4.1 신경망이란 무엇인가?
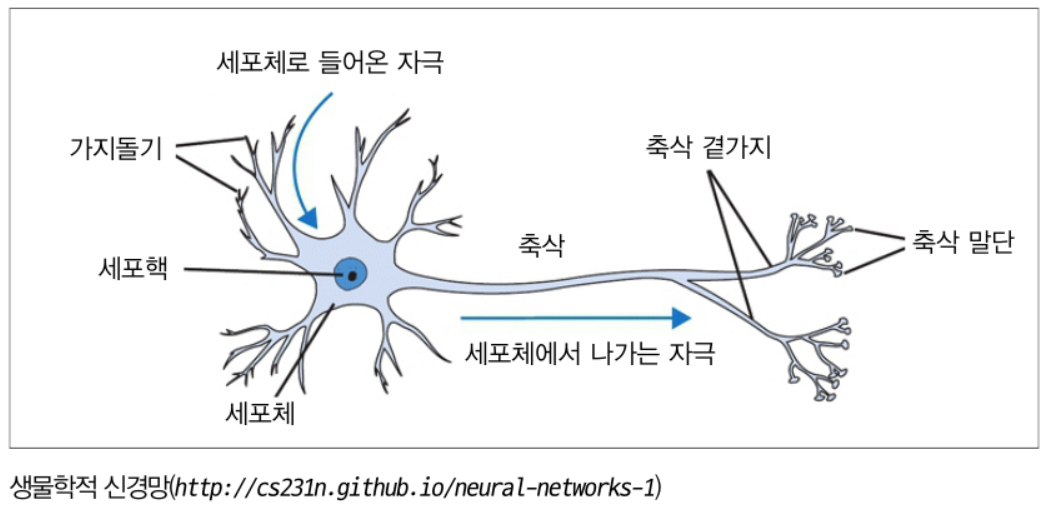
인공 신경망은 사람의 신경망인 뉴런은 본따서 만든 것입니다. 자극이 들어오고 임계치를 넘으면 축삭 말단에서 신경 전달물질이 분비 되는 것과 같이, 인공 뉴런에서는 자극이 들어오면, 가중치를 곱하고 편차를 더해준 이후, 결과값을 활성화 함수를 통과 시켜서 전달하게 됩니다. 이 인공 뉴런들이 모인 네트워크를 인공 신경망이라 합니다.
4.2 인공 신경망의 요소
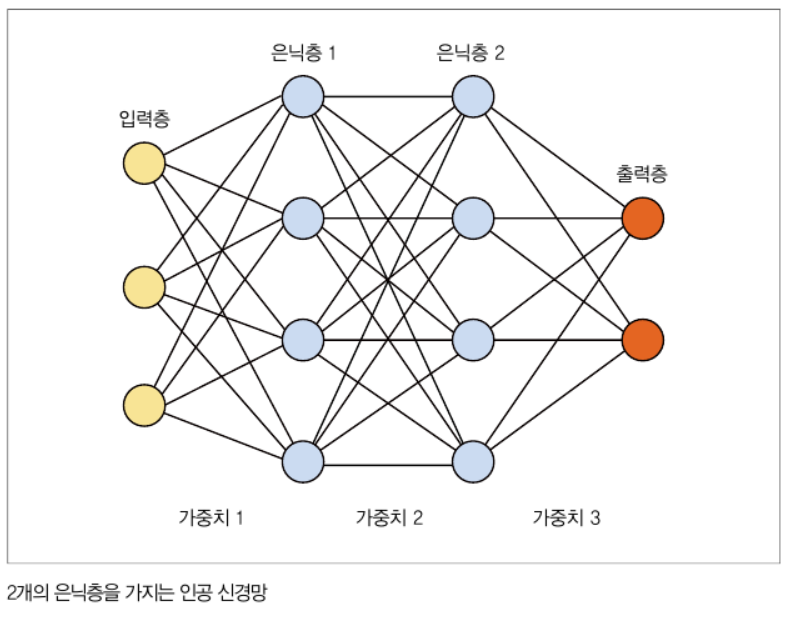
입력 신경망은 아래 그림과 같이 입력층, 은닉층, 출력층으로 분류할 수 있습니다.

심층 신경망은 은닉층이 2개 이상인 신경망을 뜻합니다. 각 신경망 층마다 y = w * x + b가 반복되며, 이러한 층이 여러개가 반복될 수록 선형 연산이 반복되어 아래와 같이 표현할 수 있을 것입니다.
