
오늘 수강한 강의 - EDA 서울시 범죄 현황 데이터 분석 (01 ~ 17)
01 ~ 02 강남3구 범죄현황 데이터 개요 및 읽어오기
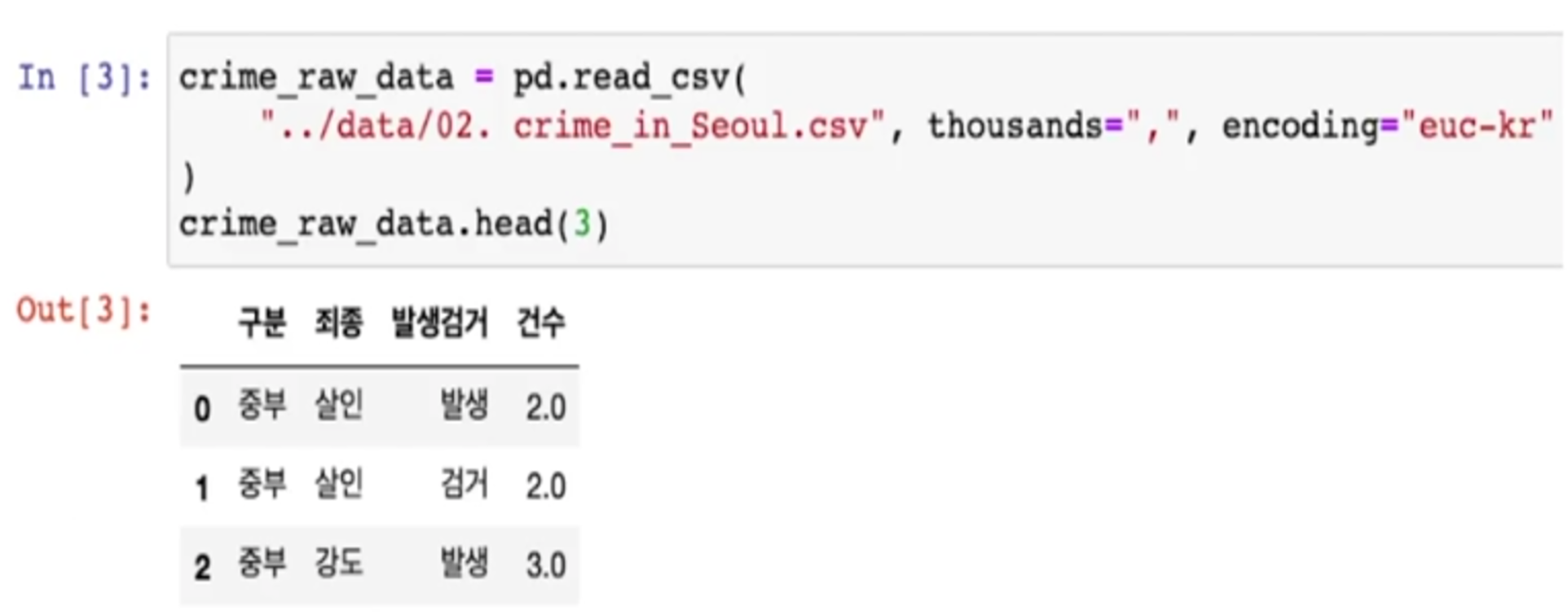
데이터 확인하고 초기 정리하기
- 필요한 모듈 import
- 먼저 numpy와 pandas를 사용한다
- 숫자값들이 콤마(,)를 사용하고 있어서 문자로 인식될 두 있다
