 유사하지 않지만, 아인슈타인의 사망이라는 동일한 의미를 전달한다. 좋은 모델은 동일한 의미의 문장들을 이해할 수 있어야 한다.
-
coreference resolution
축구는 구기종목의 일종이다. 박지성은 그 운동을 잘한다.
만약 박지성은 어떤 운동을 잘하는가?라는 질문이 주어졌다고 가정하자. 두 번째 문장만 보았을 때 박지성은 그 운동을 잘한다는 것을 확인할 수 있다. 좋은 모델은 그 운동이 축구라는 사실을 유추할 수 있어야 한다.
-
unanswerable questions
루이비통은 프랑스의 패션 디자이너로 명품 브랜드 루이비통의 창업자이다.
만약 구찌(Gucci)의 창업자는 누구인가?라는 질문이 주어졌다고 가정하자. 보통의 모델은 창업자라는 단어에 집중하여 루이비통이라는 정답을 내놓을 수 있지만, 위 질문에 대한 답은 앞선 문맥에서 찾을 수 없다. 좋은 모델은 대답할 수 없는 질문에 대해서는 대답할 수 없다고 할 수 있어야 한다.
- Multi-hop reasoning
부평은 인천의 한 행정구역이다.
인천은 대한민국의 광역시다.
대한민국은 아시아 동북부에 위치하고 있다.
만약 부평은 어느 대륙에 위치해있는가?라는 질문이 주여졌을 때, 아시아라는 대답을 하기 위해선 앞선 세 개의 context를 모두 확인해보아야 한다. 좋은 모델은 여러 개의 context를 경유해서라도 옳은 답을 찾을 수 있어야 한다.
II. Extraction-based MRC
i. Metrics
Extraction-based MRC는 크게 두 가지의 지표, (1)EM과 (2)F1 score로 평가된다.
- EM (Exact Match)
예측값과 정답이 완전히 일치했을 때 1점. (한 글자라도 틀렸을 때 0점)
- F1 Score
예측값과 정답이 겹치는 비율을 계산하여, 0~1점 사이의 값으로 표현됨

- precision : num(same_tokens) / num(pred_tokens)
- recall : num(same_tokens) / num(ground_tokens)
- F1-score : 2*precision*recalls / precision + recall
ii. post-processing
- 불가능한 답 제거
End index가Start Index보다 앞서있는 경우 candidate list에서 제거- 예측한 위치가 context를 벗어난 경우 제거
- 사전 설정한
max_answer_length보다 길이가 길 경우 제거
- 최적의 답안 찾기
- start/end position prediction에서 score가 가장 높은 N개를 각각 선정
- 불가능한 start/end 조합 제거
- 가능한 조합 중, score의 합이 큰 순서대로 정렬하여 가장 큰 조합을 최종 결과로 선정
- 만약 Top-K가 필요한 경우 순서대로 선정
III. Passage Retrieval
Passage Retrieval은 질문에 가장 적절한 문서를 찾는 작업이다. 가령 손흥민은 어디서 태어났는가?라는 질의가 주어졌을 때, 이와 가장 관련된 문서는 손흥민에 관한 문서일 것이다.

Query와 Passage를 각각 임베딩한 후에, 두 임베팅 벡터 사이의 거리(혹은 유사도)를 계산한 값이 가장 가까운(가장 큰) 문서를 선정하는 것으로 진행된다. 임베딩 벡터를 도출하는 과정은 Sparse Embedding과 Dense Embedding, 크게 두 가지가 있다.
i. Sparse Embedding
Sparse Embedding은 텍스트 내에서 특정 단어가 몇 번 나왔는지를 고려하여 Embedding하는 방법이다. (1) 공통부분(Overlap)을 정확하게 잡아내야 할 때 유용하지만, (2) 의미가 비슷한 다른 단어를 비교하지 못하며 (3) 등장 단어가 많아질수록 Embedding Vector의 크기가 커진다는 단점이 있다. 대표적인 예로 TF-IDF(Term Frequency - Inverse Document Frequency) 가 있다.
- TF-IDF
TF-IDF는 로 계산된다.
TF(Term Frequency)는 단어의 등장 빈도를 의미한다. 단순하게 단어 하나하나를 세는 방법(raw count)도 있지만, 문서의 길이를 고려하여 전체 단어로 나눌 수도 있다. 한 문서()에 특정 단어()가 많이 나올 수록 TF는 커진다.
IDF(Inverse Document Frequency는 단어가 가진 정보량을 의미한다. 가령, a나 the같은 관사는 문맥에 수도 없이 등장하는데, 실질적으로 이 단어들이 가지는 의미는 크지 않다. 즉, 단어가 가진 정보량은 등장 횟수에 반비례한다는 것이다. 위 식에서 DF(Document Frequency)는 특정 단어가 나온 document의 개수, N은 전체 document 개수를 의미한다. 특정 단어가 여러 문서에 걸쳐 나올수록 IDF는 작아진다.
