[Kanana 429] Kanana(kakao) Ai Ecosystem Revolution: Architecture and Performance Report
kanana429

안녕하세요! 오늘은 대학생 수준에서 카카오의 AI 생태계의 진화과정 및 아키텍쳐, 성능 및 Agentic AI 구현에 대한 심층 보고서를 작성해보겠습니다!
1. 서론: 대규모 언어 모델 생태계의 패러다임 전환과 카나나(Kanana)의 등장.
현대의 대규모 언어 모델(Large Language Model, LLM) 생태계는 단순한 자연어 텍스트 생성이라는 초기 목표를 넘어, 외부 환경과 상호작용하고 스스로 논리적 추론을 전개하며 도구를 활용하는 에이전틱 AI(Agentic AI)로 빠르게 진화하고 있습니다. 이러한 거시적인 기술 패러다임의 변화 속에서 카카오(Kakao)가 자체 개발하여 공개한 이중 언어(Bilingual) 기반의 인공지능 모델 제품군인 '카나나(Kanana)'는 학계와 산업계 모두에 중요한 시사점을 제공합니다. 카나나 모델 시리즈는 단순히 파라미터의 규모를 물리적으로 확장하는 전통적인 방식을 탈피하여, 고도화된 희소 활성화(Sparse Activation) 아키텍처와 혁신적인 다단계 학습 파이프라인을 도입함으로써 컴퓨팅 연산 효율성을 극대화한 것이 특징입니다.
본 보고서는 카카오의 공식 기술 블로그인 '카나나 개발기', 허깅페이스(Hugging Face)에 공개된 모델 카드, 깃허브(GitHub)의 기술 명세 및 벤치마크 데이터를 포괄적으로 수집하여 카나나 생태계를 분석해봅니다. 특히, 기반 텍스트 처리 능력을 확립했던 1.5버전에서 자율적 추론과 도구 호출(Tool Calling) 능력이 만개한 2.0버전으로의 기술적 도약 과정을 심층적으로 추적합니다. 이와 더불어, 실제 이 생태계 내에서 AI 어시스턴트 서비스를 구축하고자 했던 현장 개발 경험을 교차 분석하여, 기업용 오픈소스 모델이 지녀야 할 실무적 가치와 한계 극복 과정을 보고서를 통해 보도록 하겠습니다.
2. 카나나 생태계의 기반: 연산 효율성 극대화를 위한 사전 학습(Pre-training) 철학
카나나 모델 제품군의 가장 근본적인 경쟁력은 사전 학습(Pre-training) 단계에서부터 컴퓨팅 자원의 투입 대비 성능 산출 비율을 극단적으로 최적화하려는 아키텍처적 의사결정에 있습니다. 카카오 기술 블로그의 개발기에 따르면, 카나나 모델은 동급 파라미터 규모를 가진 글로벌 최첨단 오픈소스 모델들과 비교할 때 학습 및 추론에 소모되는 연산 비용(Computational Cost)을 현저히 낮추는 데 집중했습니다.
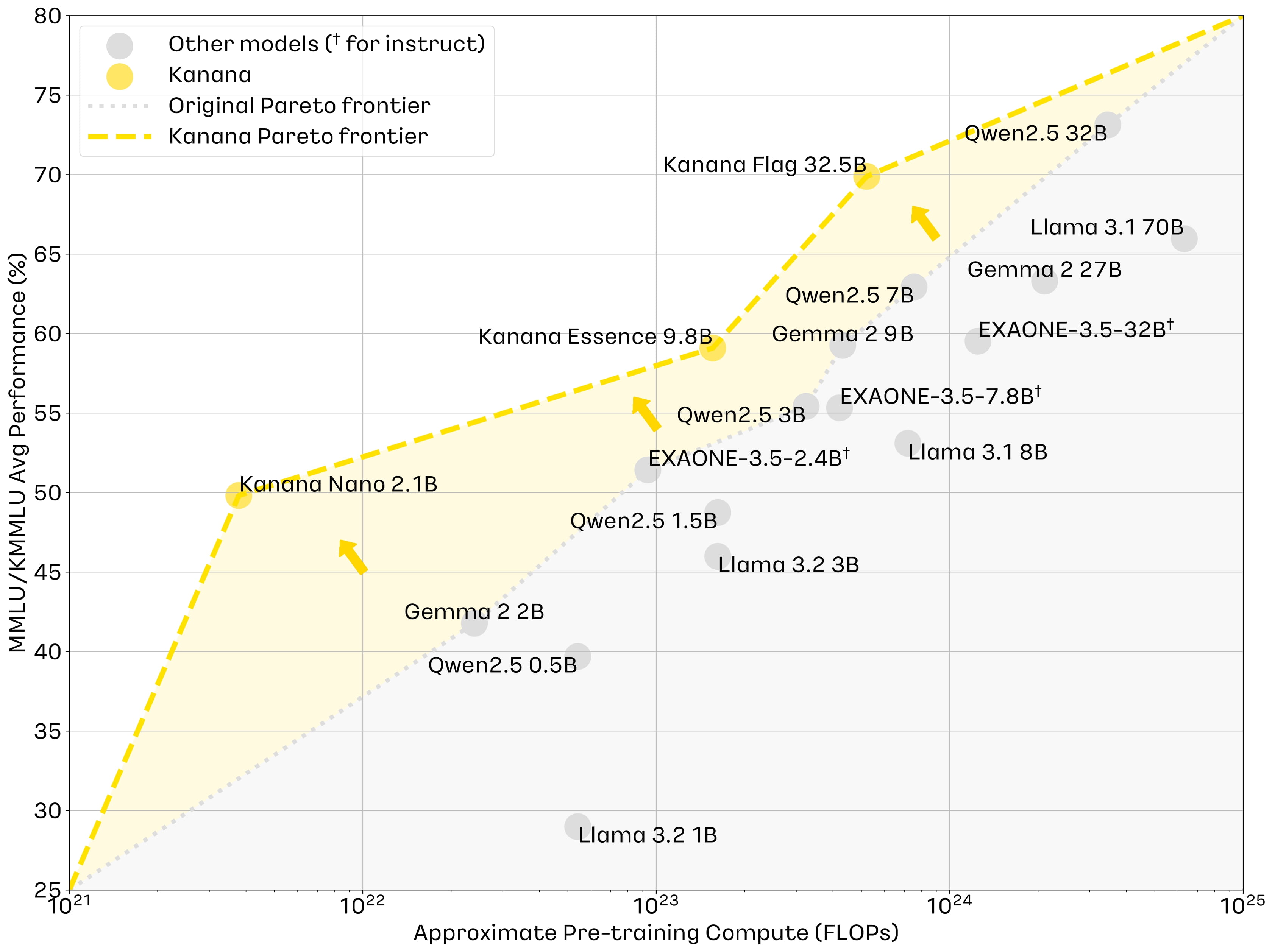
이를 달성하기 위해 카나나 연구진은 크게 네 가지의 핵심 사전 학습 기술을 도입했습니다. 첫째, 학습 코퍼스(Corpus)의 정보 밀도를 높이기 위한 고품질 데이터 필터링(High-quality data filtering)입니다. 노이즈가 섞인 방대한 데이터를 무작위로 학습시키는 대신, 정제된 지식 데이터를 선별하여 모델의 매개변수 효율성을 높였습니다. 둘째, 단계적 사전 학습(Staged Pre-training) 방법론을 채택하여 학습 커리큘럼을 모델의 인지 발달 수준에 맞게 분절화했습니다. 셋째, 모델의 아키텍처를 수직적으로 확장하는 깊이 상향 조정(Depth Up-scaling, DUS) 기법입니다. 이 기법은 비교적 작은 규모로 완전히 학습된 베이스 모델의 트랜스포머 블록을 복제하고 쌓아 올려 더 큰 모델을 초기화하는 방식으로, 8B 모델을 기반으로 9.8B 모델을, 26.8B 모델을 기반으로 32.5B 모델을 효율적으로 구축하는 데 사용되었습니다. 마지막으로, 불필요한 신경망 연결을 제거하는 프루닝(Pruning)과 대형 모델의 지식을 소형 모델로 전이하는 지식 증류(Distillation) 기법을 결합하여 경량화의 한계를 돌파했습니다.