- 천단위 구분(thousands=',')이라고 알려주면 콤마를 제거하고 숫자형으로 읽는다
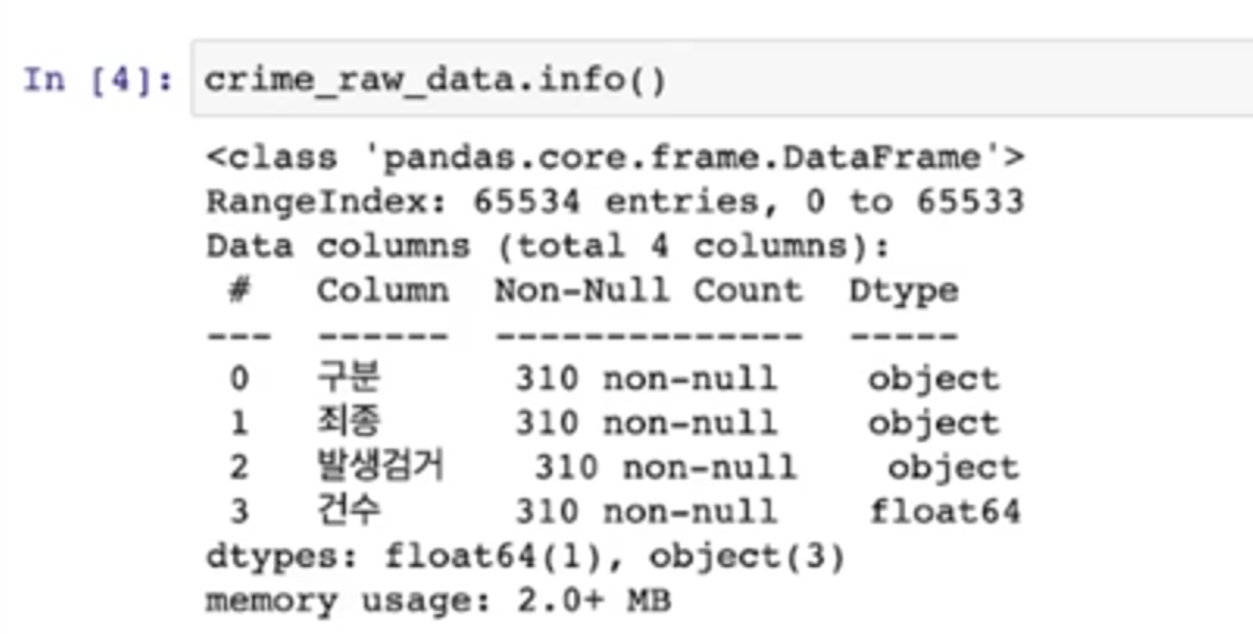
- info(): 데이터의 개요 확인
- 특정 컬럼에서 unique 조사
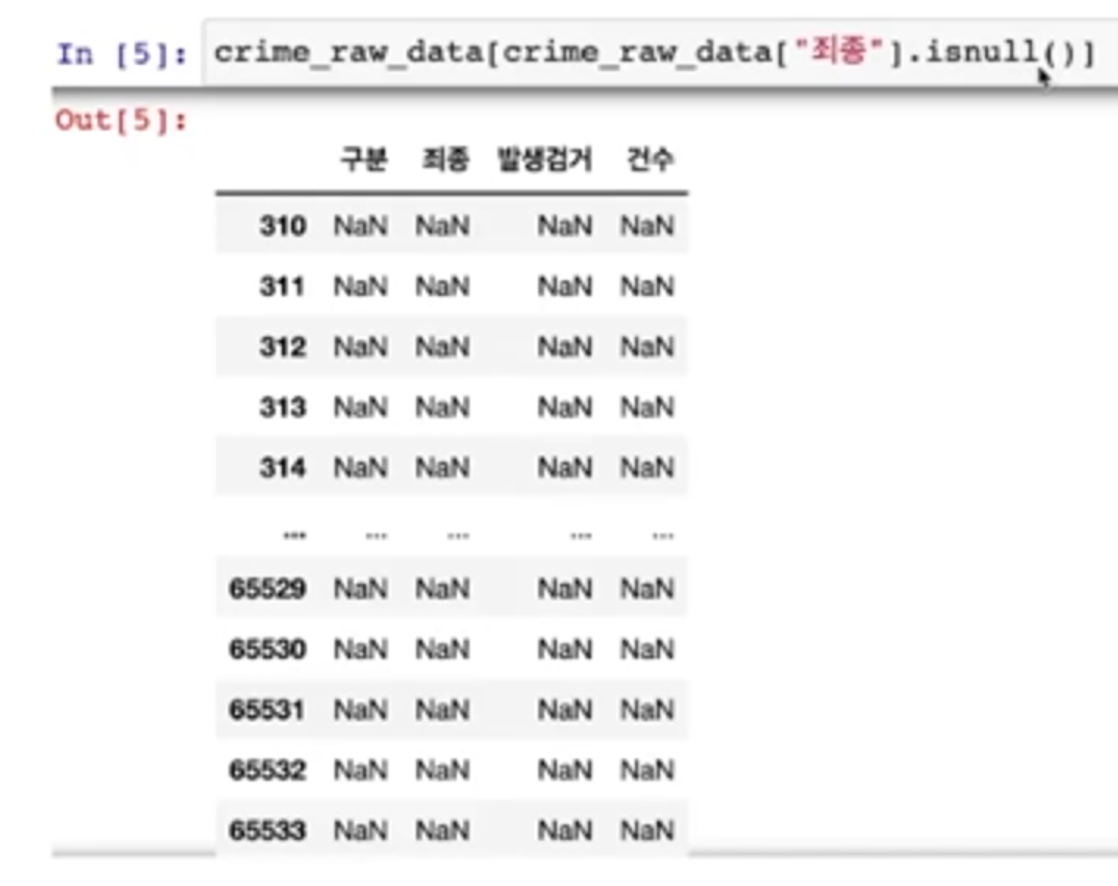
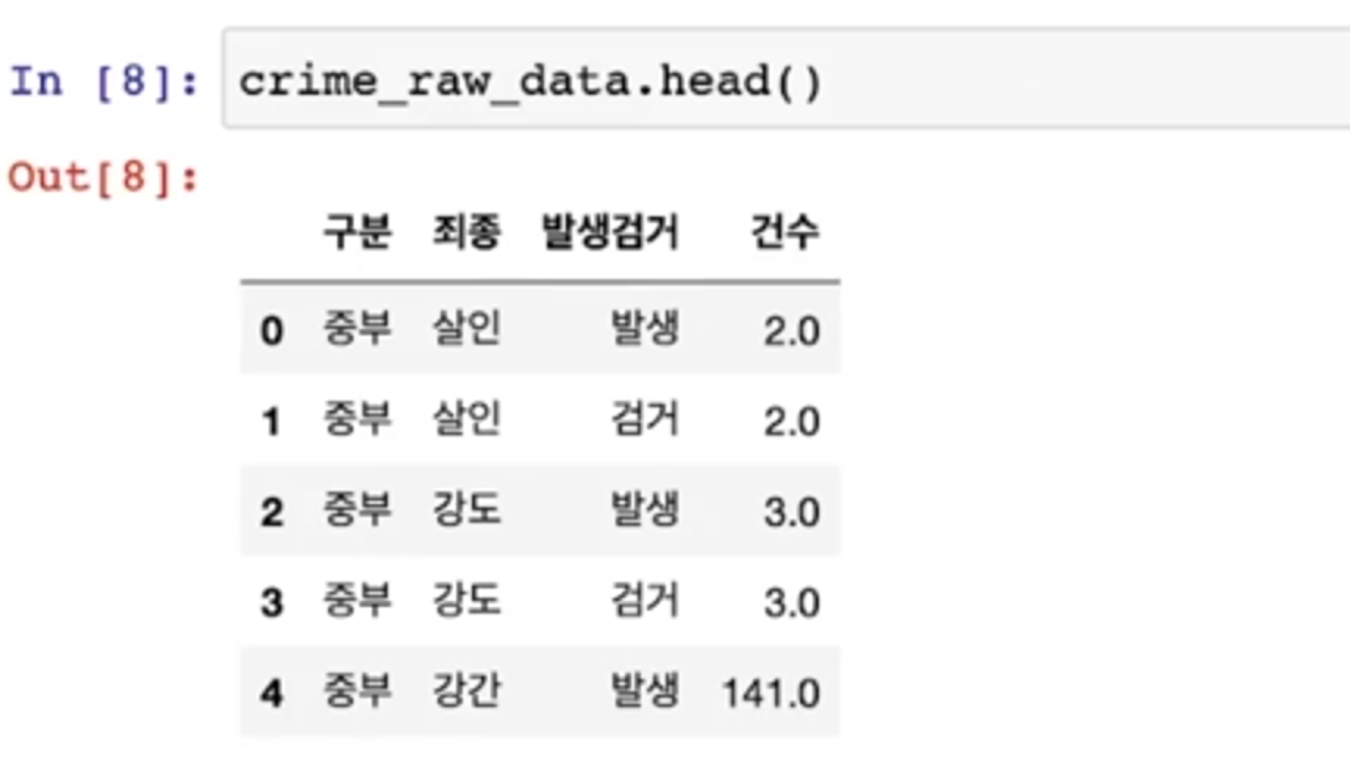
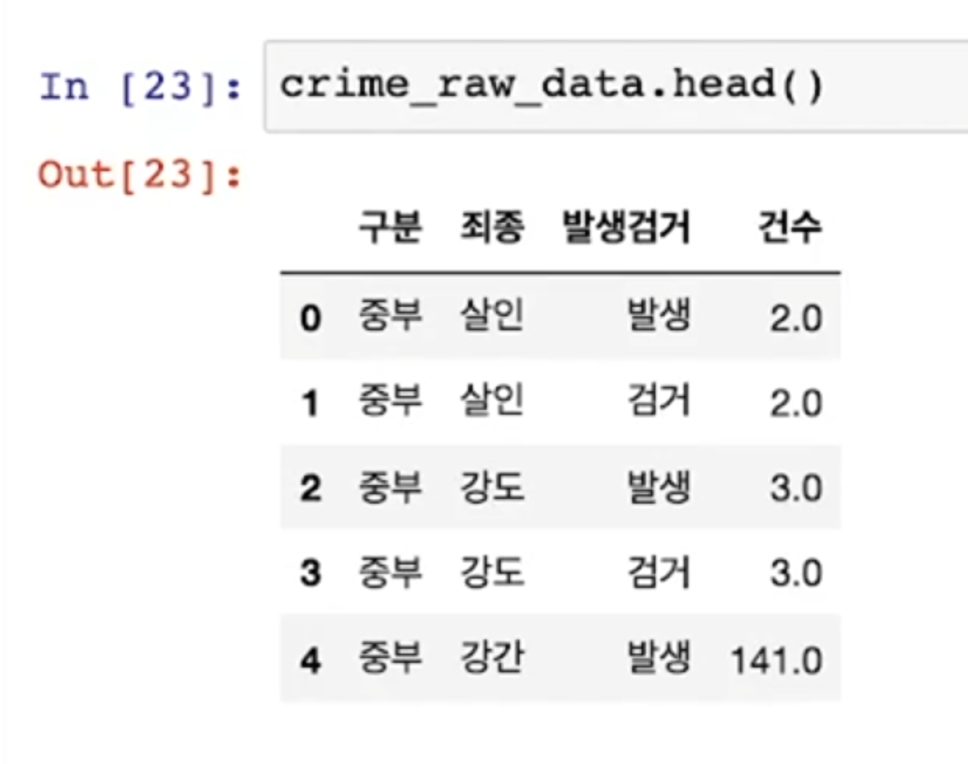
