Pandas 시작하기
import pandas as pd1차원 데이터 다루기 - Series
- 1-D labeled array
- 인덱스 지정 가능
s = pd.Series([1, 4, 9, 16, 25])
0 1
1 4
2 9
3 16
4 25
dtype: int64t = pd.Series({'one':1, 'two':2, 'three':3, 'four':4, 'five':5})
one 1
two 2
three 3
four 4
five 5
dtype: int64Series와 Numpy
Series는 Numpy의 ndarray와 유사하다
t[1]
2t[1:3]
two 2
three 3
dtype: int64s[s > s.median()] # numpy처럼 조건식으로 추출
3 16
4 25
dtype: int64import numpy as np
np.exp(s) # numpy의 함수 사용 가능
0 2.718282e+00
1 5.459815e+01
2 8.103084e+03
3 8.886111e+06
4 7.200490e+10
dtype: float64s.dtype
dtype('int64')Series와 dict
- Series는 dict와 유사하다
t['one']
1t['six'] = 6
one 1
two 2
three 3
four 4
five 5
six 6
dtype: int64'six' in t
True'seven' in t
False# t['seven']
# KeyErrort.get('seven', 0)
0Series에 이름 붙이기
- Series 선언시 이름을 붙일 수 있다.
- name 속성을 가지고 있어서 변경할 수 있다.
s = pd.Series(np.random.randn(5), name='random_nums')
0 0.449891
1 1.002985
2 -0.647092
3 1.231667
4 -0.598875
Name: random_nums, dtype: float64s.name = "이름 변경"
0 0.449891
1 1.002985
2 -0.647092
3 1.231667
4 -0.598875
Name: 이름 변경, dtype: float642차원 데이터 다루기 - dataframe
dataframe
- 2-D labeled table
- 인덱스 지정 가능
d = {"height":[1,2,3,4], "weight":[30, 40, 50, 60]}
df = pd.DataFrame(d)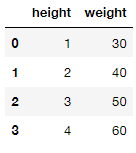
df.dtypes
height int64
weight int64
dtype: object
From CSV to DataFrame
- Comma Separated Value에서 DataFrame으로 생성하기
- .read_csv()
- 사용된 covid 데이터
covid = pd.read_csv("./country_wise_latest.csv")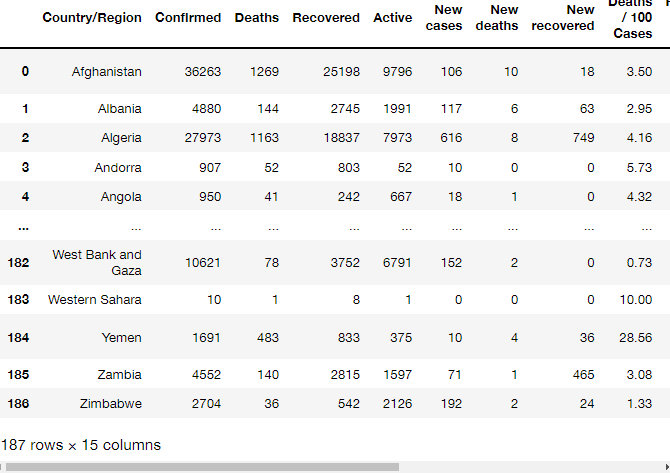
head(N) : 처음 N개의 데이터 참조
covid.head(5)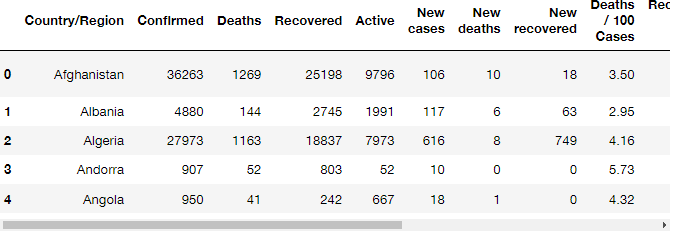
tail(N) : 마지막 N개의 데이터 참조
covid.head(5)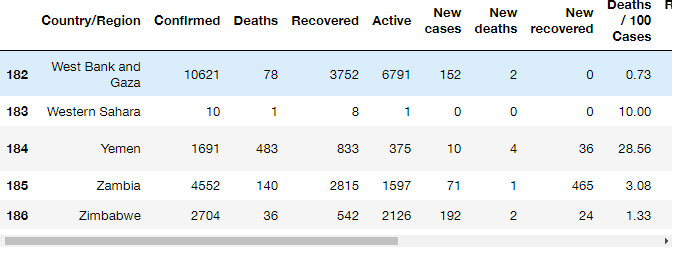
데이터 접근하기
df['column_name'] or df.column_name
covid['Active']
0 9796
1 1991
2 7973
3 52
4 667
...
182 6791
183 1
184 375
185 1597
186 2126
Name: Active, Length: 187, dtype: int64covid.Active
0 9796
1 1991
2 7973
3 52
4 667
...