주목할 만한 점은 이러한 방대한 사전 학습 및 이후 진행되는 사후 학습(Post-training) 데이터셋 구성 과정에서 카카오 사용자의 프라이버시를 침해할 수 있는 실제 서비스 유저 데이터는 일절 포함되지 않았다는 사실입니다. 이는 기업용 모델로서의 윤리적 신뢰성을 담보하는 중요한 조치로 평가받습니다.
3. 카나나 1.5 시대: 복잡한 문맥 처리와 MoE 구조의 성공적 안착
2025년 5월 말부터 순차적으로 공개된 카나나 1.5 시리즈는 카카오가 오픈소스 AI 생태계에 본격적으로 영향력을 행사하기 시작한 전환점입니다. 1.5버전의 핵심 개발 목표는 단순한 일상 대화를 넘어 수학적 연산, 프로그래밍 코드 작성, 그리고 함수 호출 능력을 대폭 향상시켜 실세계의 복잡한 비즈니스 문제를 해결할 수 있는 기초를 마련하는 것이었습니다.
3.1. 다양한 스케일의 모델 라인업과 15.7B-A3B의 혁신
카나나 1.5 생태계는 하드웨어 환경과 서비스 목적에 따라 선택할 수 있는 다양한 규모의 모델 라인업을 제공했습니다. 온디바이스(On-device) 및 엣지 컴퓨팅 환경을 겨냥한 Nano 크기의 2.1B 및 3B 모델부터, 일반적인 서버 환경에서 다목적으로 활용 가능한 8B 밀집형(Dense) 모델, 그리고 고도의 언어 이해력을 갖춘 32.5B Flag 모델이 공개되었습니다.
이 라인업 중에서도 학계와 산업계의 가장 큰 주목을 받은 것은 2025년 7월에 공개된 Kanana-1.5-15.7B-A3B 모델입니다. 이 모델은 카나나 제품군 최초로 전문가 혼합(Mixture-of-Experts, MoE) 아키텍처를 도입했습니다. MoE 구조의 핵심은 모든 매개변수가 입력 토큰마다 활성화되는 밀집형(Dense) 모델과 달리, 입력된 데이터의 특성에 따라 전체 네트워크 중 극히 일부의 '전문가' 네트워크만을 선택적으로 활성화하는 희소(Sparse) 아키텍처라는 점입니다.
3.2 Mixture of Experts (MoE) 모델이 왜 필요한가?
일반적인 대규모 언어 모델 (LLM), 소위 “Dense 모델”은 입력된 데이터를 처리하기 위해 모든 파라미터가 연산에 참여하여 출력을 만들게 됩니다. 저희 조직에서 앞서 오픈소스로 공개했던 Kanana-1.5-8B, Kanana-1.5-2.1B 같은 모델들이 여기에 해당합니다. Dense 구조를 갖는 경우 언어 모델의 파라미터 규모가 클수록 더 많은 지식을 저장할 수 있어 성능이 향상되는 장점이 있지만, 한편으로는 파라미터 규모에 비례하여 연산량이 같이 증가한다는 명백한 한계가 존재합니다. 따라서 모델이 커질 경우 추론 시에 사용되는 장비의 부담과 비용이 늘어나기 때문에, 모델 성능을 높이기 위해서 무한정 파라미터 수를 늘리는 것은 현실적으로 거의 불가능합니다.
이러한 Dense 구조의 큰 모델이 갖는 한계를 보완하면서도 모델의 수용 가능한 지식의 총량을 확장하기 위해 MoE 구조가 활용될 수 있습니다. MoE 구조의 언어 모델은 전체 파라미터 중 주어진 입력에 가장 적합한 일부 전문가 (expert) 파라미터들을 선별적으로 활성화하여 추론에 필요한 연산을 진행합니다. 이러한 특징을 가지는 MoE 모델은 크게 두 가지 목적으로 활용될 수 있습니다.
-
초거대 모델 학습 : Dense 구조로는 현실적으로 초거대 규모의 모델을 만드는 것에 무리가 있지만, MoE 구조를 채택한다면 가능합니다. 대표적인 예시로, DeepSeek-V3 (671B 파라미터 중 37B 활성화), Qwen3-235B-A22B (235B 파라미터 중 22B 활성화), Llama 4 Maverick (400B 파라미터 중 17B 활성화) 같은 모델들은 MoE 구조 덕분에 엄청난 수의 전체 파라미터로 지식의 총량은 확장하면서도 추론에 사용되는 연산에는 일부만 사용하면서 부담을 줄여 강력한 성능을 갖는 거대 모델을 구현할 수 있었습니다.
