
이 강의는 홍콩과가대 김성훈 교수님의 모두의 딥러닝 강좌에 대한 내용 정리입니다.
오늘은 저번 시간에 이어서 하나의 변수가 아닌 Multi variable을 사용하는 방법에 대해서 이야기 해보도록 하겠습니다.
Recap
- Hypothesis
-- = weight
- = bias
- 와 를 학습
- 학습을 하는데 cost를 계산하기 위해 Cost function 필요
- Cost/Loss function
- - Gradient descent algorithm
Regression using three inputs (x1, x2, x3)
| x1 (quiz 1) | x2 (quiz 2) | x3 (midterm 1) | Y (final) |
|---|---|---|---|
| 73 | 80 | 75 | 152 |
| 93 | 88 | 93 | 185 |
| 89 | 91 | 90 | 180 |
| 96 | 98 | 100 | 196 |
| 73 | 66 | 70 | 142 |
3개의 데이터를 이용하여 Y(final)점수를 예측할 수 있을까요?
위처럼 기본 식에 학습해야할 변수를 추가해주면 됩니다.
Cost function은 어떻게 될까요?
Cost function은 크게 바뀌지 않는 것을 확인할 수 있습니다. 문제는 Hypothesis의 변수가 추가될 때마다 계속 길어진 다는 것인데, 이 형태를 어떻게 간단하게 만들 수 있을까요?
🙋matrix의 곱을 이용하면 됩니다.
💡 눈치가 빠르신 분들은 눈치 채셨겠지만 위의 Hypothesis의 와 의 위치가 matrix의 곱을 이용했을 때에는 위치가 바뀌어 있는 것을 볼 수 있습니다.
그런데 사실상 순서가 바뀌더라도 같은 식이기 때문에 문제가 없습니다.
보통 matrix를 사용할 경우에는 를 앞에 작성합니다.
따라서 로 이해할 수 있겠죠?
자. 그러면 실제 데이터에 적용해 봅시다.
를 인스턴스라고 보는데 이 인스턴스들이 5개 존재하는 걸 볼 수 있습니다. 5개의 인스턴스를 matrix에 적용하면 아래와 같이 만들어지게 됩니다.
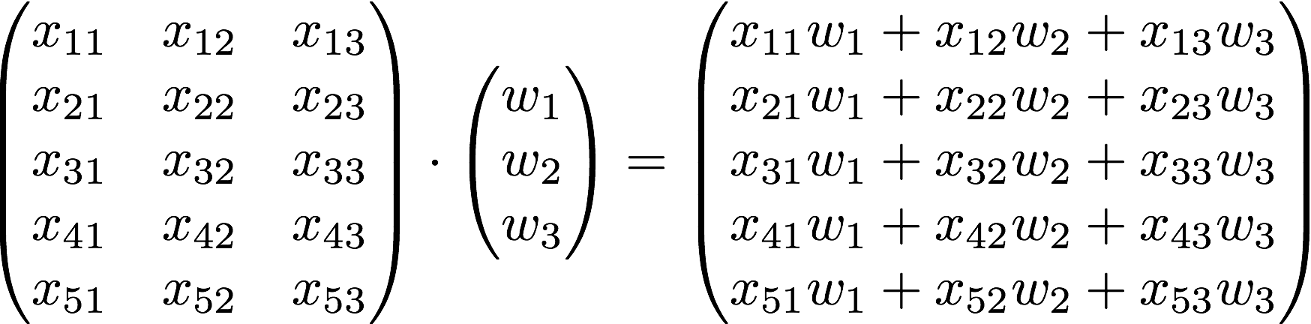
하지만 는 그대로죠? 이 방법의 장점은 각각의 인스턴스마다 matrix의 곱을 계산할 필요 없이 전체 인스턴스를 긴 matrix에 넣고 한번에 계산할 수 있습니다. 이것은 굉장히 큰 장점이라고 할 수 있습니다.
WX vs XW
- Lecture(theory):
- 이론으로는 W라는 Weight과 곱해준다는 의미에서 앞에 작성한다.
- Implementation (TensorFlow)
- 실제 구현에서는XW로 많이 사용한다. (수학적으로는 이론과 동일)
Reference
- 여러개의 입력(feature)의 Linear Regression - TensorFlow 구현
강의
강의자료 - Youtube
- Gradient descent algorithm