- nan이 들어가 있다


[ '죄종'에서 NaN만 추출]
- isnull() -> NaN 추출
- 엄청 많은 nan 데이터가 보임
- 이는 index가 65535의 크기를 가지게 되면서 실제 value와의 크기 차이가 발생했기 때문
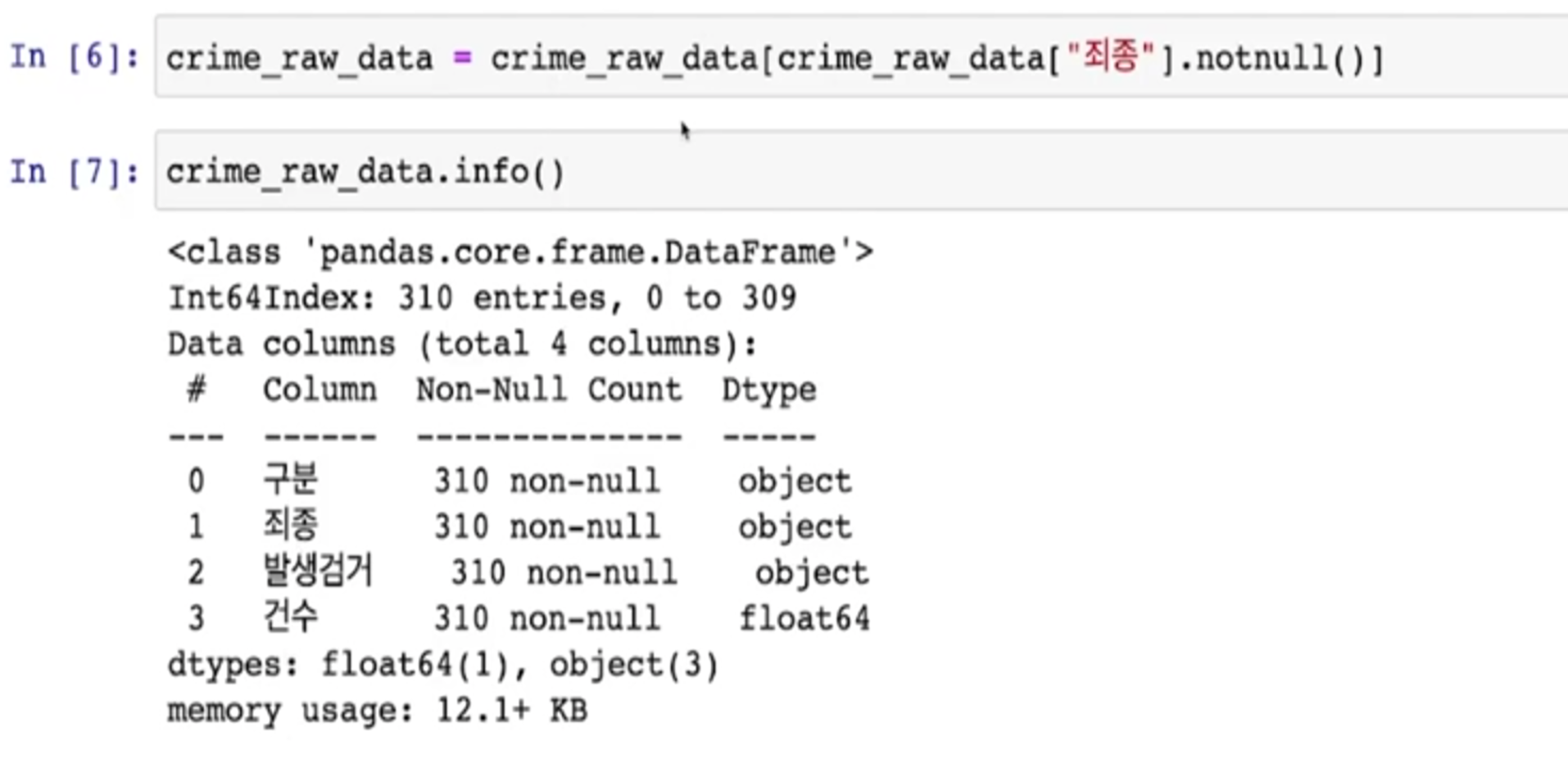
- 이럴 때는 nan을 제거하는 것이 아니라 nan이 아닌 데이터만 다시 가져오자
- 이 상황은 연도별로 다르다