-
추론 비용 효율화 : 모델의 절대적인 사이즈를 확장하는 용도 외에도, 성능을 유지하되 추론 비용 효율화를 위해서도 MoE 구조가 활용될 수 있습니다. 모델을 실제로 사용할 때 모든 파라미터가 연산에 사용되는 Dense 구조의 모델과 달리, MoE 모델은 필요한 일부 파라미터만 선별적으로 연산에 참여하게 되므로 모델 커널 최적화만 충분히 되어있다면 추론 비용을 크게 절약할 수 있습니다. 약 10B 규모의 성능을 보이는 알리바바 그룹의 Qwen3-30B-A3B 모델이 이런 목적에 해당된다고 볼 수 있습니다.
이번에 소개해드릴 Kanana-1.5-15.7B-A3B 모델은 위 내용 중 두 번째 목적인 추론 비용 효율화에 중점을 두었습니다. 앞서 공개되었던 Kanana-1.5-8B 모델에 버금가는 성능을 보이면서도, 추론 연산에는 2~3배 적은 활성 파라미터만을 사용하여 높은 효율을 달성하는 것이 이번 모델(kanana-1.5-15.7B-A3B)의 목표였습니다.
3.3 Mixture of Experts (MoE)를 왜하는가?
37%의 파라미터 만으로 성능 따라잡기
구체적으로 15.7B-A3B 모델은 총 157억 개의 파라미터를 가지고 있지만, 실제 추론 과정에서는 8개의 전문가 중 일부만 작동하여 단 30억(3B) 개의 활성 파라미터만을 사용합니다. 깃허브에 명시된 기술 지표에 따르면, 이 모델은 8B 밀집형 모델과 대등하거나 이를 상회하는 벤치마크 성능을 기록하면서도 토큰당 소모되는 연산량(FLOPS)은 8B 모델의 37% 수준에 불과합니다. 이는 클라우드 인프라 유지 비용을 극적으로 절감하면서도 높은 동시 접속 처리량(Throughput)을 확보해야 하는 실제 서비스 환경에서 매우 비용 효율적인 솔루션으로 자리 잡았습니다.
그러나 방대한 API 명세서나 법률 문서 등을 처리하기 위해 카카오 연구진은 허깅페이스 모델의 config.json 설정을 통해 YaRN(Yet another RoPE extensioN) 기법을 적용할 수 있는 길을 열어두었습니다. 회전 위치 임베딩(Rotary Position Embedding, RoPE)의 고주파 및 저주파 차원을 보간(Interpolation)하는 YaRN 기술을 적용하면, 사용자는 모델의 재학습 없이도 rope_scaling의 계수(factor)를 4.4로 조정하여 최대 128,000 토큰(128K) 길이의 입력 시퀀스를 일관성 있게 처리할 수 있습니다. 이 기술적 진보는 모델이 단기 기억 상실증에 걸리지 않고 방대한 데이터를 기반으로 근거 있는 답변을 생성할 수 있게 만들었습니다.
3.4 멀티모달 영역으로의 확장
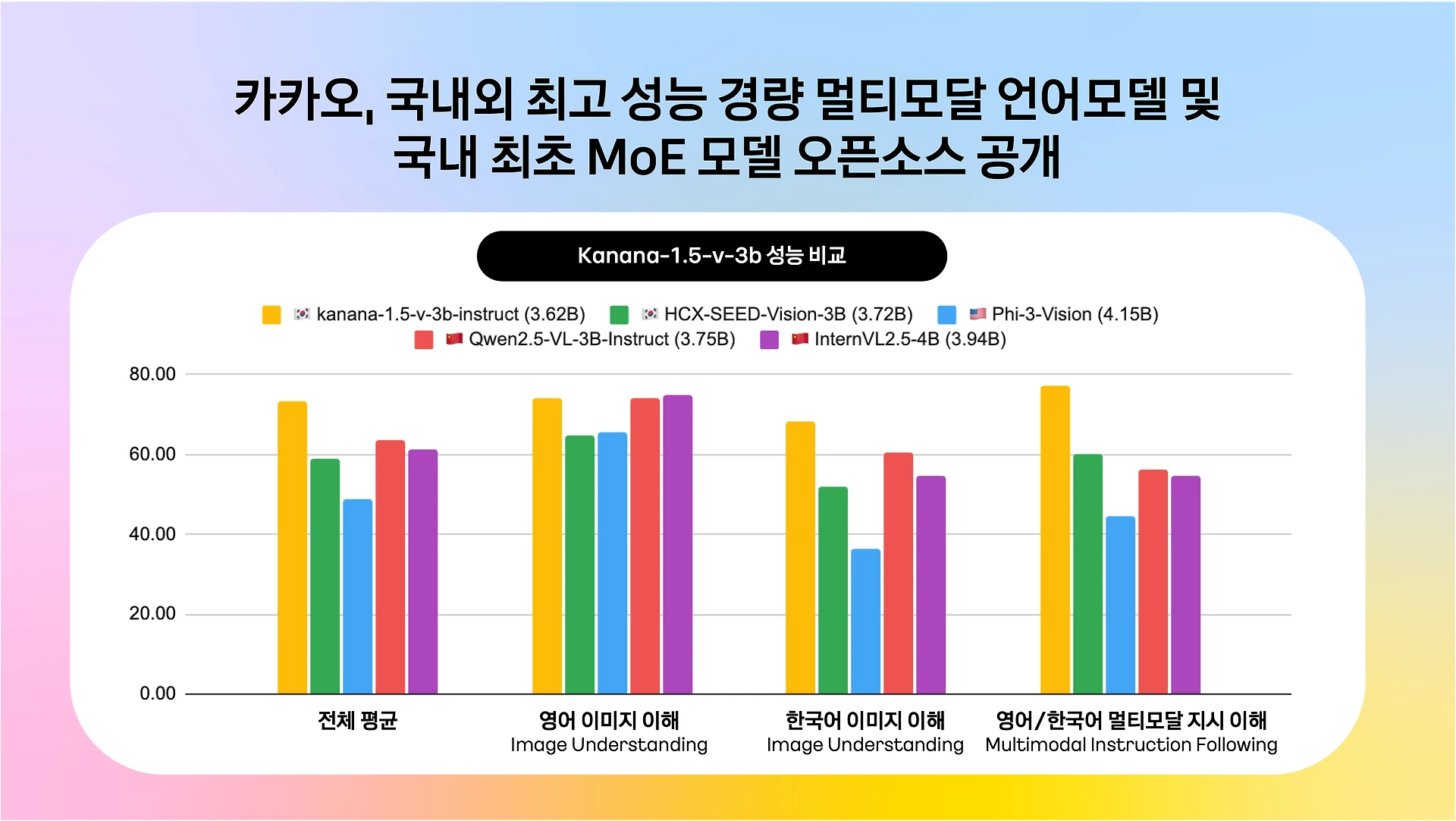
텍스트 처리 역량 강화와 더불어, 카카오는 카나나 1.5 아키텍처를 기반으로 시각 정보를 처리할 수 있는 경량 멀티모달 언어 모델(MLLM)인 Kanana-1.5-v-3b를 시장에 선보였습니다. 이 모델은 텍스트 프롬프트와 이미지 입력을 동시에 처리하여 자연어 또는 정형화된 JSON 형태로 답변을 출력할 수 있으며, 이미지 내 특정 객체를 인식하거나 데이터 표를 분석하는 시각적 추론 영역에서 동급 국내외 모델 대비 압도적인 성능 지표(128% 향상된 지시 이행 능력)를 기록하며 에이전트의 감각 기관을 성공적으로 확장했습니다.
