TREE는 아래와 같은 요소로 구성된다.
Node, Edge (간선), Root Node, Leaf Node (단말 노드), Internal Node (루트 노드와 단말 노드가 아닌 노드)
Tree의 특징으로는 다음 3가지가 있다.
- 서로 다른 임의의 두 노드를 연결하는 간선은 유일해야한다.
- 사이클을 가지는 노드 집합은 존재할 수 없다.
- 반드시 한 개의 루트 노드를 가져야한다. (이 때, 루트 노드는 부모 노드가 존재하지 않는 노드)
크게 tree의 종류를 두 가지로 나눈다면, binary tree와 non-binary tree가 존재한다. binary tree는 각 노드가 두개 이하의 자식 노드를 가지는 구조이고, non-binary trees는 자식 노드 개수에 제한이 없는 구조다.
Non-binary tree
자식 개수에 제한이 없는 tree이다. 가장 대표적인 예는 TRIE 자료구조이다.
TRIE 자료구조란 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태 자료구조이다.
예시
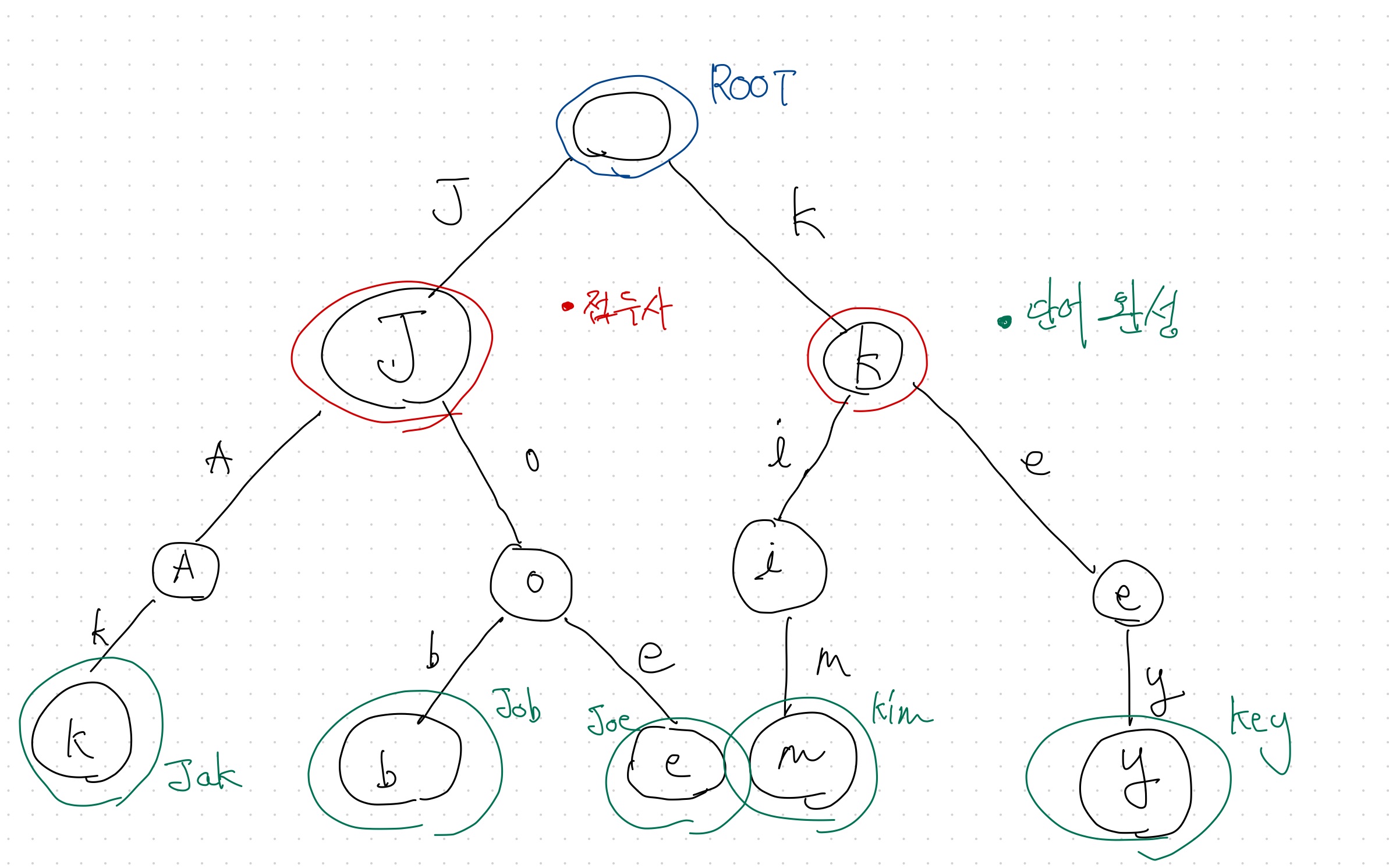
구조를 살펴보자. 루트 노드에는 비어 있다. 루트 노드의 자식 노드들은 단어의 접두사가 된다. 접두사 뒤의 문자는 자식 노드가 되면서 마지막에 leaf node (단말 노드)는 해당 단어의 마지막 문자가 된다. 각 노드는 하나의 단어를 구성하지 않고 루트 노드부터 조건에 따라 단말 노드까지 순회하였을 때 원하는 단어를 찾을 수 있다.