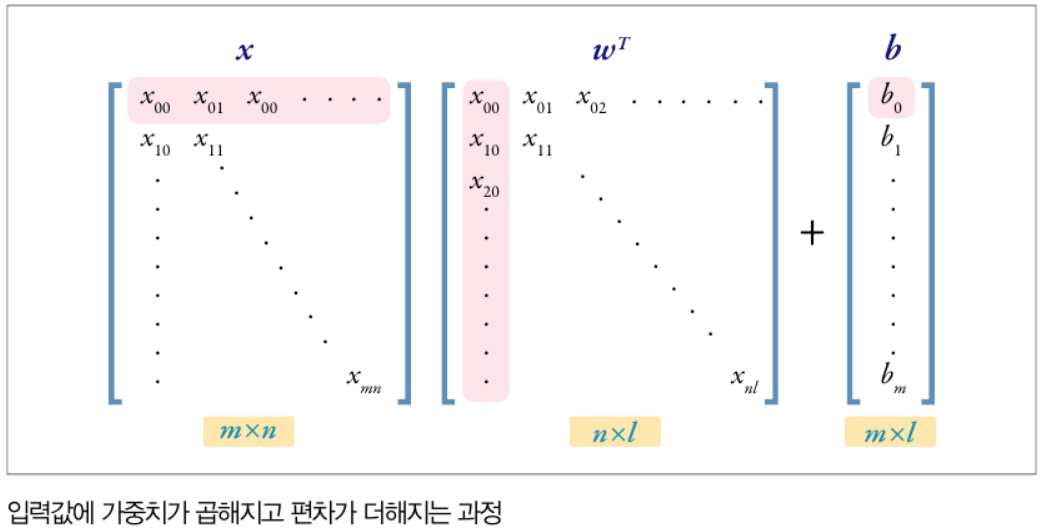
입력 데이터 x에 대해서 가중치 w를 곱하고, 편차 b를 더해준 값을 활성화 함수에 입력시키게 됩니다. 이렇게 활성화 함수를 통과한 값들은 비선형성(non-linearity)을 띄게 됩니다. 아무리 은닉층이 많아도 활성화 함수가 없다면 결국에는 선형 변환이므로 한계를 가질 것입니다.
활성화 함수의 종류로는 아래와 같이 sigmoid, ReLu, hyperbolic tangent같이 다양한 활성화 함수들이 존재합니다.
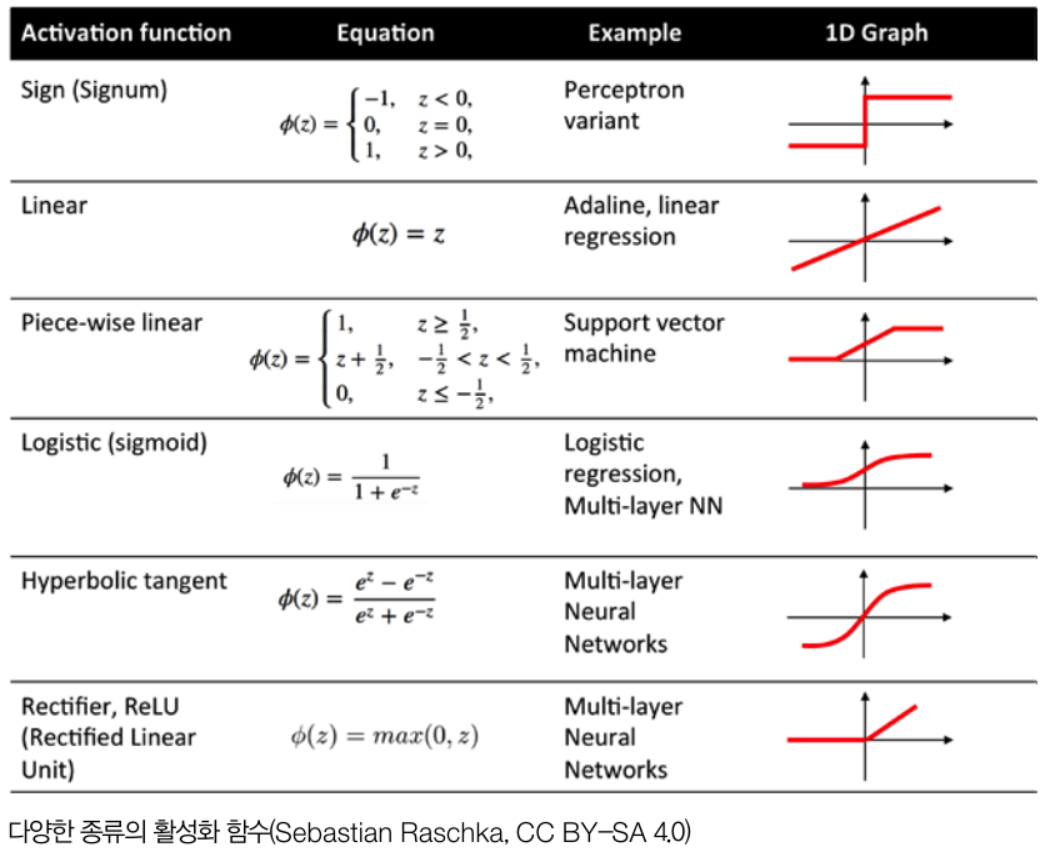
예전에는 sigmoid, hyperbolic tangent가 많이 사용되었으나, 최근에는 ReLU함수가 많이 사용되고 있습니다.