4. 사용자(개발자)의 현장 도입 사례: 1.5버전의 실무적 한계와 생태계의 격변
기술의 객관적 지표와 실제 운영 환경에서의 체감 성능 사이에는 종종 간극이 존재합니다. 본 보고서를 의뢰한 사용자(이하 '개발자')는 기업 내부의 복잡한 데이터베이스와 연동되어 사내 구성원들의 질의응답 및 업무 자동화를 수행하는 맞춤형 AI 어시스턴트(사내 에이전트)를 개발하는 과정에서 카나나 생태계를 깊숙이 경험했습니다.
프로젝트 초기, 개발자는 오픈소스로 풀린 Kanana-1.5-8B-Instruct 모델을 로컬 환경에 배포하여 테스트를 진행했습니다. 이 모델은 한국어 성능이 뛰어났고 YaRN을 통한 128K 컨텍스트 확장이 가능했기에 방대한 사내 가이드라인 문서를 프롬프트 컨텍스트에 삽입하는 데 무리가 없었습니다. 그러나 고도화된 에이전트 환경을 구축하려 하자 치명적인 병목 현상에 직면했습니다. 사용자의 질의가 복잡해짐에 따라 AI가 단일 도구 호출(Single Tool Call)을 넘어 여러 개의 API를 순차적으로 혹은 병렬적으로 호출(Parallel Tool Calling)해야 하는 상황이 발생했는데, 1.5버전의 모델은 이러한 다중 도구 호출 환경에서 API 파라미터를 누락하거나 지정된 JSON 포맷을 어기는 환각(Hallucination) 현상을 종종 보였습니다. 지시 이행(Instruction Following) 능력이 1차원적인 대화에서는 훌륭했으나, 엄격한 코드 실행 환경에서는 한계점을 노출한 것입니다.
설상가상으로, 개발자는 외부 인프라 환경의 급격한 변화라는 또 다른 변수에 부딪혔습니다. 카카오는 본래 if(kakao)25 컨퍼런스 전후로 다양한 AI 메이트들이 활동할 수 있는 거대한 중앙집중형 '카나나 메이트 플랫폼(초개인화 그룹 AI 환경)'을 기획 및 테스트 중이었습니다. 개발자 역시 이 중앙 플랫폼의 API를 활용해 에이전트를 종속적으로 연동하려는 계획을 세웠으나, 시장 환경이 급변함에 따라 카카오는 해당 중앙 플랫폼 개발을 중단하고 개별 개발자들이 각자의 에이전트를 독자적으로 구축하고 운영하는 탈중앙화된 생태계로 방향을 급선회했습니다.
이러한 플랫폼 전략의 전면 수정은 개발자에게 엄청난 과제를 안겨주었습니다. 거대 플랫폼의 인프라 지원 없이, 한정된 사내 GPU(예: 단일 Nvidia A100) 환경에서 복잡한 다중 도구 호출과 완벽한 지시 이행 능력을 갖춘 무거운 에이전트를 자체적으로 호스팅해야 했기 때문입니다. 1.5버전의 8B 혹은 15.7B 모델로는 복잡한 자율 추론을 완벽히 소화하기 어려웠고, 32.5B Flag 모델은 메모리 용량 제한으로 인해 단일 GPU에서 쾌적한 추론 속도를 확보하기 불가능했습니다. 개발자는 극단적인 연산 효율성과 최고 수준의 추론 능력이 결합된 완전히 새로운 형태의 폼팩터가 절실히 필요한 상황에 놓이게 되었습니다.