182 6791
183 1
184 375
185 1597
186 2126
Name: Active, Length: 187, dtype: int64위 두가지 방법의 차이는, column_name이 띄어쓰기를 포함하고 있을 때, 아래의 방법을 사용할 수 없다
type(covid['Confirmed'])
pandas.core.series.Seriesdataframe은 각 column은 series다.
즉 series에 적용가능한 특징들을 사용할 수 있다.
covid['Confirmed'][0]
36263covid['Confirmed'][1:5]
1 4880
2 27973
3 907
4 950
Name: Confirmed, dtype: int64조건을 이용해서 데이터 접근하기
## 확진자 5천명이 넘는 나라 찾기
covid[covid["New cases"] > 5000]
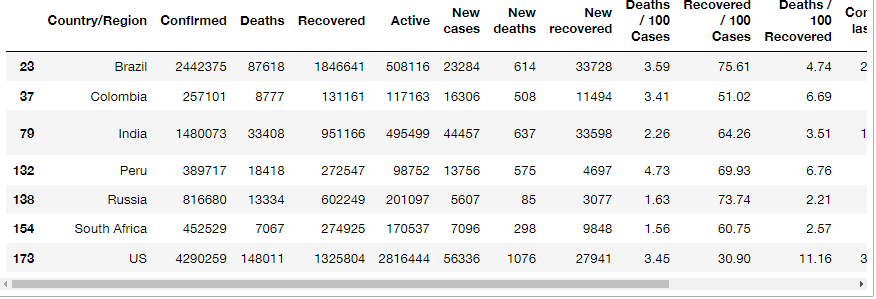
# WHO 지역(WHO Region)이 동남아시아인 나라 찾기
covid["WHO Region"].unique()
array(['Eastern Mediterranean', 'Europe', 'Africa', 'Americas',
'Western Pacific', 'South-East Asia'], dtype=object)covid[covid['WHO Region'] == 'South-East Asia']
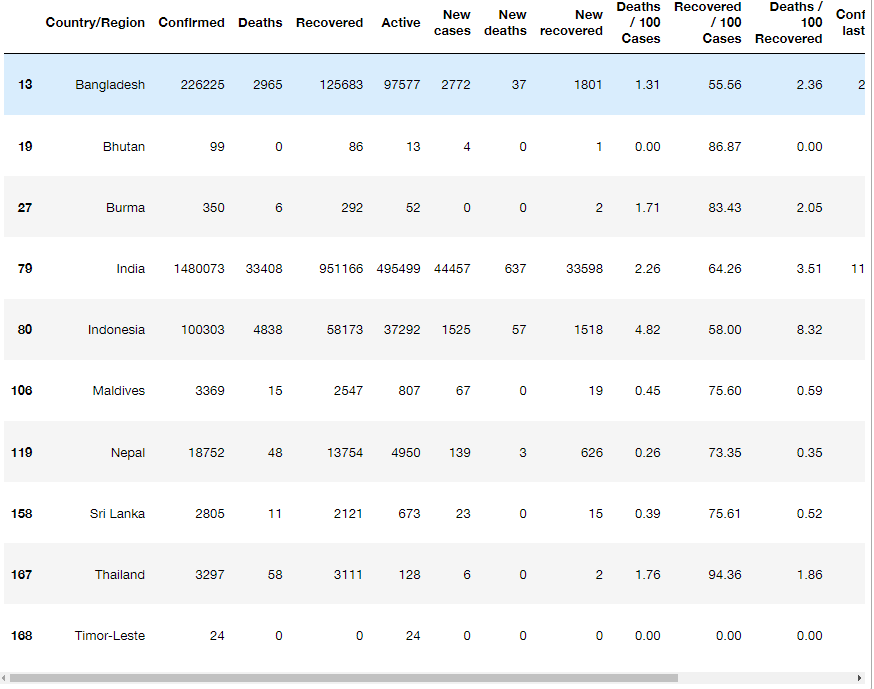
행을 기준으로 데이터 접근하기
# 예시 데이터 - 도서관 정보
books_dict = {"Available":[True, True, False], "Location":[102, 215, 323], "Genre":["Programming", "Physics", "Math"]}
books_df = pd.DataFrame(books_dict, index=['버그란 무엇인가', '두근두근 물리학', '미분해줘 홈즈'])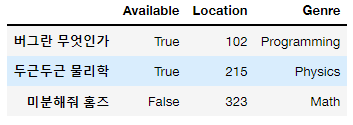
인덱스를 이용해서 가져오기
.loc[row, col]
books_df.loc['버그란 무엇인가']
Available True
Location 102
Genre Programming
Name: 버그란 무엇인가, dtype: object# 미분해줘 홈즈 책이 대출이 가능한지?
