11월 첫 번째 주말이다. 오늘은 미용실에 가서 머리도 새로 하고 커피도 마시면서 여유를 즐길 요량이다. 하지만 그 전에, 자! 어제 못 다 한 파이썬 기초에 대해서 마저 정리해보자.
-
오늘 학습 키워드
파이썬 기초 재확인 - 자료형(튜플, 딕셔너리)부터 조건문까지 -
오늘 학습한 내용을 나만의 언어로 정리하기
오늘은 어제 진행하다가 시간이 부족해 미처 끝내지 못 한 파이썬의 기초 내용들에 대해서 간단하게 정리하고 마무리하려고 한다. 빠르게, 그러면서도 정확하게 개념들을 훑어 보자. -
학습 내용
-
튜플(Tuple) : 변경할 수 없는(immutable) 시퀀스(sequence) 자료형을 말한다. 리스트와는 그 형태와 특성이 유사하지만, 한 번 설정한 이후에는 요소 수정이 불가능하다는 아주 큰 차이점을 가지고 있다. 데이터를 보호하고 싶을 때 주로 사용되고, 소괄호() 를 써서 생성할 수 있다.
*튜플을 생성할 때, 소괄호()를 생략해도 생성이 가능하다.튜플의 기본형은 다음과 같다.
tuple = (요소1, 요소2, 요소3)리스트와 마찬가지로, 튜플도 인덱싱과 슬라이싱을 통해 값에 접근하는 것이 가능하다.
tuple[0] # 튜플 첫 번째 인덱스
tuple[-1] # 튜플 마지막 인덱스
tuple[2:3] # 튜플 인덱스 2부터 인덱스 3까지
tuple[::2] # 튜플 인덱스 0부터 2개 간격으로위와 같이 조회하고 싶은 데이터만 따로 불러낼 수 있다.
실제로 튜플을 인덱싱해보자.
my_tuple = (1, 2, 3, 'hello', 'world') # () 생략 가능
print(my_tuple)위의 코드를 실행하면 아래 사진과 같이 출력된다.

리스트가 대괄호[] 로 출력되는 것과는 달리, 튜플은 소괄호() 로 출력되는 것이 보인다.
여기에 위의 인덱싱과 슬라이싱 예시를 적용해보면,
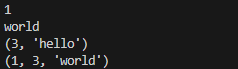
예시의 주석(설명)과 동일하게 출력된 것을 알 수 있다.
튜플은 값을 변경하는 것이 불가능하기 때문에, 사용 가능한 매서드도 적다. 튜플에서 사용할 수 있는 메서드는 다음과 같다.
count() # 값의 갯수 출력
index() # 값이 가지는 인덱스의 순서값 출력위 메서드들을 실제로 적용하면 다음과 같이 출력된다.
my_tuple = (1, 2, 3, 'hello', 'world')
count_of_1 = my_tuple.count(1) # "1"이라는 값의 갯수
print("Count of 1:", count_of_1)
index_of_3 = my_tuple.index(3) # "3"이라는 값이 가지는 인덱스의 순서값
print("Index of 3:", index_of_3)
튜플 내에 "1"은 한 개 있다. 따라서 count() 는 1로 출력되었다.
마찬가지로 "3"이라는 값의 인덱스 순서는 2이기 때문에 3의 인덱스 값인 "2"가 출력되었다.
이미 작성된 튜플 내부의 값은 수정할 수 없지만, 튜플끼리 묶어서 출력하는 것은 가능하다.
tuple1 = (1, 2, 3)
tuple2 = ('a', 'b', 'c')
new_tuple = tuple1 + tuple2
print(new_tuple)예시 코드를 보면, 두 개의 튜플이 존재한다. 이 튜플들의 값을 한 행에 연결해서 출력하고 싶을 때, 튜플명1 + 튜플명2 라는 식을 작성하면 튜플의 값들이 하나로 연결되어 출력되게 된다.

튜플의 값을 반복해서 출력하는 것도 가능하다. 출력하고 싶은 횟수만큼 곱하기 부호(*)를 사용해주면 된다.
repeated_tuple = tuple1 * 3
print(repeated_tuple)
튜플은 기본적으로 값의 수정이 불가능하지만, 값을 수정할 수 있도록 만드는 방법이 존재한다.
바로 튜플을 리스트 형식으로 변경해주는 방법이다.
방법은 간단하다. 튜플명에 list() 를 씌워주기만 하면 된다.
new_tuple1 = list(tuple1)
print(new_tuple1)
print(type(new_tuple1))튜플을 리스트로 바꿔주었다. 한 번 출력해서 바뀌었는지 확인해보자.