5. 카나나 2.0 혁명: 에이전틱 AI를 향한 아키텍처와 추론 메커니즘의 재설계
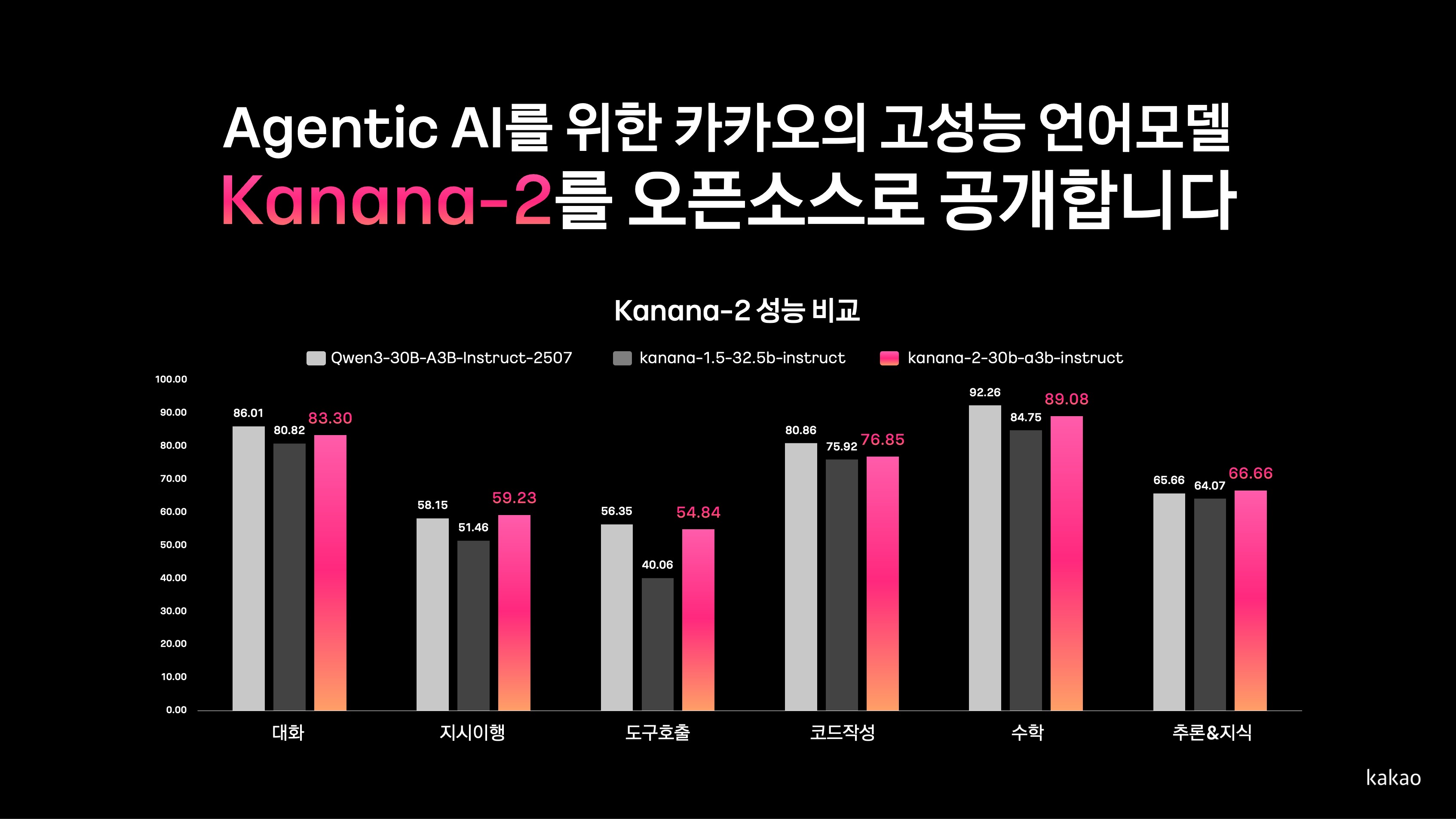
2025년 12월 말부터 2026년 1월에 걸쳐 카카오는 단순한 버전 업데이트를 넘어선 구조적 혁신을 담은 카나나 2.0(Kanana-2) 생태계를 전격 공개했습니다. 개발자가 직면했던 실무적 난제들을 마치 예견이라도 한 듯, 카나나 2.0은 대화형 챗봇의 굴레를 벗어나 사용자의 의도를 분석하고 논리적으로 행동 계획을 수립하며 도구를 선택하는 '완전한 AI 에이전트'로의 진화를 선포했습니다.
5.1. 30B-A3B의 혁신적 구조: 최적화된 MoE와 MLA의 만남
카나나 2.0 생태계의 중심에는 허깅페이스에 공개된 kanana-2-30b-a3b 아키텍처가 자리하고 있습니다. 이 모델은 총 300억(30B) 개의 파라미터를 품고 있으나, 추론 시 활성화되는 파라미터는 단 30억(3B) 개에 불과합니다. 이전 세대의 15.7B-A3B 모델보다 총 지식의 저장소(Total Parameters)는 두 배 가까이 늘려 지식의 깊이를 더했으면서도, 연산 비용의 기준이 되는 활성 파라미터는 여전히 3B 수준으로 동결시킴으로써 극단적인 연산 효율성을 달성했습니다.
모델의 내부 구조를 살펴보면, 총 48개의 레이어로 구성되어 있으며 초기 표현 공간을 형성하는 단 1개의 밀집형(Dense) 레이어를 제외한 나머지 레이어는 모두 전문가 네트워크로 구성되어 있습니다. 총 128개의 전문가가 존재하며, 라우터 신경망은 매 토큰마다 이 중 6개의 가장 적합한 전문가를 선택(Selected Experts)합니다. 여기에 언어의 보편적 문법이나 공통된 문맥 정보를 잃지 않도록 항상 활성화되는 2개의 공유 전문가(Shared Experts)를 배치하여, MoE 모델이 흔히 겪는 지식의 단절 현상을 방지했습니다.
아키텍처 혁신의 정점은 어텐션 메커니즘의 교체입니다. 카나나 2.0은 기존의 다중 헤드 어텐션(Multi-Head Attention) 대신 다중 헤드 잠재 어텐션(Multi-Head Latent Attention, MLA) 구조를 전격 채택했습니다. 기존 모델들은 입력 문맥이 길어질수록 키-값 캐시(Key-Value Cache, KV Cache)가 기하급수적으로 팽창하여 GPU의 VRAM을 고갈시키는 고질적인 문제가 있었습니다. 그러나 MLA는 이 방대한 KV 상태를 저차원의 잠재 벡터 공간(Latent Vector Space)으로 압축하여 캐시 메모리 사용량을 비약적으로 감소시킵니다. 이 기술 덕분에 개발자와 같은 사용자는 값비싼 클러스터 인프라 없이도, 엔비디아(Nvidia) A100 수준의 범용 GPU 단일 환경에서 긴 문맥을 가진 무거운 에이전트 모델을 놀라운 속도로 서빙(Serving)할 수 있게 되었습니다.
5.2. 글로벌 다국어 지원과 토크나이저(Tokenizer) 효율의 극대화
에이전트가 처리해야 할 정보의 영역이 전 세계로 확장됨에 따라, 카나나 2.0은 한국어와 영어를 넘어 일본어, 중국어, 태국어, 베트남어까지 총 6개 국어를 완벽히 지원하는 글로벌 모델로 발돋움했습니다. 지원 언어의 확장은 필연적으로 어휘집(Vocabulary)의 확장을 요구합니다. 카카오는 128,256개의 어휘 크기를 가진 완전히 새로운 토크나이저를 바닥부터 다시 학습시켰습니다.
이 신규 토크나이저는 특히 한국어 처리 영역에서 기존 버전 대비 토큰화 효율을 30% 이상 향상시키는 놀라운 성과를 보였습니다. 토큰화 효율이 30% 증가했다는 것은, 동일한 길이의 한국어 텍스트를 표현하는 데 필요한 토큰의 수가 30% 줄어들었다는 것을 의미합니다. 개발자의 입장에서 이는 제한된 32,768 토큰의 네이티브 문맥 창(Context Length) 안에 기존보다 30% 더 많은 사내 데이터베이스 로그나 API 명세서를 욱여넣을 수 있게 되었음을 의미하며, 동시에 텍스트 생성 속도가 실질적으로 30% 빨라지는 부수적 효과까지 창출했습니다.