books_df.loc["미분해줘 홈즈", 'Available']
False숫자 인덱스를 이용해서 가져오기
.iloc[rowidx, colidx]
## 특정 요소
books_df.iloc[0,1]
102## 슬라이싱
books_df.iloc[1, :2]
Available True
Location 215
Name: 두근두근 물리학, dtype: objectgroupby
- Split : 특정한 기준을 바탕으로 DataFrame을 분할
- Apply : 함수 - 주로 sum(), mean(), median() 등 통계 함수 - 를 적용해서 각 데이터를 압축
- Combine : Apply된 결과를 바탕으로 새로운 Series를 생성 (group_key : applied_value)
covid.head(5)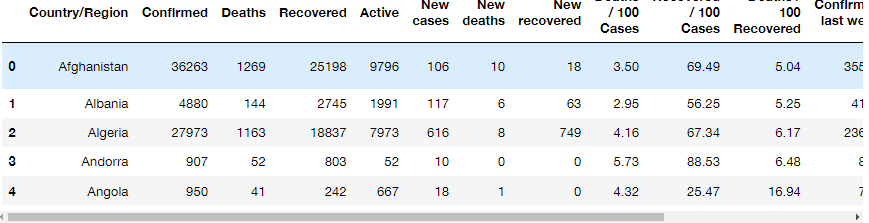
# WHO Region 별 확진자수
# 1. covid에서 확진자 수 column만 추출한다.
# 2. 이를 covid의 WHO Region을 기준으로 groupby한다.
covid_by_region = covid['Confirmed'].groupby(by=covid["WHO Region"])
covid_by_region.sum()
WHO Region
Africa 723207
Americas 8839286
Eastern Mediterranean 1490744
Europe 3299523
South-East Asia 1835297
Western Pacific 292428
Name: Confirmed, dtype: int64# 국가당 감염자 수
covid_by_region.mean() # sum() / 국가 수
WHO Region
Africa 15066.812500
Americas 252551.028571
Eastern Mediterranean 67761.090909
Europe 58920.053571
South-East Asia 183529.700000
Western Pacific 18276.750000
Name: Confirmed, dtype: float64Mission
- covid 데이터에서 100 case 대비 사망률(
Deaths / 100 Cases)이 가장 높은 국가 찾기
covid[max(covid['Deaths / 100 Cases']) == covid['Deaths / 100 Cases']]
좀 더 세련된 방법으로 접근하고 싶어서, dir을 통해 사용가능한 함수를 보니 argmax, idxmax가 있었다.
covid['Deaths / 100 Cases'].argmax()
covid['Deaths / 100 Cases'].idxmax()
184covid.iloc[covid['Deaths / 100 Cases'].idxmax(), 0]
'Yemen'- covid 데이터에서 신규 확진자가 없는 나라 중 WHO Region이 'Europe'를 모두 출력하면?
covid[covid['New cases'] == 0][covid['WHO Region'] == 'Europe']
C:\Users\Yeong\AppData\Local\Temp/ipykernel_11568/2118646714.py:1: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
covid[covid['New cases'] == 0][covid['WHO Region'] == 'Europe']동시에 두 가지 조건을 적용하자 결과가 나오기는 하는데 Warning이 발생했다. 결과는 조건을 나눠서 했을 때와 동일했다.
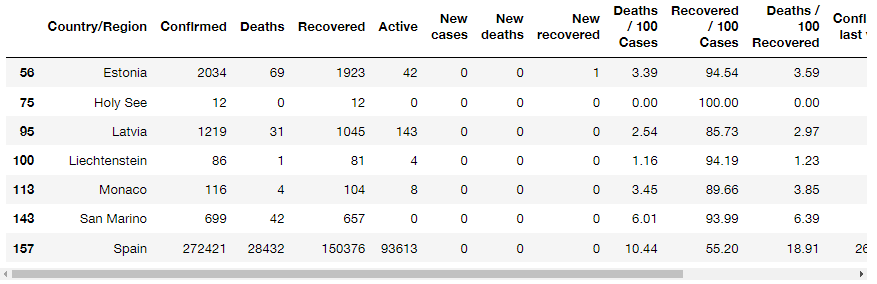
zeroCases = covid[covid['New cases'] == 0]
zeroCases[zeroCases['WHO Region'] == 'Europe']
- 다음 데이터를 이용해 각 Region별로 아보카도가 가장 비싼 평균가격(AveragePrice)을 출력하면?
avocado = pd.read_csv("./avocado.csv")
avocado_by_region = avocado['AveragePrice'].groupby(by=avocado["region"])
avocado_by_region.max()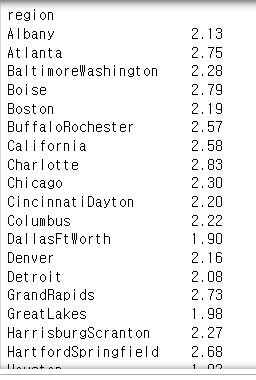
groupby로 지역별로 묶고, 묶인 AveragePrice의 max 값을 출력한다.

오래 공부하는 사람