
이 강의는 홍콩과가대 김성훈 교수님의 모두의 딥러닝 강좌에 대한 내용 정리입니다.
Regression
test data
| x | y |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
x는 예측을 하기 위한 기본적인 자료 또는 feature
y는 예측해야 할 대상
(Linear) Hypothesis
Regression 모델을 학습한다는 것은 (데이터는 잘 모르겠지만 이정도로 맞을 것이다라는) 하나의 Hypothesis[가설] 을 세울 필요가 있다.
- Linear하다는 것은 선형을 의미하기 때문에 어떤 선형을 가지는 지 찾는 것을 말한다.
test data에 대해서 선을 그어 본다고 하면 아래와 같은 수식이 나오게 된다.
아래의 식에서는 W와 b에 따라 여러 선을 가지게 된다.
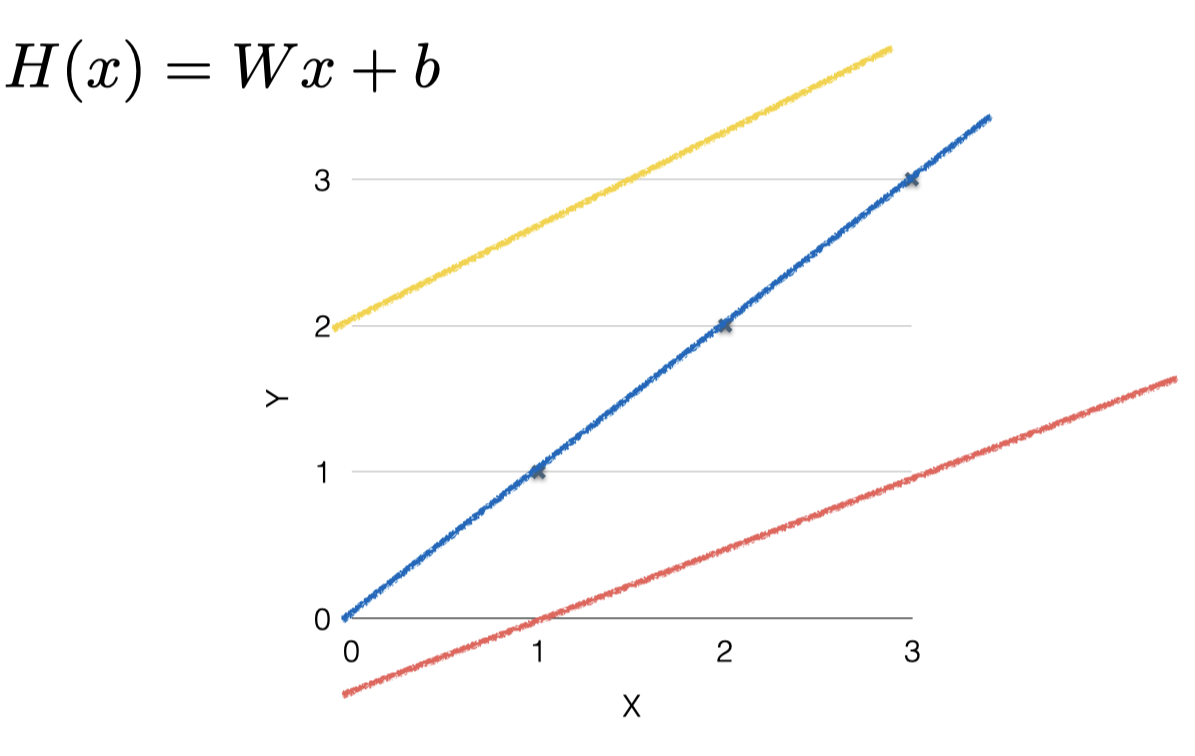
파란 선의 경우에는 H(x)= x라는 Hypothesis를 가지게 된다.
노란 선의 경우에는 H(x) = 0.5x+2라는 Hypothesis를 가지게 된다.
그렇다면 이 두 선중에 어떤 것이 더 좋은 가설인지 알아볼 필요가 있다. (즉, 어떤 W와 b의 값이 적절한지 알아야 한다.)
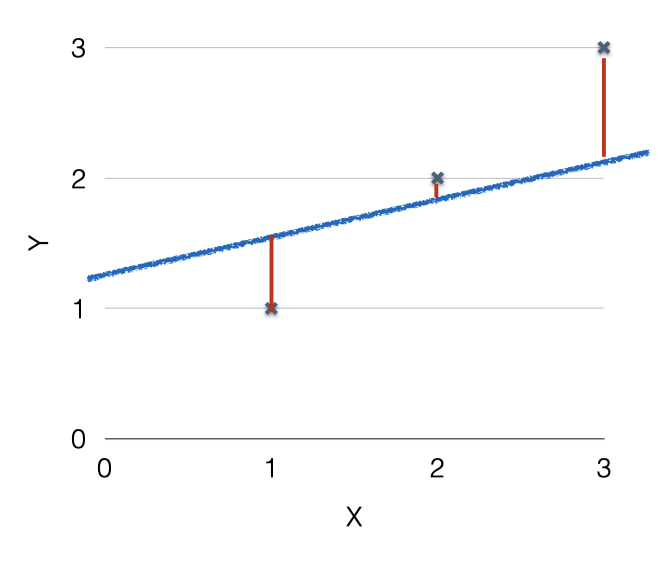
가장 기본적으로는, 실제 데이터와 가설이 나타내는 점들과의 거리를 비교하는 것이다. 거리가 멀면 나쁜 가설이고, 거리가 가까우면 좋은 가설이라고 할 수 있다. 이 거리를 비교하는 것을 Linear Regression에서는 Cost(Loss) function이라고 한다.
위의 표를 예로 Cost function을 계산해본다면
식을 사용할 수 있다.
(제곱)을 하는 이유는 거리가 음수가 나올수도 있는데 이럴경우에도 일정하게 양수로 표현해줄 수 있기 때문이다.
물론 제곱을 함으로서 거리의 차이가 작을 때보다 차이가 클 때 패널티를 더 주게 됩니다.
하나의 점이 아닌 여러 점에서 선과 거리를 비교해야 하기 때문에 각 점과 선과의 거리의 평균을 내게 된다.