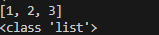
괄호의 모양이 바뀌고, 자료형도 list로 바뀌었다!
튜플을 리스트로 변경한 후, 값을 수정하고 다시 튜플로 저장하는 것도 물론 가능하다. list() 를 씌웠던 튜플에 다시 tuple() 을 씌워주면 된다.
값 "4"를 리스트에 추가한 후, 다시 튜플로 바꿔보자.
new_tuple1.append(4)
re_tuple1 = tuple(new_tuple1)
print(re_tuple1)
print(type(re_tuple1))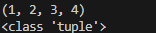
튜플에 4가 추가되고, 괄호의 형태도 () 로 바뀌었다!!
여기까지 튜플의 기본에 대해서 알아보았다. 요약하면, 튜플은 값을 변경할 수 없는 리스트라고 할 수 있겠다. 값을 변경할 수 없기에 사용 가능한 메서드도 적다.
이러한 특성때문에 튜플은 주로 변하면 안 되는 데이터를 저장할 때 사용된다.
번거롭긴 하지만 리스트 형태로 바꿔서 값을 변경할 수도 있긴 하다. 다만 이 때는 변경할 데이터를 정확히 숙지하고, 변경 후에는 신속하게 튜플로 되돌려놓을 필요가 있다.
- 딕셔너리(Dictionary) : 딕셔너리는 키-값 쌍의 데이터를 저장하는 자료구조로, 중괄호{} 를 사용하여 생성할 수 있다. 이 때, 키는 중복이 없어야 한다. 값은 중복 가능하다.
딕셔너리의 기본 구조는 다음과 같다.
my_dict = {
'key1': 'value1',
'key2': 'value2',
'key3': 'value3'
}딕셔너리는 값(value)에 접근할 때 키(key)를 활용한다. 다음의 예시를 보자.
# 학생 성적표
grades = {
'Alice': 90,
'Bob': 85,
'Charlie': 88
}여기서 "Alice"라는 학생의 성적에 접근하려면 다음과 같이 코드를 작성하면 된다.
print(grades['Alice'])
정확하게 "Alice"의 성적인 "90"이라는 값을 가져왔다.
딕셔너리는 값에 접근하는 것 외에도, 리스트와 동일하게 값을 변경하는 것이 가능하다.
아래 코드는 딕셔너리의 값을 변경해주는 코드를 모아놓은 것이다.
# 값 수정하기
grades['Bob'] = 95
print(grades)
# 요소 추가하기
grades['David'] = 78
print(grades)
# 요소 삭제하기
del grades['Charlie']
print(grades)위 코드들을 실행하면 다음과 같이 출력된다.

"Bob"의 성적이 85에서 95보 바뀌고, "David"가 추가, "Charlie"가 삭제된 것이 보인다.
딕셔너리는 몇 가지 전용 메서드를 가지고 있다.
다음 코드는 딕셔너리의 메서드를 모은 코드이다.
# 새로운 딕셔너리 생성
dict_1 = {
'name':'John',
'age':'30',
'city':'New York'
}
# 모든 키를 dict_keys 객체로 반환
keys = dict_1.keys()
print(keys) # 출력: dict_keys(['name', 'age', 'city'])
# values() 메서드
# 모든 키를 dict_values 객체로 반환
values = dict_1.values()
print(values) # 출력: dict_values(['John', 30, 'New York'])
# items() 메서드
# 모든 키-값 쌍을 (키, 값) 튜플로 구성된 dict_items 객체로 반환
items = dict_1.items()
print(items) # 출력: dict_items([('name', 'John'), ('age', 30), ('city', 'New York')])
# get() 메서드
# 지정된 키에 대한 값을 반환 / 키가 존재하지 않으면 기본값을 반환
age = dict_1.get('age')
print(f"Age: {age}") # 출력: "Age: 30"
# pop() 메서드
# 지정된 키와 해당 값을 딕셔너리에서 제거하고 값을 반환
city = dict_1.pop('city')
print(f"City: {city}") # 출력: New York
print(f"Dictionary after pop: {dict_1}") # 출력: {'name': 'John', 'age': 30}
#popitem() 메서드
# 딕셔너리에서 마지막 키-값 쌍을 제거하고 반환
last_item = dict_1.popitem()
print(f"Last item popped: {last_item}") # 출력: ('age', 30)
print(f"Dictionary after popitem: {dict_1}") # 출력: {'name': 'John'}위 코드의 실행 결과는 다음과 같다.
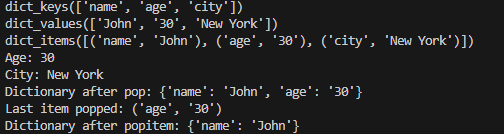
여기까지가 딕셔너리의 기본 내용이다. 요약하자면 딕셔너리는 키와 값이 쌍으로 이루어져있는 시퀀스 자료형이다. 키는 반드시 하나만 존재해야 한다.
