비지도 학습 (Unsupervised Learning) 이란?
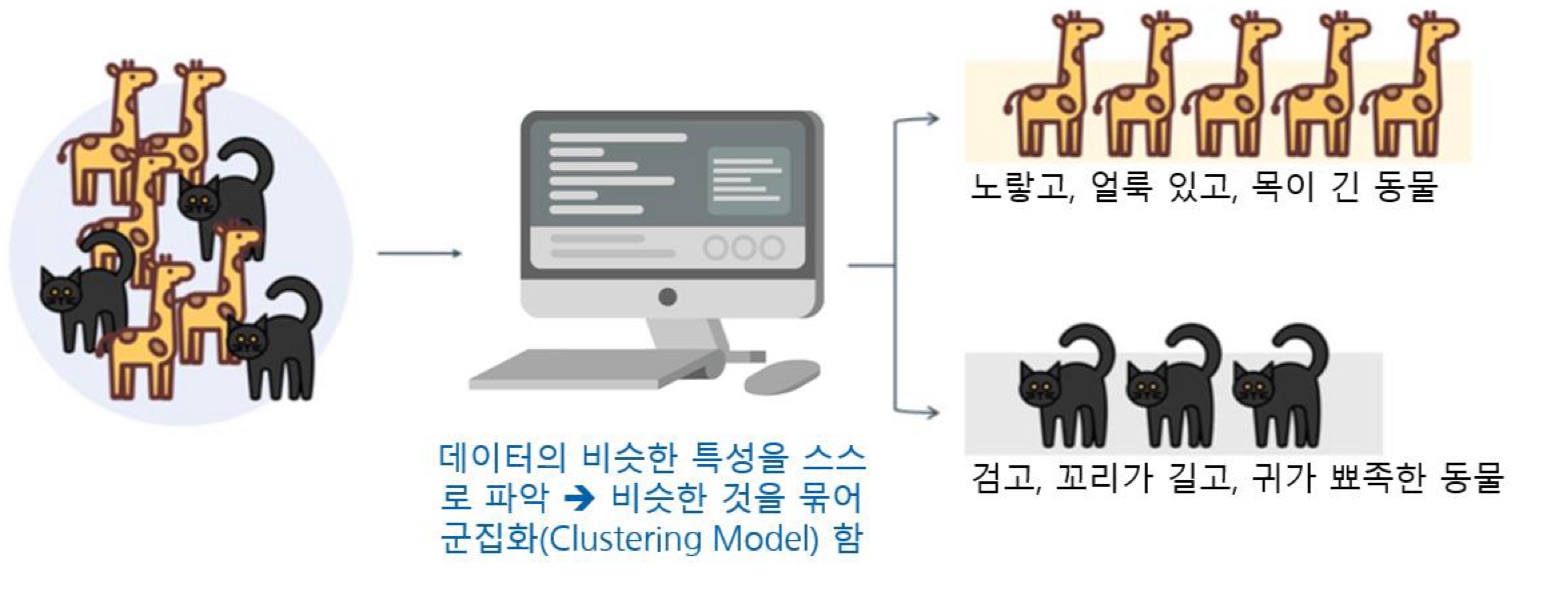
정답(라벨)을 알려주지 않고 학습시키는 방법으로,
컴퓨터가 라벨이 없는 데이터를 바탕으로 스스로 구조나 패턴을 찾아내고,
데이터의 고유한 특성을 기준으로 그룹(군집)으로 분류하는 방식이다.
비지도 학습 과정
- 라벨이 없는 데이터만 제공한다.
- 컴퓨터에게 "몇 개의 그룹으로 나눠보라"고 지시한다.
- 컴퓨터는 데이터 간의 유사도를 기준으로 그룹화한다.
- 그룹 간의 거리가 멀수록 유사도는 낮다.
대표 알고리즘
-
K-Means Clustering
데이터를 K개의 그룹으로 나누는 가장 대표적인 알고리즘.
각 데이터는 가장 가까운 중심점(centroid)에 할당된다. -
계층적 군집화 (Hierarchical Clustering)
데이터 간 거리를 기반으로 트리 구조 형태의 군집을 형성.
시각적으로는 덴드로그램(dendrogram)으로 표현 가능. -
DBSCAN
밀도 기반 군집화 방식. 밀집된 영역만 군집으로 인식하며,
밀도가 낮은 이상치(노이즈)는 군집에서 제외된다.
비지도 학습 활용 사례
-
고객 세분화 (Customer Segmentation)
쇼핑몰 고객의 구매 성향이나 행동 데이터를 분석해 유사한 그룹으로 분류 -
이상 탐지 (Anomaly Detection)
정상 패턴에서 벗어난 데이터를 감지하여 사기 거래, 시스템 오류 등을 탐지 -
문서 분류 및 주제 추출
뉴스 기사, 리뷰 등 라벨이 없는 문서 데이터를 자동으로 주제별로 군집화
지도 학습 vs 비지도 학습 비교
| 항목 | 지도 학습 (Supervised) | 비지도 학습 (Unsupervised) |
|---|---|---|
| 데이터 | 정답(라벨)이 있는 데이터 | 라벨이 없는 데이터 |
| 목적 | 예측, 분류 | 구조 탐색, 군집화 |
| 대표 알고리즘 | 회귀, 분류 (SVM, Decision Tree 등) | K-Means, DBSCAN, PCA 등 |
| 예시 | 스팸 메일 분류, 고양이/강아지 분류 | 고객 세그먼트 분류, 뉴스 주제 자동 분류 |

신우주