제일 긴 문자열의 길이 : L
총 문자열의 개수 : M
검색 시에는 최대 O(L)의 시간 복잡도가 소요된다. 공간 복잡도는 최악의 경우 O(M*L)이다.
그러면 왜 trie 자료구조를 사용할까?
db에 회원 이름을 저장한다 생각하자. 가장 간단한 방법은 2차원 배열로 [index][name] 형태일 것이다. 위 경우 검색 시 최대 O(M*L)dml 시간 복잡도를 가지는데, 위의 trie 구조와 비교했을 때 매우 비효율적임을 확인할 수 있다.
하지만 실서비스 사용은 아직 제한적이다. 아래의 문제들의 해결이 필요하다.
1. lock없이 동시에 검색 조회
2. 조회 기능 차단 없이 노드를 동적으로 추가
아래 문제를 trie 자료구조를 사용하여 해결할 수 있다.
https://www.acmicpc.net/problem/5052
binary tree
binary-search tree
간단히 왼쪽 자식 노드는 부모 노드보다 작은 값을 가지고 오른쪽 자식 노드는 부모 노드보다 큰 값을 가지는 형태의 이진 트리이다.
자료 입력 및 삭제, 탐색 모두 시간 복잡도 O(log N)이다.
하지만 bst는 입력에 따라 skewed tree (편향 트리)가 될 수 있다. 예를 들어 dataset이 오름차순으로 정렬되어있으면 시간 복잡도가 O(N)까지 증가