- notnull() - > null이 아닌 데이터를 모음
- Nan을 정리하기 전의 데이터 크기 2MB
- 정리후 12.1kb
- 이 데이터는 우리에게는 의미가 없다
- 형태가 세로축에 서울시 구이름, 가로축에 5대 범죄 수치가 있으면 좋겠다
03 ~ 04 Pandas의 pivot_table
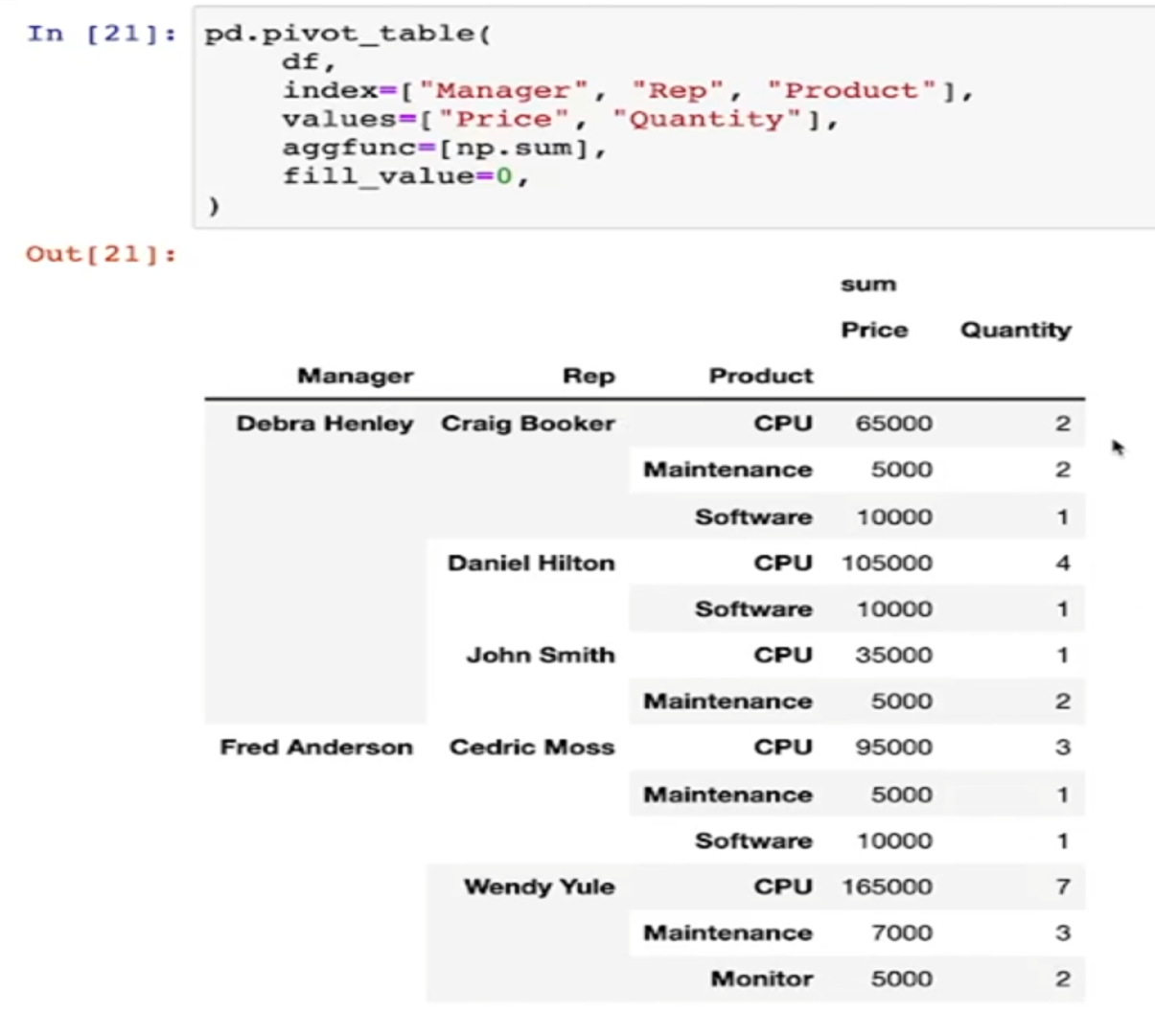
Pandas Pivot Table