딕셔너리를 사용하는 이유는 리스트나 튜플과는 달리 모든 값을 알고 있지 않아도, 키값만 알고 있다면 쉽게 데이터에 접근할 수 있는 편리함 때문이라고 생각한다. 수정도 간편하니 오류가 발생했을 경우 빠르게 대처 가능한 것도 장점 중 하나이다.
리스트나 튜플과 동일하게, 딕셔너리도 단일로만 사용하면 금방 한계에 도달할 것이다. 사실 팡썬의 어떤 함수, 어떤 자료형도 단일로 쓰이는 경우는 거의 없을 것이다. 다른 요소들과 융합하여 사용될 때 시너지 효과가 극대화될 것이다.
- 조건문 : 조건문이란 프로그램의 흐름을 제어하는 중요한 요소 중 하나로, 특정 조건이 참(True)인 경우에만 특정 코드 블록을 실행하도록 만든다. 이전에 다뤘던 불리언(boolean)을 활용한 것이다.
조건문의 기본형은 다음과 같다.
if 조건:
조건1 # 조건이 참일 때 실행될 코드
elif 다른조건:
조건2 # 다른 조건이 참일 때 실행될 코드
else:
나머지 경우주석에도 쓰여 있듯이, 조건문은 기본적으로 조건에 일치할 경우 코드를 실행한다. 따라서 어떤 데이터를 볼 것인지, 그 조건을 신중하게 설정해야 원하는 데이터를 정확하게 얻을 수 있다.
간단한 예시를 함께 보자.
x = 10
if x > 5:
print("x는 5보다 큽니다.")
else:
print("x는 5보다 작거나 같습니다.")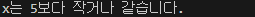
조건문을 작성할 때 유의해야 할 점이 하나 더 있다. 바로 "들여쓰기"이다.
파이썬은 들여쓰기를 통해서 함수가 어디에 어떻게 연결되어 있는지 파악한다. 이를 "블록을 식별한다"라고 한다. 블록을 제대로 구별해서 코드를 작성하지 않으면, 해당 코드는 오류를 일으켜 실행되지 않거나 잘못된 결과를 출력하게 된다.
조건문에 포함시키는 조건은 진위 여부를 확인하는 조건이 들어간다. 이 말은, 크다, 작다와 같은 비교 연산자가 아닌 산술 연산자는 사용 불가하다는 뜻이다.
필요한 조건이 한 번에 두 가지 이상일 경우에는 논리 연산자를 통해서 조건들을 결합시켜줄 수 있다. 아래는 논리 연산자의 종류이다.
and : 모두 참일 때 참
or : 하나 이상이 참일 때 참
not : 조건을 부정또한 조건문은 중첩해서 사용하는 것이 가능하다. 즉 조건문 안에 조건문을 써 넣는 것이 가능하다.
x = 10
if x > 5:
print("x는 5보다 큽니다.")
if x < 15:
print("x는 15보다 작습니다.")
else:
print("x는 15보다 큽니다.")
else:
print("x는 5보다 작거나 같습니다.")변수 x의 값을 10으로 선언한 후에 아래 코드를 통과시키면,
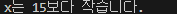
라는 결과를 출력한다.
x가 바깥의 조건인 x > 5를 만족하고 나서, 안의 조건인 x < 15를 한 번 더 만족시켰기 때문에 위 사진과 같은 문구를 출력하게 되었다.
조건문은 조건을 통해서 변수를 필터링하는 기능을 한다. 즉 내가 원하는 내용의 데이터만을 전체 데이터에서 불러올 수 있게 만들어 준다. 앞서도 말했듯이 만약 필터링의 조건이 잘못될 경우, 원하던 데이터와는 전혀 다른 의미를 가진 데이터가 뽑힐 것이다. 그렇기 때문에 조건문을 설정할 때는 신중하게 조건 기준을 정해야만 한다.
- 학습하며 느낀 점
이틀에 걸쳐서 파이썬 기초를 훑어 보았다. 리스트의 내용이 워낙 많아서 한 번에 이해하기는 조금 벅찬 듯하다. 일단 주말은 마음 편하게 휴식을 취하고, 오는 월요일에 다시 힘내서 천천히 복습을 해야겠다.
마치며 : 어느 새 수능이 머지 않았다. 그에 따라서 날씨도 점점 추워져가는 듯하다. 이 글을 읽는 여러분들도 추워지는 날씨에 감기 조심하시길 바란다.
주말 잘 쉬세요!