6. 카나나 개발기 분석: 미드 트레이닝(Mid-training)과 치명적 망각의 극복
카나나 2.0이 이전 모델들이나 타사의 경쟁 모델들과 구별되는 가장 결정적인 차별점은 바로 '미드 트레이닝(Mid-training)'이라는 혁신적인 학습 파이프라인의 도입입니다. 카카오 AI 연구진이 기고한 기술 블로그 'Kanana-2 개발기 (2): 개선된 post-training recipe를 중심으로'를 면밀히 분석해보면, 모델이 복잡한 논리적 추론 능력과 코딩 능력을 획득하는 과정에서 겪는 치열한 기술적 고뇌를 엿볼 수 있습니다.
일반적인 언어 모델은 거대한 코퍼스를 바탕으로 세상의 지식을 흡수하는 사전 학습(Pre-training)과 인간의 지시를 따르도록 미세 조정하는 사후 학습(Post-training, SFT 및 RL) 두 단계로 나뉩니다. 그러나 단순 대화형 AI가 아닌 논리적 추론이 가능한 에이전틱 AI를 만들기 위해서는 고도의 수학 및 코드 데이터에 대한 집중적인 학습이 필요합니다. 연구진은 사전 학습 직후 본격적인 미세 조정을 수행하기 전, 모델의 인지적 잠재력을 폭발적으로 끌어올리는 중간 교량 역할로 'Mid-training' 단계를 새롭게 설계했습니다.
이 딜레마를 해결하기 위해 연구진은 '데이터 리플레이(Data Replaying)' 전략을 구사했습니다. 총 2500억(250B) 토큰의 미드 트레이닝 데이터셋을 구성할 때, 200B 토큰의 영어 추론 데이터에 더해 기존 사전 학습에 사용되었던 고품질 한국어 데이터 50B 토큰을 일정 비율로 섞어 다시 학습시킨 것입니다. 이 정교한 리플레이 믹스(Replay Mix)를 통해 카나나 2.0은 한국어 지식을 온전히 보존하면서도 글로벌 최고 수준의 수학 및 코딩 추론 능력을 뇌쇄적으로 각인시키는 데 성공했습니다. 연구진의 회고에 따르면, 이 미드 트레이닝을 거친 베이스 모델은 이후 인스트럭트(Instruct) 학습 단계에서 비교할 수 없이 빠른 수렴(Convergence) 속도를 보였으며, 코딩 능력을 측정하는 HumanEval이나 수학 능력을 측정하는 MATH 벤치마크에서 비약적인 성능 향상을 이뤄냈습니다.
7. 지시 이행과 도구 호출을 완성한 사후 학습(Post-training) 레시피
에이전트가 현실 세계에서 동작하기 위해서는 논리적 사고력을 바탕으로 인간의 까다로운 제약 조건(길이 제한, 특정 단어 금지, 출력 포맷 준수 등)을 지키고, 외부 API 도구를 적재적소에 호출하는 능력이 필수적입니다. 카카오 연구진은 이를 위해 사후 학습 파이프라인을 극한으로 끌어올렸습니다.
7.1. 데이터 통합(Supplementation) 전략
연구진은 기존 카나나 1.5버전에서 사용했던 지시어 데이터셋을 무작정 버리고 오픈소스(예: Nemotron 등)의 고품질 데이터로 교체(Replacement)하는 쉬운 길을 택하지 않았습니다. 대신 기존 데이터에 새로운 데이터를 유기적으로 결합하는 '통합(Supplementation)' 전략을 통해, 부드럽고 자연스러운 대화 페르소나와 딱딱하지만 정확한 지시 이행 능력 사이의 절묘한 균형을 찾아냈습니다.
7.2. 병렬 강화학습(Parallel RL) 파이프라인
특히 주목할 부분은 인간의 선호도에 모델의 출력을 정렬하는 강화학습 단계입니다. 카나나 2.0은 두 가지 서로 다른 강화학습 방법론을 병렬적으로 수행하는 하이브리드 접근법을 취했습니다. 주관적인 선호도가 작용하는 인간과의 대화 스타일 교정에는 자원 효율적인 DPO(Direct Preference Optimization)를 적용했습니다. 그러나 수학 문제를 풀거나 코드를 작성하는 것처럼 '정답이 명확하게 존재하는' 객관적인 추론의 영역에서는 DPO만으로 한계가 있었습니다. 이를 극복하기 위해 정답을 맞혔을 때 명시적인 보상을 부여하여 모델의 논리 회로를 강화하는 PPO(Proximal Policy Optimization) 알고리즘을 병행 적용했습니다. 이 병렬 강화학습 파이프라인의 결과로, 카나나 2.0은 친절한 비서의 말투를 유지하면서도 백엔드에서는 한 치의 오차 없이 코드를 컴파일하고 수학 공식을 증명하는 양면성을 갖추게 되었습니다.
이러한 사후 학습의 결과는 도구 호출(Tool Calling) 능력의 극적인 상승으로 나타났습니다. 벤치마크 결과에 따르면 카나나 2.0은 단일 도구 호출은 물론이고, 사용자의 다중 요구사항을 분석해 병렬적으로 여러 API를 호출하는 능력이 1.5버전 대비 무려 3배 이상 향상되는 쾌거를 이루었습니다.
8. 성능 평가: 1.5버전에서 2.0버전으로의 비약적 상승 수치 분석
객관적인 벤치마크 수치들은 아키텍처 혁신과 미드 트레이닝의 성과를 명확하게 증명합니다. 깃허브 및 허깅페이스에 공개된 오픈소스 베이스(Base) 모델의 주요 성능을 비교하면 다음과 같습니다.