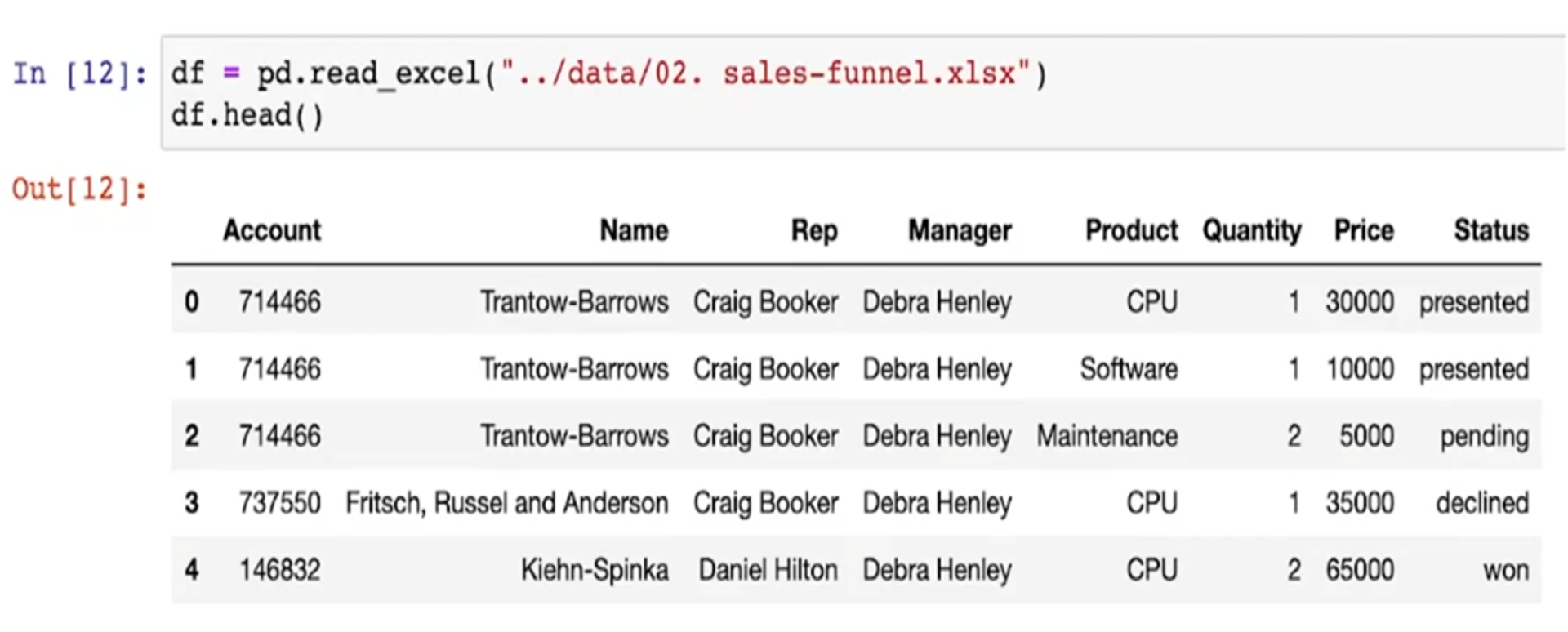
- 간단한 판매 현황표
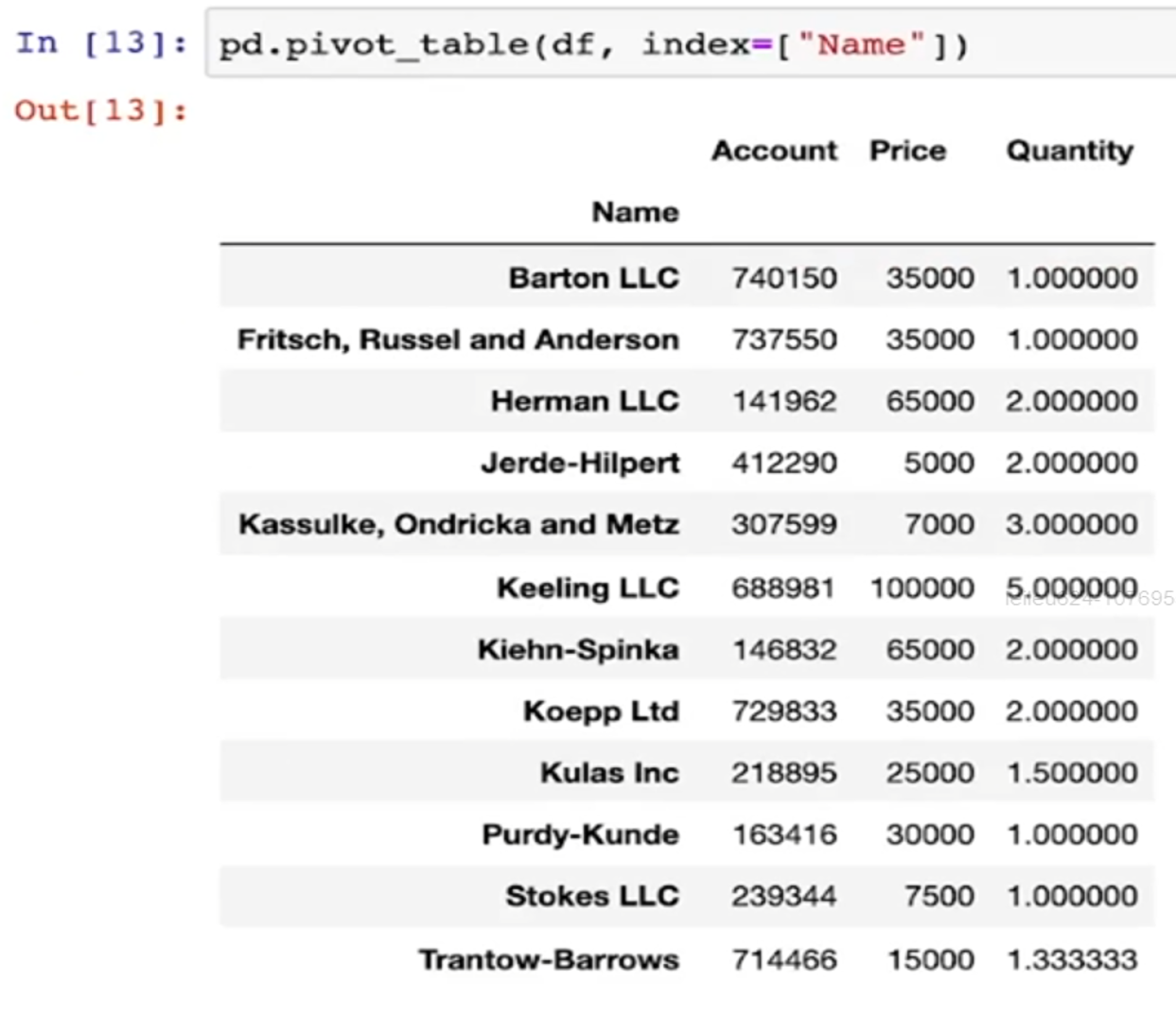
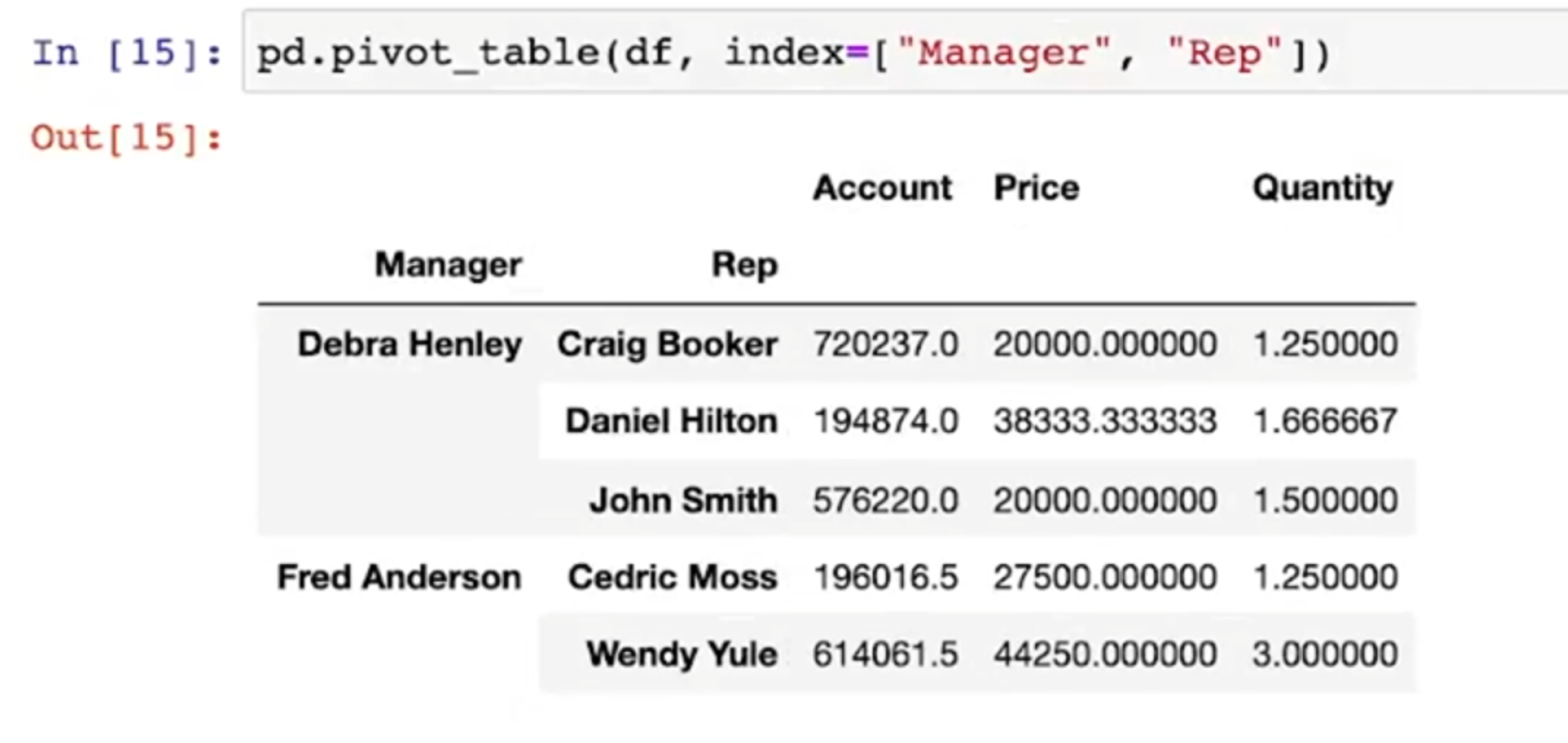
- pivot_table -> Name을 인덱스로 두고 재정렬
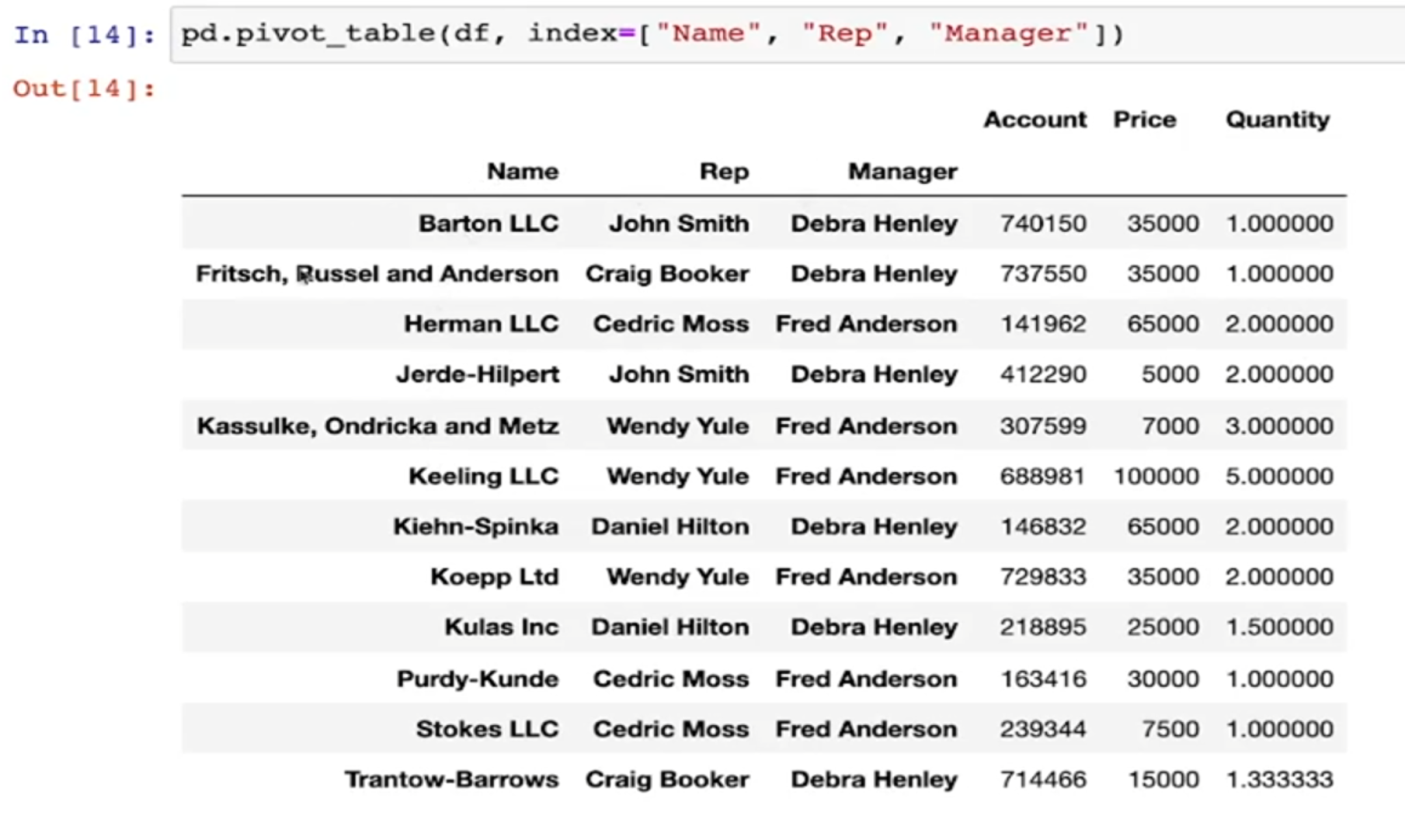
- index를 여러개 지정할 수 있음