4.3 전파와 역전파
인공 신경망에 입력값이 들어오면 여라 개의 은닉층을 순서대로 거쳐 결괏값을 내는데, 이 과정을 전파(Forward Propagation)이라고 합니다. 아래는 3개의 입력을 받아 2개의 입력층을 통과하여 2개의 출력을 내는 신경망에 대한 그림입니다.
위의 그림에서 각 노드 사이에 Edge들은 가중치를 나타내며, 각 노드는 각각의 feature를 나타냅니다. 아래 그림은 가중치를 행렬로 나타낸 그림입니다.

입력(I)에 대하여 가중치(W)를 곱하여 출력(O)을 얻는 과정은 아래와 같이 이뤄집니다.
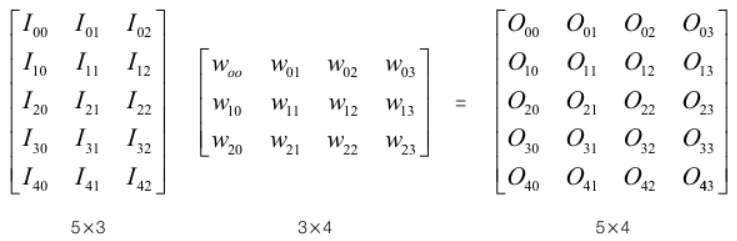
위와 같은 연산을 반복하게 되는 과정을 수식으로 표현하면 다음과 같습니다. 가중치를 w, 편차를 b, 활성화 함수를 σ라 두겠습니다
위에서 y'을 구하는 과정을 전파(Forward Propagation)라고 부릅니다.
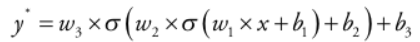