| 벤치마크 (측정 영역) | 평가 방법 | Kanana-1.5-8B (Dense) | Kanana-1.5-15.7B-A3B | Kanana-2-30B-A3B |
|---|---|---|---|---|
| MMLU (대규모 다중작업 언어 이해) | 5-shot acc | 64.24 | 64.79 | 75.44 |
| KMMLU (한국어 지식 및 이해) | 5-shot acc | 48.94 | 51.77 | 62.15 |
| HumanEval (파이썬 코드 생성) | 0-shot pass@1 | 61.59 | 59.76 | 75.29 |
| MBPP (기본 파이썬 프로그래밍) | 3-shot pass@1 | 57.80 | 60.10 | 62.39 |
| GSM8K (초등학교 수준 수학 추론) | 5-shot em | 63.53 | 61.18 | 82.71 |
데이터 출처: 카카오 카나나 오픈소스 깃허브 및 2.0 베이스 모델 카드 지표
위 표에서 가장 돋보이는 부분은 수학(GSM8K)과 코딩(HumanEval) 영역에서의 폭발적인 성장입니다. 1.5버전에서 60점대 초반에 머물렀던 GSM8K 점수가 2.0 베이스 모델에서 82.71점 수직 상승한 것은, 미드 트레이닝 단계에서 주입된 200B 규모의 추론 데이터가 베이스 모델의 잠재력을 완전히 재구성했음을 시사합니다. 또한 한국어 역량 측정 지표인 KMMLU 역시 13점 이상 상승하며, 데이터 리플레이 전략이 치명적 망각을 막는 것을 넘어 기존 언어 능력까지 동반 상승시켰음을 입증합니다.
9. 생각의 사슬(CoT)을 완성한 'Thinking' 모델과 글로벌 최고 수준과의 경쟁
카나나 2.0 라인업의 백미는 단연 새롭게 추가된 '추론 특화 모델', 즉 kanana-2-30b-a3b-thinking 모델입니다. 이 모델은 사용자가 복잡한 수학, 논리 퍼즐, 혹은 심층적인 코드 디버깅을 요구할 때 즉시 답을 내뱉는 일반적인 자기회귀(Auto-regressive) 생성 방식을 멈춥니다. 대신 내부적으로 '생각의 사슬(Chain of Thought, CoT)'을 전개하여 문제를 여러 하위 단계로 쪼개고, 각 단계의 논리적 무결성을 스스로 검증하는 사고 과정을 거친 후 최종 정답을 도출합니다. 이러한 메커니즘은 OpenAI의 GPT-4o o1 시리즈나 알리바바의 Qwen3-Thinking 모델이 사용하는 최신 추론 기법과 그 궤를 같이합니다.
이 Thinking 모델의 진가는 초고난도의 글로벌 벤치마크에서 여실히 드러납니다.
| 벤치마크 (측정 영역) | Kanana-2-30B-A3B-Thinking | Qwen3-30B-A3B-Thinking | GPT-4o (Nov '24, 참조 지표) |
|---|---|---|---|
| MMLU-Pro (고난도 다중작업 이해) | 75.3 | 78.5 | - |
| GPQA Diamond (전문가급 학문 지식) | 61.3 | 62.6 | - |
| AIME 2024 (미국 수학 경시대회 최고난도) | 78.3 | 82.7 | - |
| AIME 2025 (미국 수학 경시대회 최신) | 72.7 | 70.7 | - |
| LiveCodeBench (최신 프로그래밍 문제) | 60.8 | 62.3 | - |
| IFEval (엄격한 프롬프트 지시 이행) | 82.2 | 86.1 | - |
데이터 출처: 카나나 2.0 Thinking 허깅페이스 평가 지표 및 AI 벤치마크 비교 사이트 https://huggingface.co/kakaocorp/kanana-2-30b-a3b-thinking
동일한 파라미터 규모(30B-A3B)를 가진 글로벌 탑티어 오픈소스 모델인 Qwen3-Thinking과 비교했을 때, 카나나 2.0 Thinking 모델은 오차 범위 내의 치열한 성능 경합을 벌이고 있습니다. 특히 최신 수학 경연 문제인 AIME 2025에서는 오히려 Qwen3를 상회하는 72.7점의 경이로운 정답률을 기록하며, 카카오의 미드 트레이닝 및 PPO 기반 강화학습 파이프라인이 글로벌 최고 수준에 도달했음을 객관적으로 입증했습니다.
또한, 에이전트의 생명인 도구 호출 능력에 대한 평가 지표인 버클리 함수 호출 리더보드(BFCL-v3)에서 Thinking 모델은 라이브 환경(Live) 75.6점, 다중 턴(Multi-Turn) 34.3점을 기록하여 복잡한 현실 세계의 API를 순차적으로 제어하는 데 무리가 없음을 확인시켜 주었습니다.
앞서 언급했던 사용자의 개발 사례로 돌아가 보면, 카나나 2.0 생태계의 도입은 위기에 빠졌던 사내 에이전트 프로젝트를 극적으로 구원하는 열쇠가 되었습니다. 개발자는 중앙 플랫폼의 지원 없이도, 허깅페이스에 공개된 30B-A3B-Thinking 모델의 가중치를 다운로드하여 단일 A100 GPU 환경에 자체 호스팅했습니다. MLA 구조 덕분에 메모리 초과 없이 다중 접속 요청을 가볍게 처리할 수 있었으며, 30% 향상된 토크나이저 효율 덕분에 사내 데이터베이스의 방대한 검색 결과(RAG)를 넉넉하게 프롬프트에 담을 수 있었습니다.
무엇보다 놀라운 변화는 도구 호출 과정에서 나타났습니다. 사용자가 "어제 서버 오류 로그를 조회하고, 동일 오류가 난 과거 이력을 찾아 요약 리포트를 메일로 전송해 줘"라는 복잡한 다중 지시를 내리면, Thinking 모델은 내부적인 사고 체인(CoT)을 가동했습니다. 먼저 로그 조회 API를 호출할 계획을 세우고 정확한 JSON 파라미터를 생성하여 실행한 뒤, 반환된 값을 분석하여 과거 이력 검색 API를 두 번째로 호출하고, 최종적으로 이메일 발송 API 툴을 실행하는 일련의 과정을 완벽히 자율적으로 수행해 냈습니다. 1.5버전에서는 포맷 에러로 번번이 실패했던 이 작업이, 2.0버전의 병렬 강화학습과 추론 능력 강화 덕분에 완벽한 에이전트 워크플로우로 실현된 것입니다.
10. 결론 및 카나나 생태계의 향후 전망
카카오의 카나나(Kanana) AI 생태계가 1.5버전에서 2.0버전으로 진화하며 보여준 기술적 궤적은 현대 인공지능 산업이 나아가야 할 명확한 이정표를 제시합니다. 1.5버전이 YaRN 기술을 통한 초장기 문맥(128K) 처리와 MoE 아키텍처의 가능성을 타진하며 텍스트 기반 거대 언어 모델의 기초 체력을 다졌다면 , 2.0버전은 이러한 기초 위에 에이전틱 AI라는 날개를 달아주었습니다.