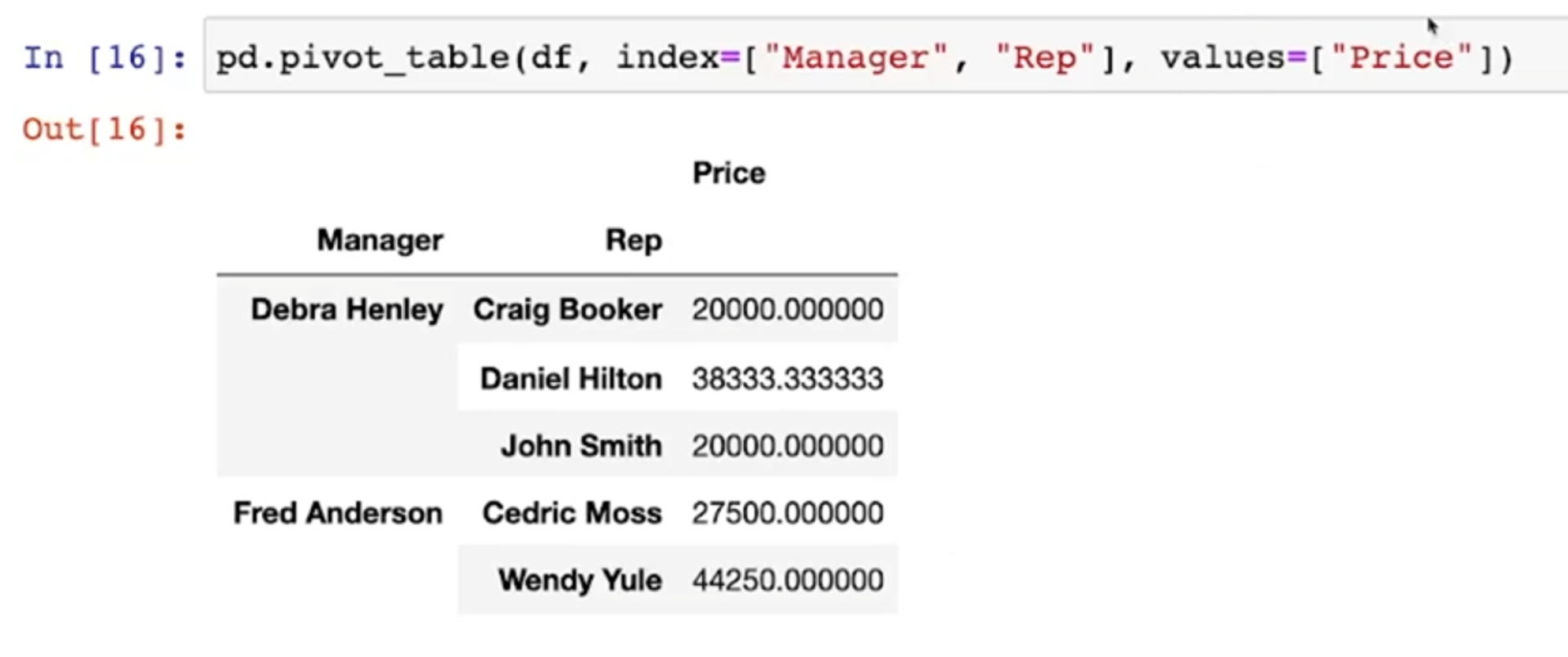
- values를 지정할 수 있음
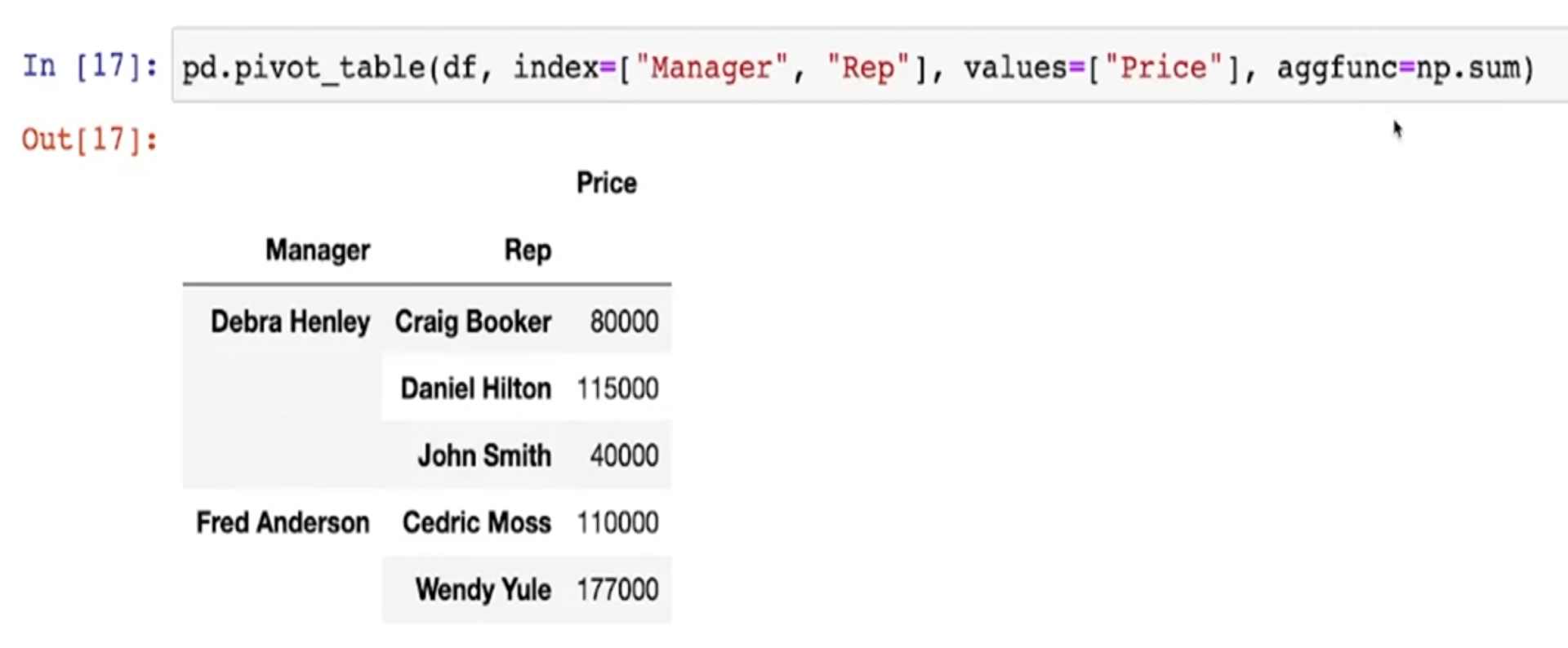
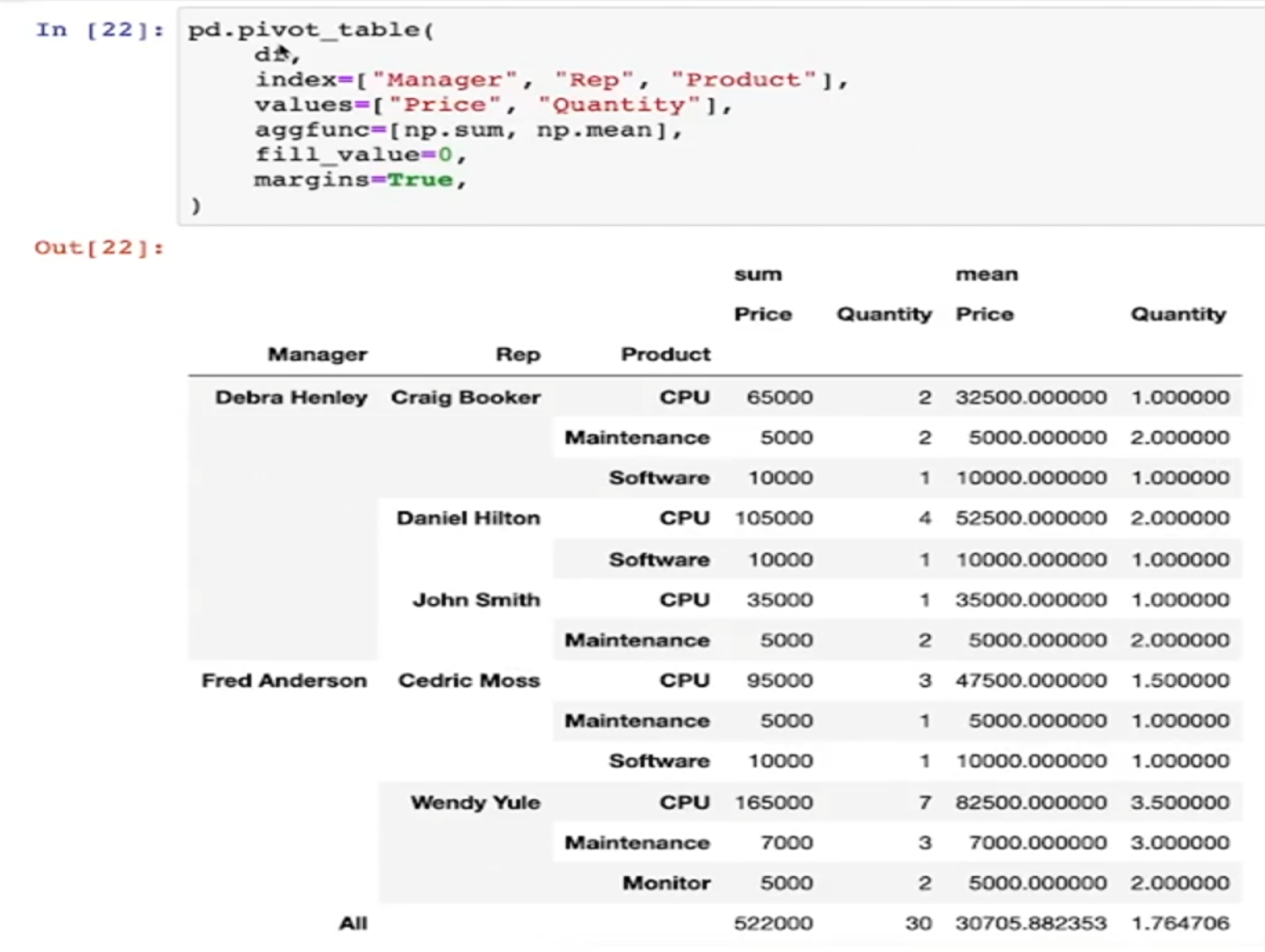
- values에 함수를 적용할 수 있다
- 디폴트는 평균
- 합산 등의 다른 함수를 적용할 때는 aggfunc옵션을 지정
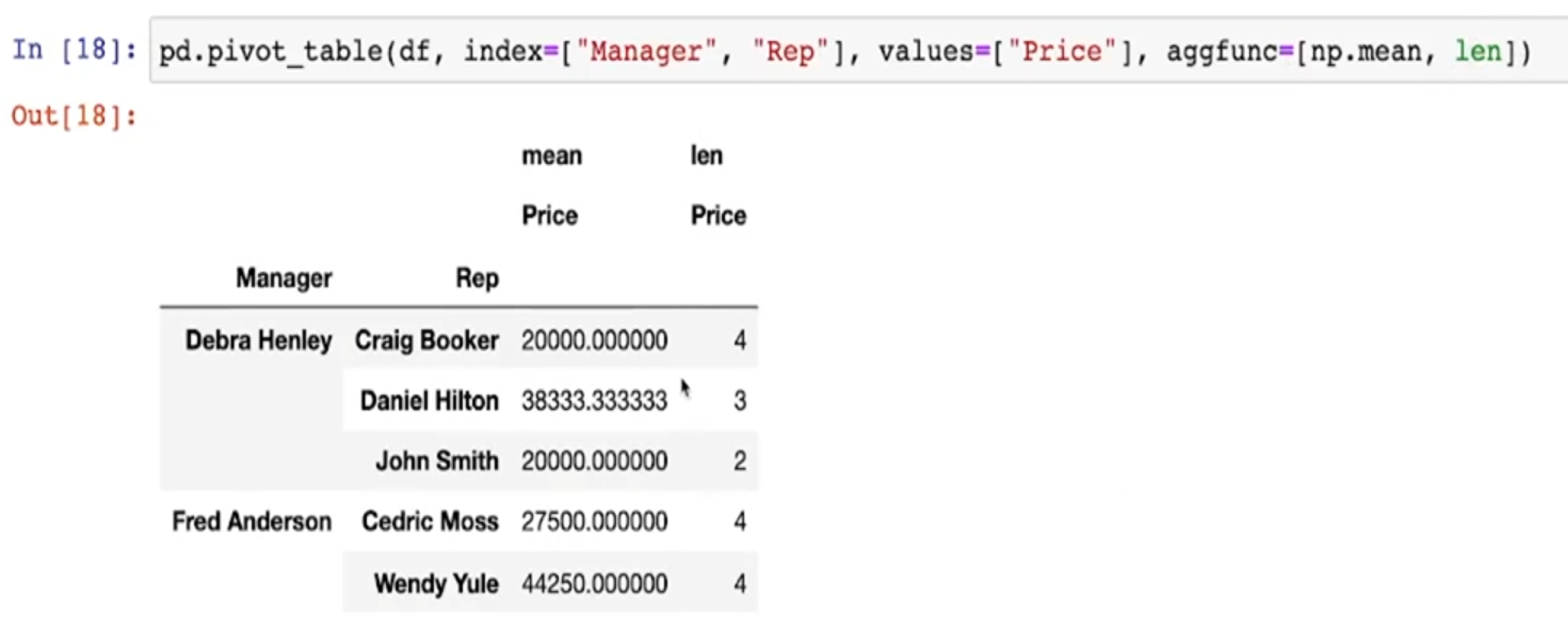