어떤 질의()와 가장 관련이 깊은 문서()를 sparse embedding을 통해 구할 때의 식은 다음과 같다.
ii. Dense Embedding
Dense Embedding은 Sparse Embedding을 보완하기 위해 고안된 방법으로, Sparse Embedding보다 더 적은 차원의 고밀도 벡터를 통해 단어를 표현하는 방식이다. Sparse Embedding의 단점인 단어의 유사성 파악이 불가능하다는 점을 극복했지만, 중요한 단어들이 정확히 일치해야 하는 경우에는 그 성능이 떨어진다는 단점이 있다. 또한, Dense Embedding은 임베딩이 구축된 후에도 추가적인 학습이 가능하다는 장점을 가지고 있다.
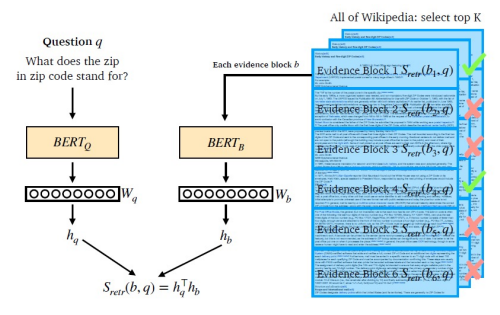
기본적인 구조는 Sparse Embedding과 유사하다. 질의와 문서 둘의 임베딩 벡터를 구한 후 내적을 통해 유사도를 구하는 것인데, 차이가 있다면 임베딩 벡터를 학습을 통하여 구한다는 것이다. 위 사진은 BERT 언어 사전학습 모델을 통해 임베딩 벡터를 구하는 예시다. 이 때, 임베딩 벡터는 [CLS] token의 출력값을 사용한다.
- Negative Sampling
BERT를 Dense Embedding Encoder로 사용할 때, 목적은 "연관된 질의와 문서의 거리를 줄이는 것"이다. 이는 즉 "관련없는 질의와 문서의 거리를 늘리는 것"으로 볼 수도 있다. 이에 착안하여, 관련없는 질의와 문서쌍(Negative sample) 역시 BERT 학습 데이터에 포함하여, Loss를 늘리는 방식으로 학습할 수도 있다.
Negative Sample은 (1) Corpus 내에서 무작위로 추출할 수 있으며, (2) 높은 유사도(e.g. TF-IDF)를 가지지만 정답과 관련없는 샘플을 뽑을 수도 있다.
IV. Scaling UP
앞선 방법에서 소개했듯이, Retrieval 과정은 Embedded Query Vector와 가장 유사한 Embedded document vector를 구하는 것으로 요약할 수 있다. 그러나 문서가 개수가 수백만, 수천만 개가 된다면 내적값을 구하는 것만으로 엄청난 시간이 소요될 것이다.
i. compression
compression(압축)은 embedding vector를 압축하는 것으로, 하나의 vector가 적은 용량을 차지하도록 하는 방법이다. 압축의 정도가 클수록 (1) 메모리 효율은 증가하고 (2) 연산량이 줄어 계산의 속도는 빨라지겠지만, (3) 정보 손실로 이어질 수 있다.
ii. Pruning
Pruning은 Search space를 줄여 검색속도를 증가시키는 방법이다.
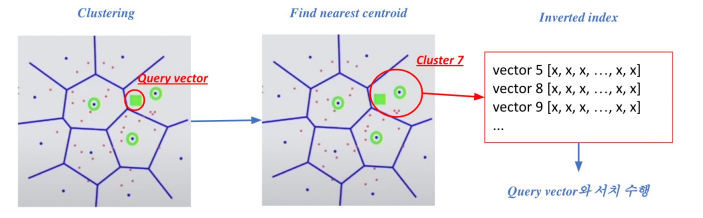
우선, Document Vector를 군집화(e.g. K-means Clustering)하여 군집을 생성한 후, Query Vector가 속하는 군집 내의 document vector들에 대해서만 내적을 구하는 방법이다.
위 두 가지 방법론은 FAISS Library를 통해 효율적으로 구현할 수 있다.
FAISS github : https://github.com/facebookresearch/faiss
2. 피어세션
- 전처리 과정에서 어떤 문자를 지우고, 어떤 문자를 남길지에 대한 토론이 성공적으로 진행되었다.
- !/~-.+“”%°〈〉<><>・「」≪≫·《》‘’『』"{}'_ :(),
- CNN 기반 모델에 관한 리서치도 진행되는 중
- SpanBERT 모델이 MRC 문제를 푸는 것과 유사하게 학습한다는 것에 기반하여 SpanBERT에 관한 노력도 진행되는 중
3. 회고
강의를 듣느라 베이스라인 코드를 온전히 이해하지 못했다. 베이스라인 코드 Retrieval.py가 Sparse Embedding을 기준으로 작성이 되어 있는데, query가 document 내에 span으로 존재하는 것이 아닌 만큼, 본 스크립트 파일을 온전히 이해하고 Dense Embedding으로 바꾸는 작업을 우선적으로 실행해볼 계획이다.