이제 loss를 구하기 위해서는 경사 하강법을 적용하기 위해서 가중치와 편차에 대해 loss를 미분하면 다음과 같습니다.
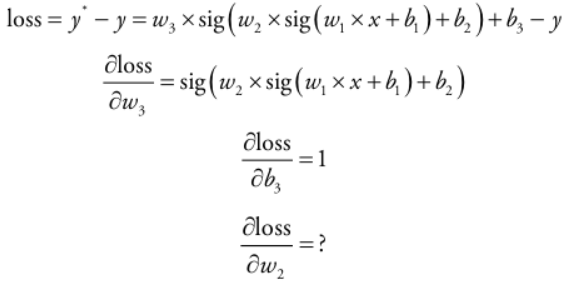
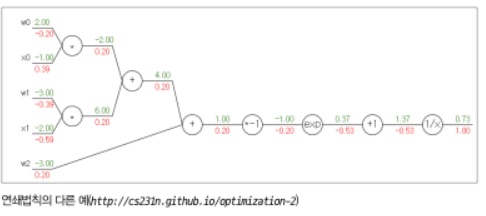
위에서 w3와 b3에 대해서는 바로 미분이 가능하나, w1, w2, b1, b2에 대해서는 바로 미분이 불가하게 됩니다. 이때 Chain-Rule(연쇄법칙)을 사용하여 미분값을 구할 수 있게 됩니다. 아래는 Chain-Rule 과정에 대한 그림입니다
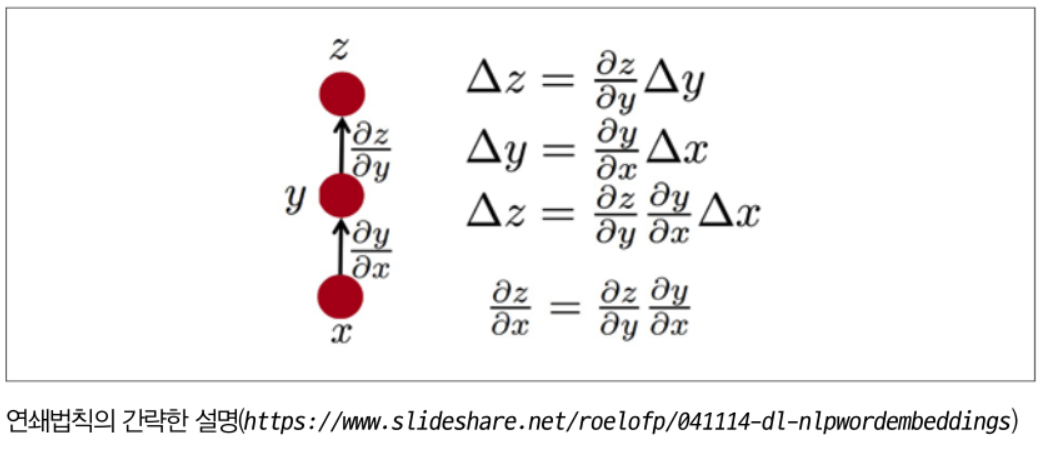
이제 chain-Rule를 사용하여 위에서 보았던 신경망에서 미분값을 구하는데 적용해 보겠습니다.
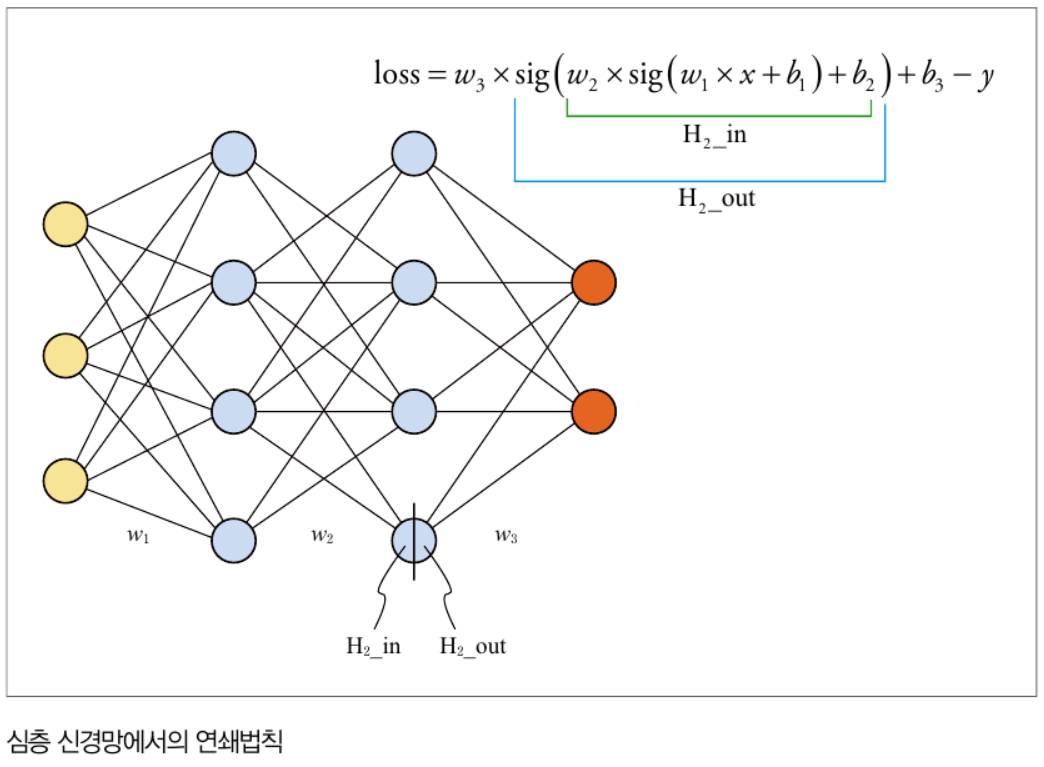
loss를 w2에 대해 미분하기 위해서는 loss를 h2(in)으로 먼저 미분한 값에, h2(in)을 w2로 미분한 값을 곱해주면 얻을 수 있습니다. 아래는 이 과정을 나타낸 것입니다.