- 갯수도 적용(len)
- 분류를 지정(coulumns)
- 합계를 지정할 수 있다

05 ~ 06 서울시 범죄현황 데이터 정리
Pandas Pivot Table 적용
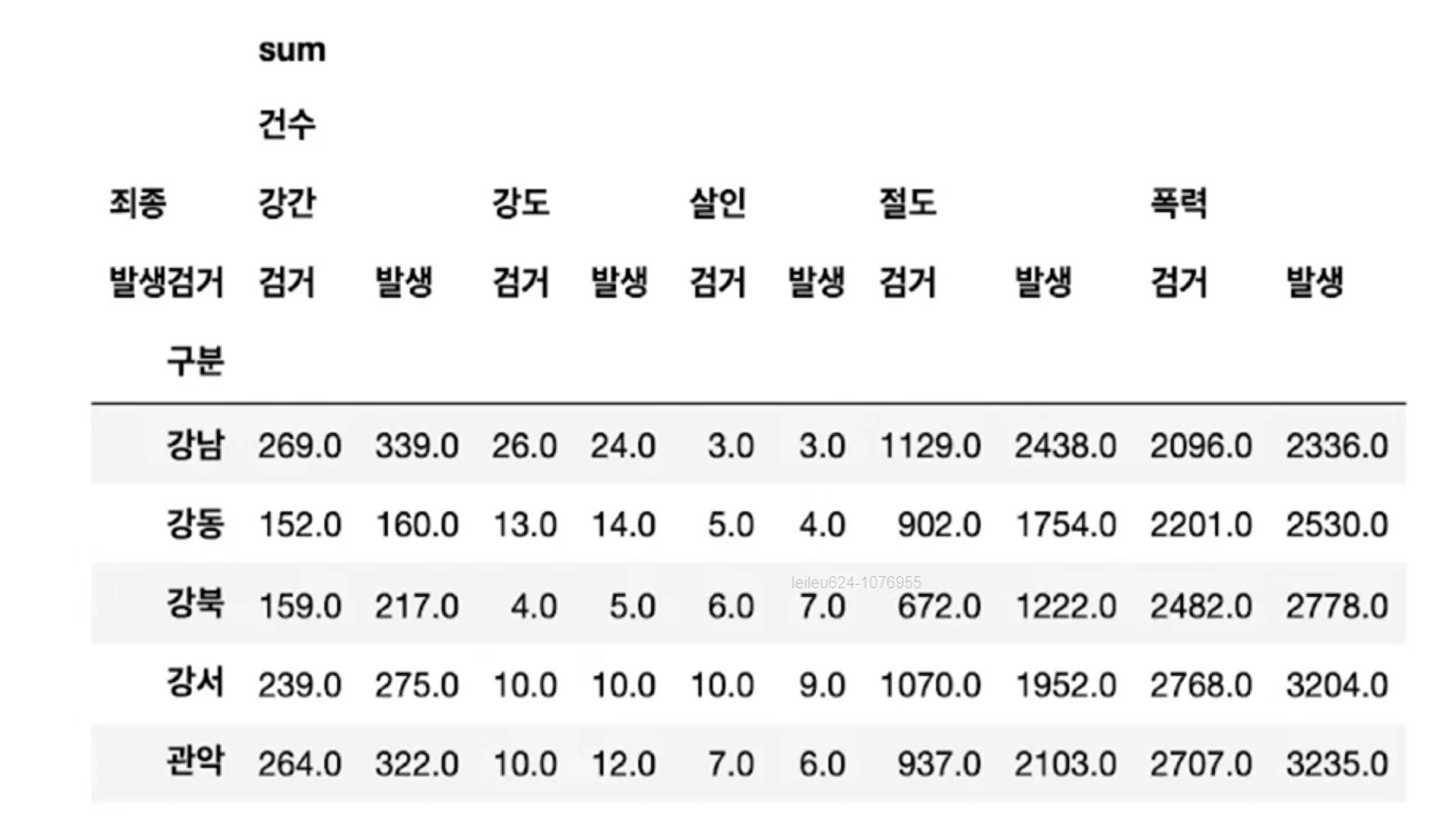
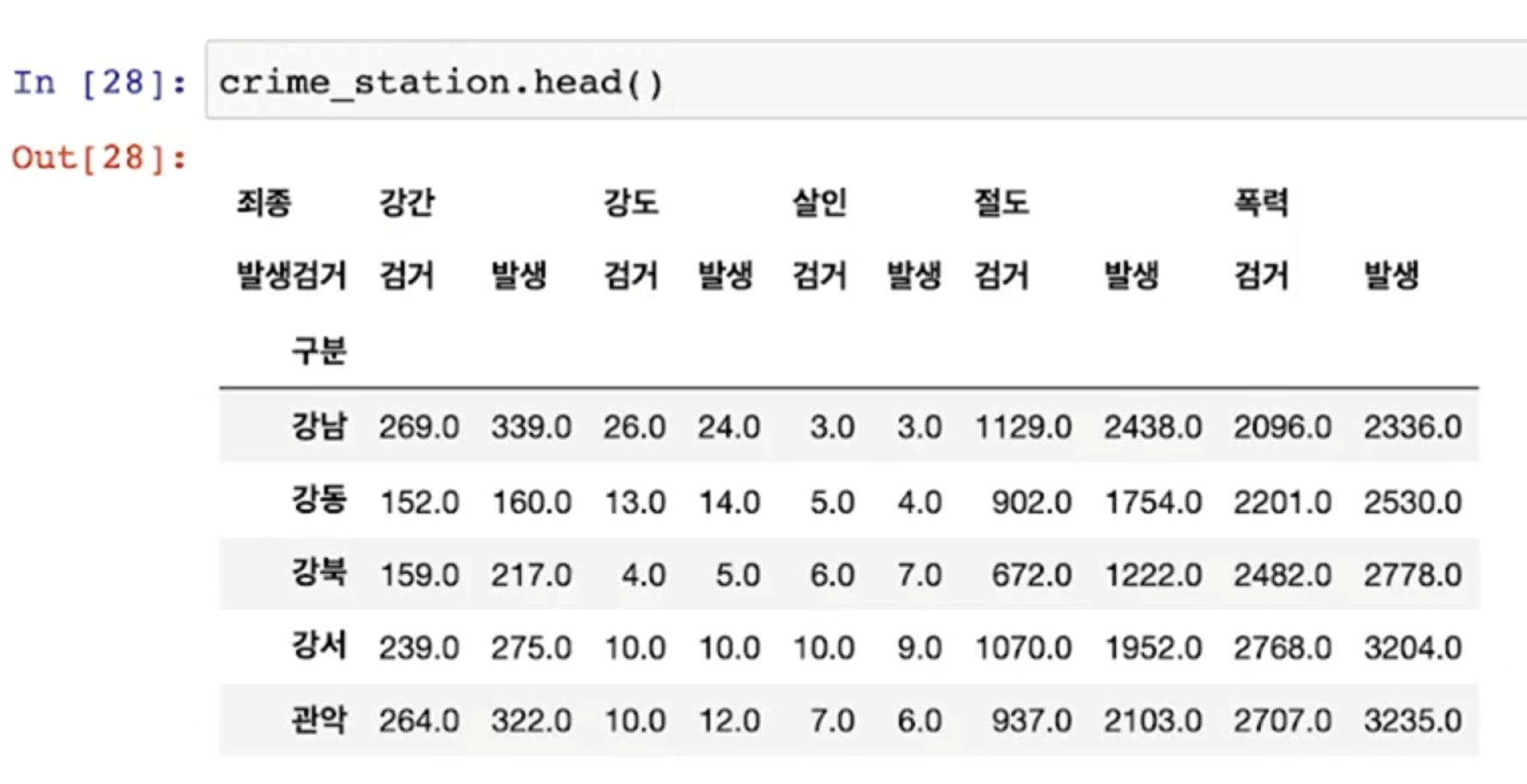
- 경찰서 이름을 index로 하도록 정리
- default가 평균(mean)이므로 사건의 합을 기록하기 위해 aggfunc 옵션에 sum을 사용하는 것에 주의