2.0버전의 성취는 결코 우연이 아닙니다. VRAM 병목 현상을 해소하기 위한 과감한 다중 헤드 잠재 어텐션(MLA)의 도입, 6개 국어를 지원하면서도 한국어 효율을 30% 끌어올린 맞춤형 토크나이저 개발, 그리고 무엇보다 200B 규모의 추론 데이터와 50B 규모의 리플레이 데이터를 배합하여 치명적 망각을 우회한 창조적인 미드 트레이닝(Mid-training) 기법은 카카오 연구진의 집요한 엔지니어링 역량의 결정체입니다. 여기에 인간의 선호도(DPO)와 객관적 논리(PPO)를 동시에 교정하는 병렬 강화학습 파이프라인을 더함으로써, 지시를 정확히 이행하고 도구를 능숙하게 다루는 30B-A3B-Thinking 모델이 탄생할 수 있었습니다.
카나나 2.0의 오픈소스 공개 정책은 단일 A100 GPU 정도의 범용 인프라만 갖춘 중소기업이나 독립 개발자들도 고성능 자율 추론 에이전트를 독자적으로 구축할 수 있는 민주적인 토대를 마련했습니다. 본 보고서에서 추적한 사용자의 현장 사례가 증명하듯, 카카오의 탈중앙화된 모델 배포 전략은 개발자들이 플랫폼에 종속되지 않고 스스로 문제를 정의하고 해결하는 생태계의 자생력을 키우는 데 크게 기여하고 있습니다.
현재 카카오 연구진은 30B-A3B 아키텍처에서 검증된 미드 트레이닝과 추론 학습 레시피를 기반으로, 무려 1,550억(155B) 개의 파라미터와 170억(17B) 개의 활성 파라미터를 지닌 초대형 155B-A17B 모델을 학습 중인 것으로 알려져 있습니다. MoE 및 MLA 구조의 스케일링 법칙(Scaling Law)이 이 거대한 규모에서도 변함없이 적용된다면, 다가올 초대형 카나나 모델은 연산 비용의 극단적인 효율성을 유지하면서도 글로벌 최고 수준의 폐쇄형(Proprietary) 모델들을 직접적으로 위협하는 강력한 오픈소스 AI 기반 인프라로 자리매김할 것입니다. 카나나 생태계는 단순히 '말을 잘하는' AI를 넘어, 세계의 정보를 탐색하고 복잡한 시스템을 '조작(Operate)'하는 진정한 의미의 에이전틱 시대를 열어가고 있습니다.
11. 참고 자료
kakaocorp/kanana-nano-2.1b-instruct - Hugging Face, https://huggingface.co/kakaocorp/kanana-nano-2.1b-instruct
Kakao updates Kanana-2, releases 4 open-source models - The Korea Times, https://www.koreatimes.co.kr/business/tech-science/20260120/kakao-updates-kanana-2-releases-4-open-source-models
kakao/kanana: Kanana: Compute-efficient Bilingual ... - GitHub, https://github.com/kakao/kanana
카나나 - 나무위키, https://namu.wiki/w/%EC%B9%B4%EB%82%98%EB%82%98
Kanana-2 개발기 (2): 개선된 post-training recipe를 중심으로 | Techlist.io, https://www.techlist.io/posts/28096d9e230fa750b6affee4eb84dc9ef3c534bd
Kanana: Compute-efficient Bilingual Language Models - arXiv, https://arxiv.org/html/2502.18934v1
Kakao Releases One of the World's Highest-Performing Multimodal Language Model and Becomes First in Korea to Launch Open Source MoE Model | Kakao, https://www.kakaocorp.com/page/detail/11671?lang=ENG
Kakao releases top-performing lightweight MLLM, MoE AI models - The Korea Times, https://www.koreatimes.co.kr/business/tech-science/20250724/kakao-releases-top-performing-lightweight-mllm-moe-ai-models
kakaocorp/kanana-1.5-8b-base - Hugging Face https://huggingface.co/kakaocorp/kanana-1.5-8b-base
Kanana 1.5 | AI Model | There's An AI For That, https://theresanaiforthat.com/model/kanana-1-5/
카나나 앱 메이트 개발기 - YouTube, https://www.youtube.com/watch?v=V-jlscSg_AA
더 똑똑하고 효율적인 Kanana-2 오픈소스 공개 - tech.kakao.com, https://tech.kakao.com/posts/804
Kakao Updates Kanana-2 with 4 New Free Versions - Coherent Market Insights, https://www.coherentmarketinsights.com/news/kakao-updates-kanana-2-with-4-new-free-versions-2255
kakaocorp/kanana-2-30b-a3b-thinking · Hugging Face, https://huggingface.co/kakaocorp/kanana-2-30b-a3b-thinking
Kakao updates Kanana-2, expands open-source push with four new AI models, https://koreatechtoday.com/kakao-updates-kanana-2-expands-open-source-push-with-four-new-ai-models/
카카오, 에이전틱 AI 특화 'Kanana-2' 오픈소스 공개 - 리얼뉴스,https://www.realnews.co.kr/news/articleView.html?idxno=30526
kakaocorp/kanana-2-30b-a3b-instruct - Hugging Face https://huggingface.co/kakaocorp/kanana-2-30b-a3b-instruct
kakaocorp/kanana-2-30b-a3b-thinking-2601 - Hugging Face, https://huggingface.co/kakaocorp/kanana-2-30b-a3b-thinking-2601
Compare GPT-4o vs GPT-4o1 vs O1-Mini: How to Choose - Galileo AI, https://galileo.ai/blog/gpt-4o-vs-gpt-4o1-vs-o1-mini
Qwen3 30B A3B 2507 (Reasoning) vs GPT-4o (Nov '24): Model Comparison, https://artificialanalysis.ai/models/comparisons/qwen3-30b-a3b-2507-reasoning-vs-gpt-4o
LICENSE · kakaocorp/kanana-2-30b-a3b-thinking at main - Hugging Face, https://huggingface.co/kakaocorp/kanana-2-30b-a3b-thinking/blob/main/LICENSE
카카오, AI 모델 '카나나-2' 오픈소스 공개…MoE 구조 적용 - 디잇플러스,https://www.theitplus.kr/news/articleView.html?idxno=1565
Kakao boosts Kanana-2 and open-sources four models to expand Korea AI use - Chosunbiz, https://biz.chosun.com/en/en-it/2026/01/20/52TGB7VXMVHUHI3CFPELF2HIIM/