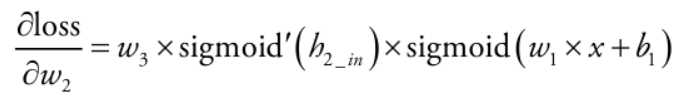
전파(Forward Propagation)은 입력값이 여러 은닉층을 통과해 결과로 나오는 과정이었다면, 역전파(Backward Propagation)은 결과와 정답의 차이로 계산된 손실을 Chain-Rule를 이용하여 입력 단까지 다시 전달하는 과정을 말합니다
4.4 모델 구현, 학습 및 결과 확인
이 섹션은 위에서 다룬 내용을 직접 Pytorch로 구현해보는 내용입니다. Pytorch에서는 역전파를 구하는 방법은 loss.backward()한줄이면 됩니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.init as init
num_data = 1000
num_epoch = 10000
noise = init.normal_(torch.FloatTensor(num_data, 1), mean = 0.0, std = 1)
x = init.uniform_(torch.Tensor(num_data, 1), -15, -15)
y = (x**2) + 3
y_noise = y + noise
model = nn.Sequential( # nn.Linera, nn.ReLu같은 모듈들을 쌓아주는 역할
nn.Linear(1,6),
nn.ReLU(),
nn.Linear(6,10),
nn.ReLU(),
nn.Linear(10,6),
nn.ReLU(),
nn.Linear(6,1)
)
loss_func = nn.L1Loss()
optimizer = optim.SGD(model.parameters(), lr=0.0002)
loss_array = []
for i in range (num_epoch):
optimizer.zero_grad()
output = model(x)
loss = loss_func(output, y_noise)
loss.backward() # Back-Propagation
optimizer.step()
loss_array.append(loss)matplotlib.pyplot을 이용하여 loss를 시각화 해보겠습니다.
import matplotlib.pyplot as plt
plt.plot(loss_array)
plt.show()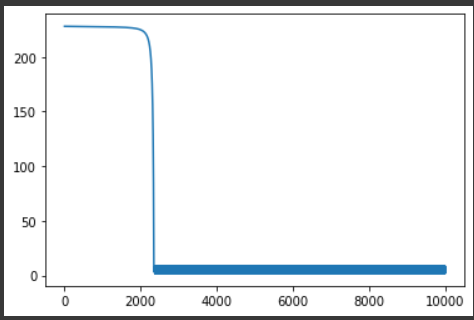
loss값이 0에 수렴해지는 것을 알 수 있습니다. 위의 과정에서 학습한 모델의 결과는 다음과 같습니다.
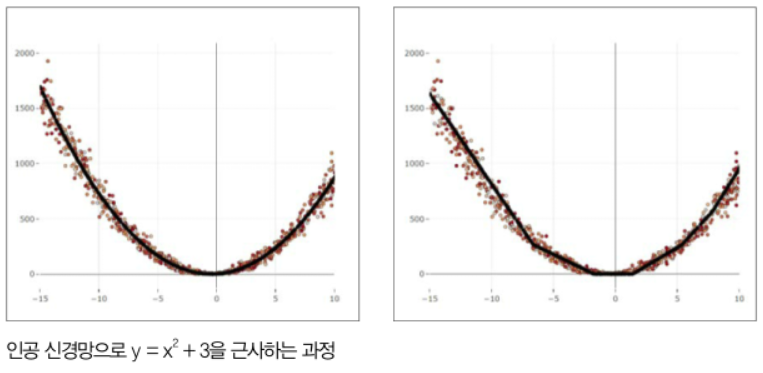
왼쪽 그림에서 빨간점은 노이즈를 추가한 학습데이터, 검은선은 label을 나타낸 것입니다. 오른쪽은 모델의 학습한 결과에 대한 그래프인데, 생각보다 잘 유추한 것을 확인할 수 있습니다. 그리고 자세히 보면 중간중간 꺽인 부분이 존재하는데 이는 ReLU함수의 영향으로, ReLU함수는 0보다 작은 값은 0으로 만들기 때문에 여러 은닉층을 통과하면서, 여러 지점에서 꺽인 모양이 나타나게 됩니다.
Reference
- 「파이토치 첫 걸음 : 딥러닝 기초부터 RNN, 오토인코더, GAN 실전 기법까지, 최건호 저, 한빛미디어」Chapter 04