그래서 balance가 필요함 -> 대표적인 예가 Red-Black Tree
stl의 Map에도 사용됨
특징 : tree의 높이가 log n에 수렴한다.

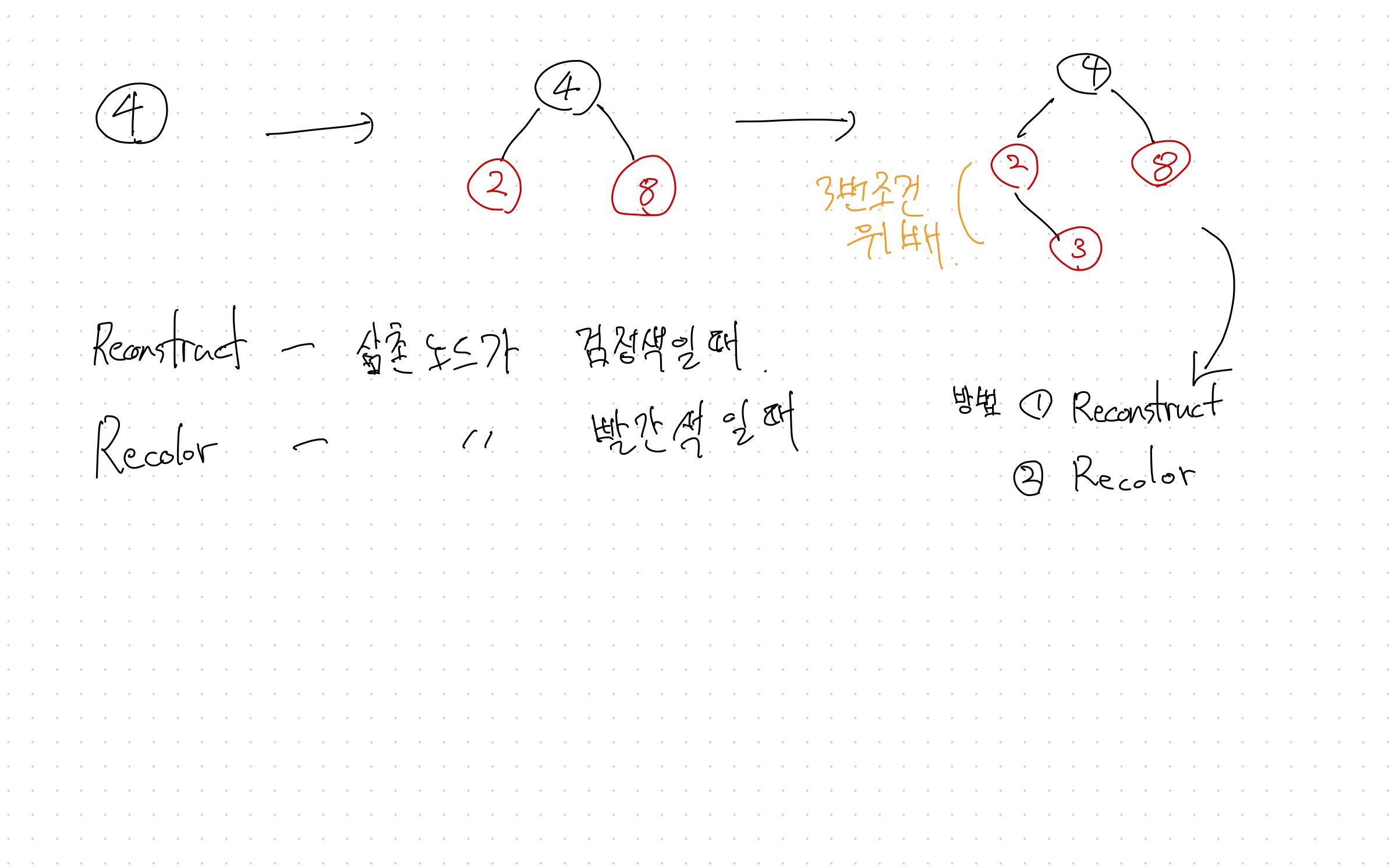
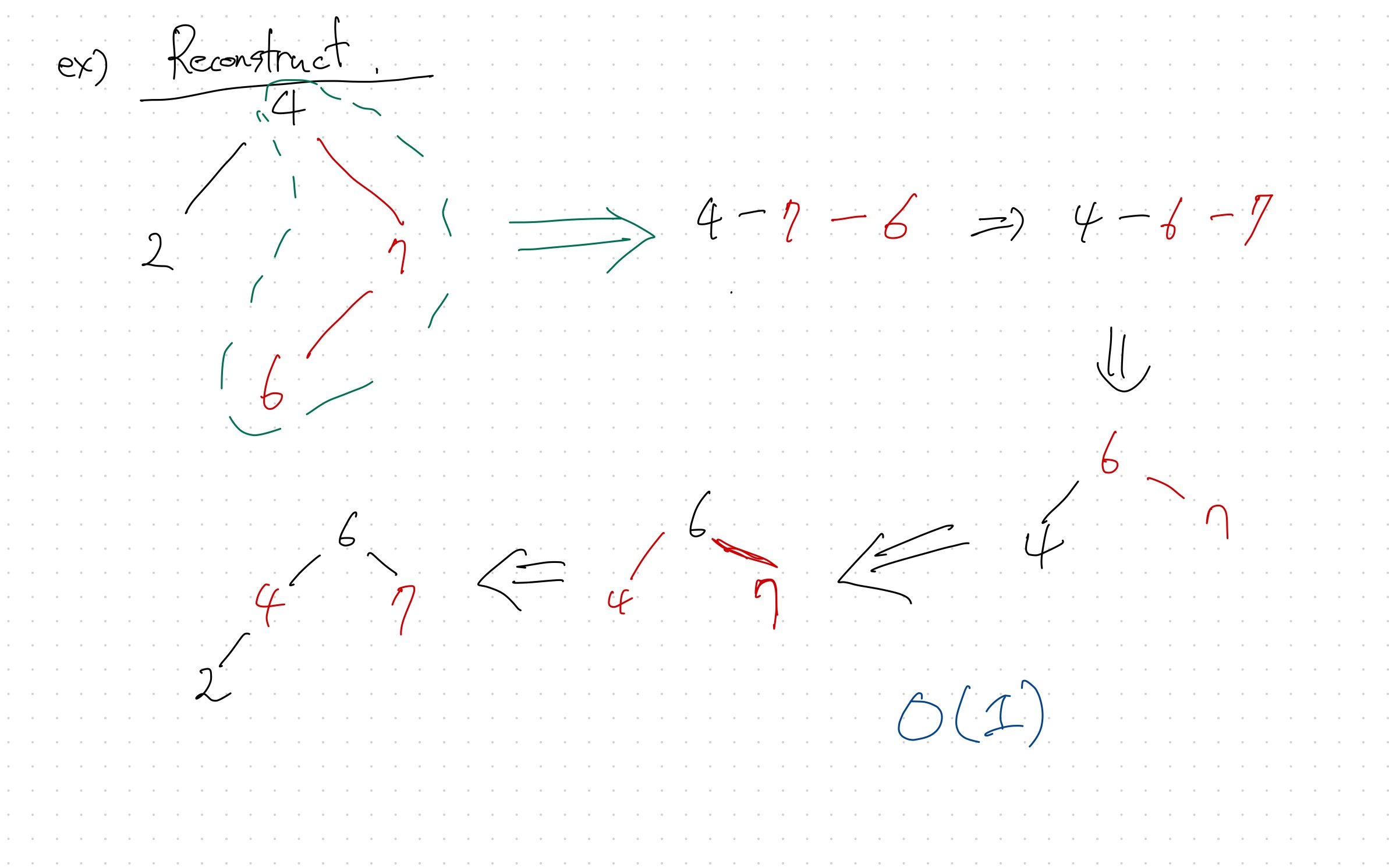
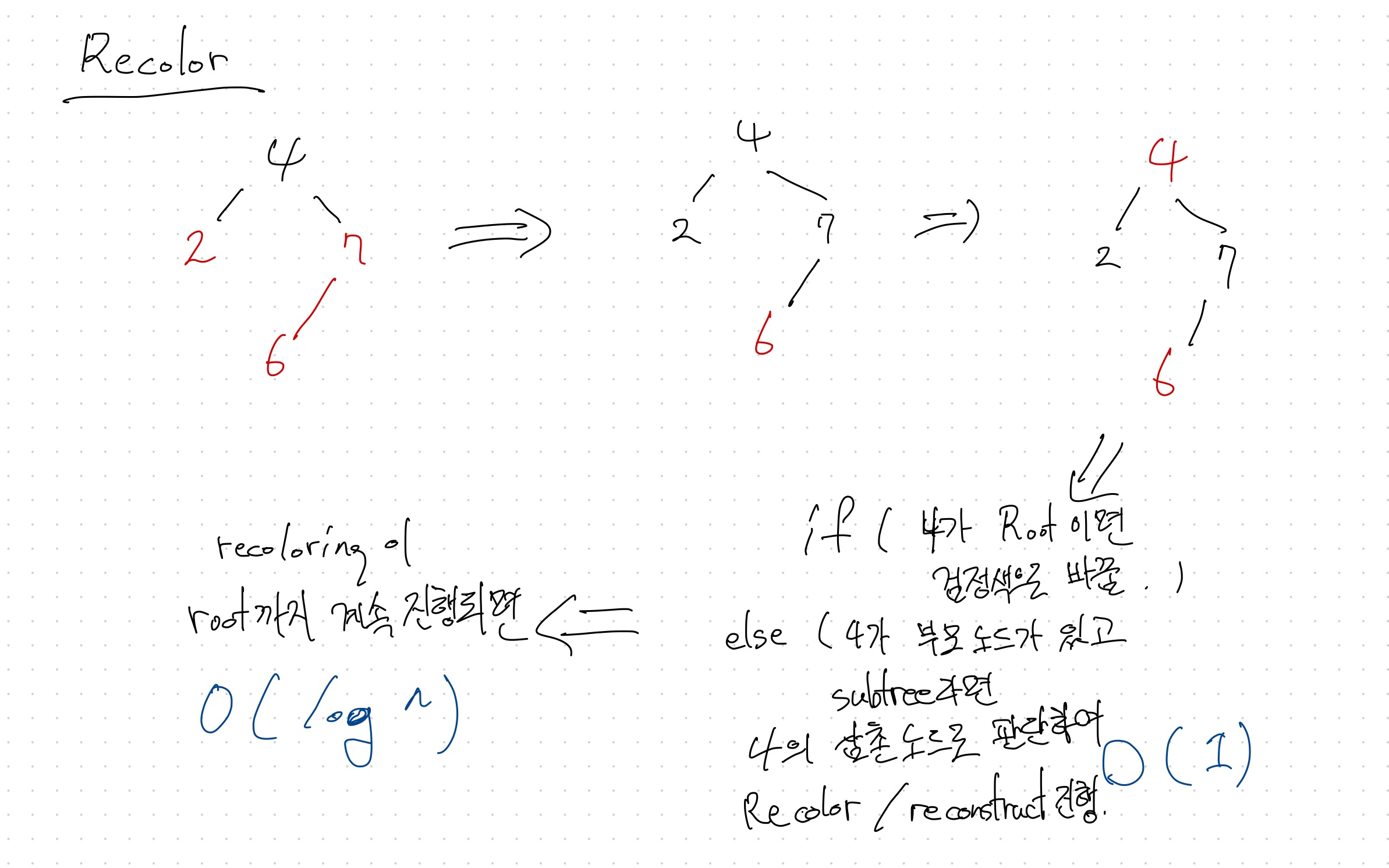

참고 자료 : http://www.secmem.org/blog/2019/05/09/%ED%8A%B8%EB%A6%AC%EC%9D%98-%EC%A2%85%EB%A5%98%EC%99%80-%EC%9D%B4%ED%95%B4/
