
이 강의는 홍콩과가대 김성훈 교수님의 모두의 딥러닝 강좌에 대한 내용 정리입니다.
오늘은 이전 글에서 이야기 했던 cost function을 어떻게 최소화해서 Linear Regression 학습을 완성하는 지 알아보는 시간입니다.
Hypothesis and Cost
지난 비디오에서 다룬 것처럼 우리의 가설이 로 주어지고, 이 가설에 기반하여 실제데이터와 얼마나 다른지 계산해주는 cost function을 다음과 같이 정의했습니다.
Simplified hypothesis
더 쉬운 이해를 위해서 가설을 단순화 시키면 다음과 같습니다.
이제 cost 함수를 자세히 봐볼까요?
| x | y |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
- W = 1, cost(W) = ?
즉,
- W = 1, cost(W) = 0
- W = 0, cost(W) = 4.67
- W = 2, cost(W) = 4.67
이러한 값을 가지게 됩니다.
여기서 의 값을 무수히 많이 주게 되면 아래와 같은 그림을 보여주게 되는데요.
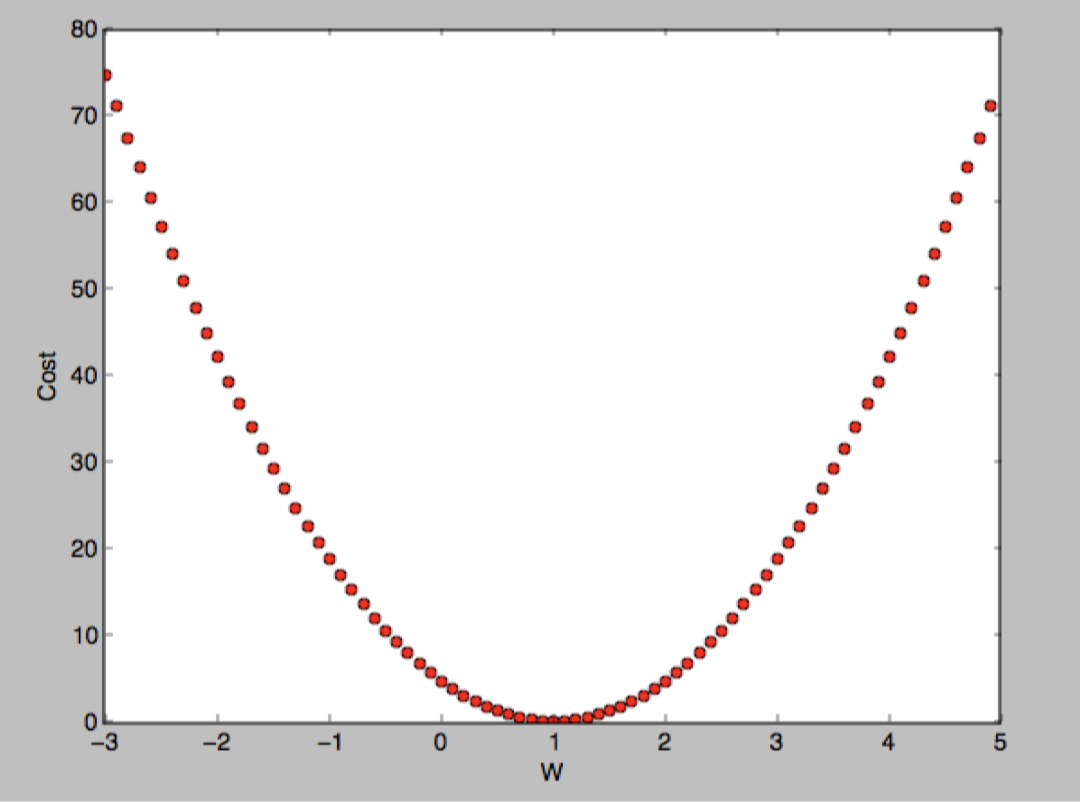
x축이 값을 가지고 y축이 Cost인 것을 확인할 수 있습니다.
How to minimize cost?
이제 다시 처음으로 돌아가서, 우리는 cost를 최소화하는 를 찾아야합니다. 위 그림에서 우리는 가 1이라고 쉽게 알 수 있지만 기계가 알 수 있도록하는게 중요합니다.
그래서 여기에 많이 사용되는 알고리즘이 Gradient descent algorithm입니다. 이름을 보면 알 수 있듯이 경사를 따라 내려가는 알고리즘입니다.
Gradient descent algorithm
- cost function을 최소화하는데 사용
- Linear regression 외에도 여러 minimization problem에 사용됨
- 라는 cost function을 가질 때, 최소화되는 와 를 찾아줌
- 와 뿐만 아리나 여러 값의 최솟값을 찾는데도 사용할 수 있음
How it works
- 아무 점에서 시작할 수 있음
- 와 를 바꾸고 를 계산
- 그 때의 경사도를 (미분을 사용하여)계산
- 낮은 경사를 찾아서 계속 반복