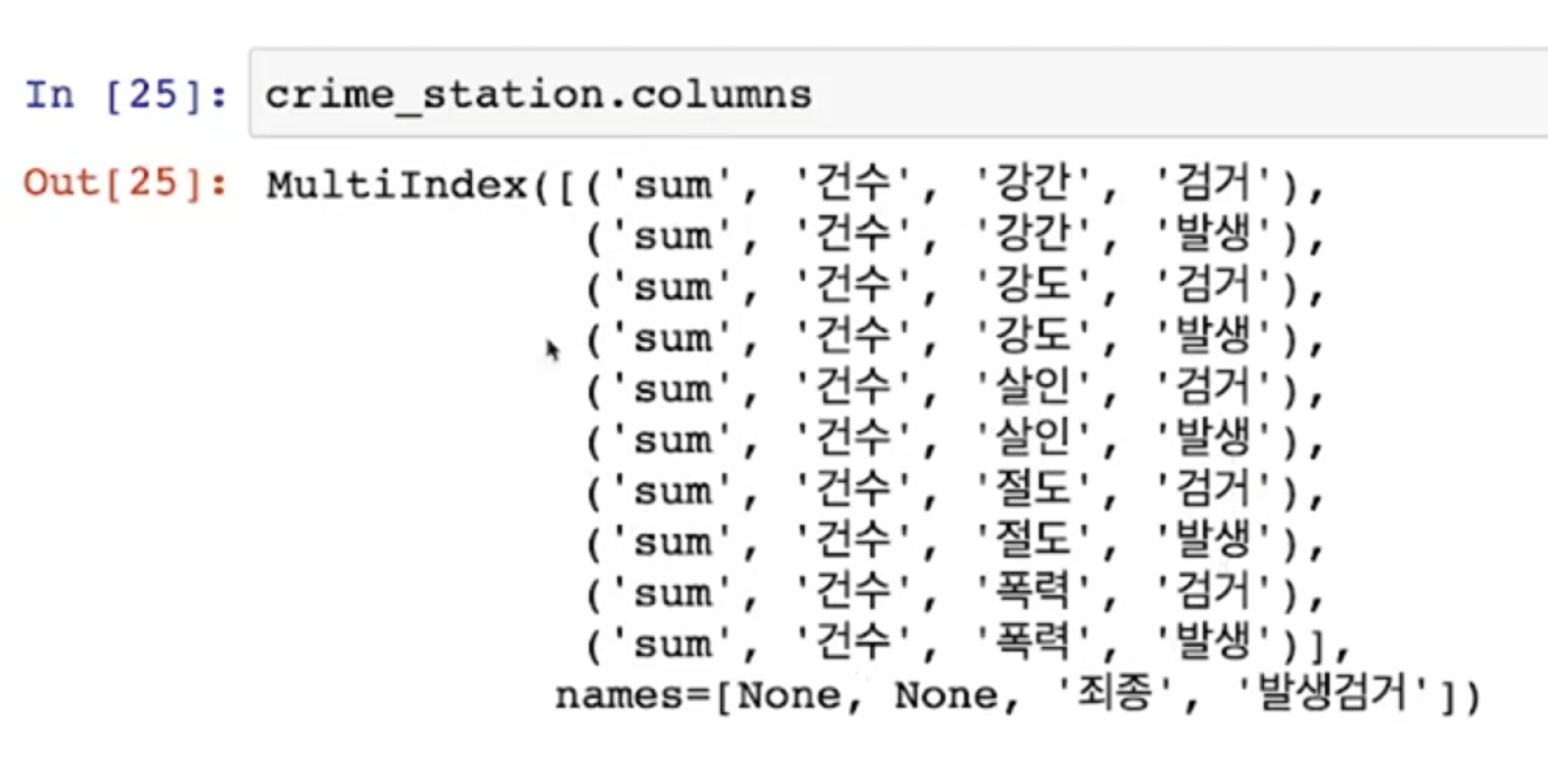
- 이렇게 정리된 데이터의 경우 column이 multi로 잡힘
- Multi Columns Index
- pivot_table을 적용하면 column이나 index가 다중으로 잡힌다
- Multi Index의 대한 접근
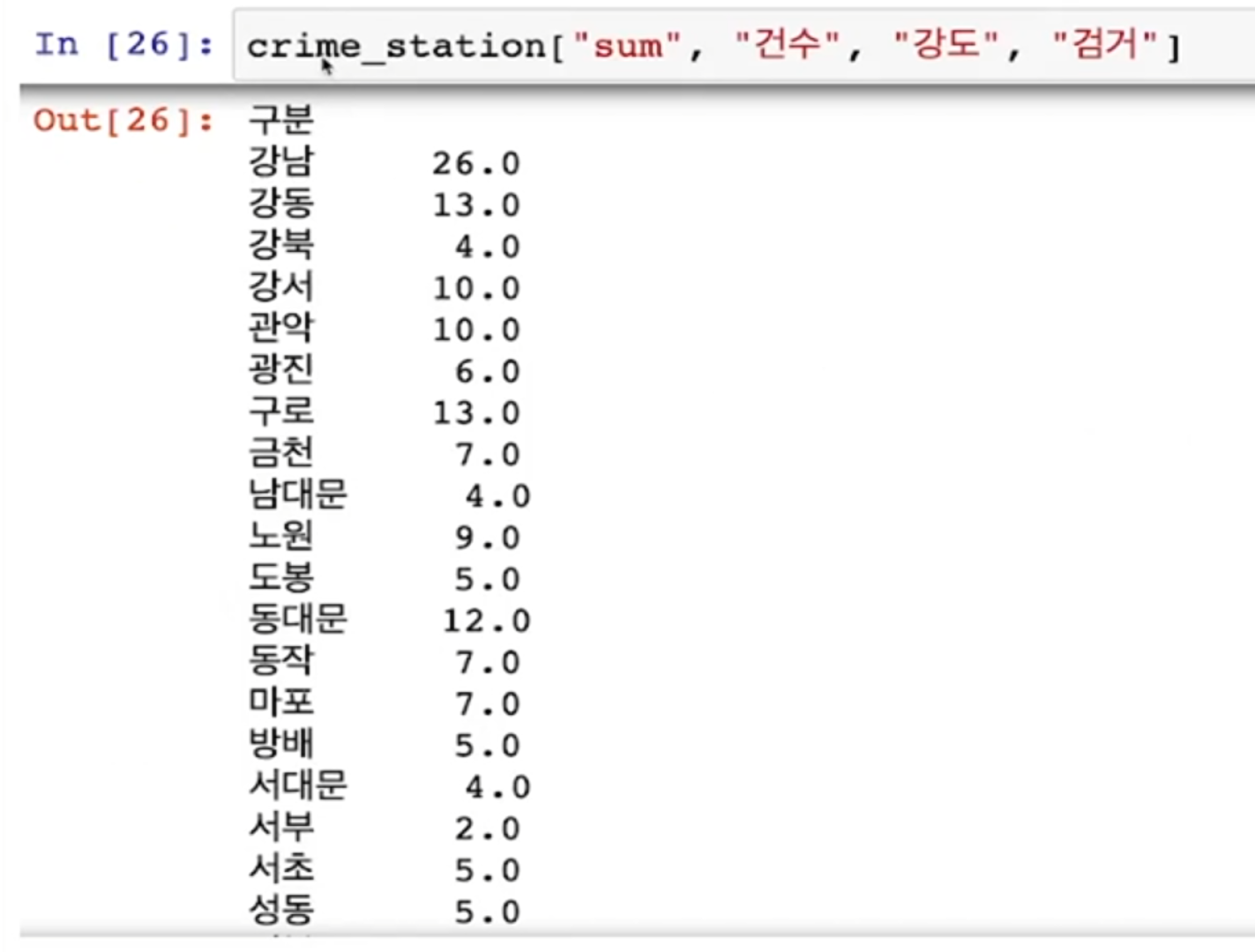
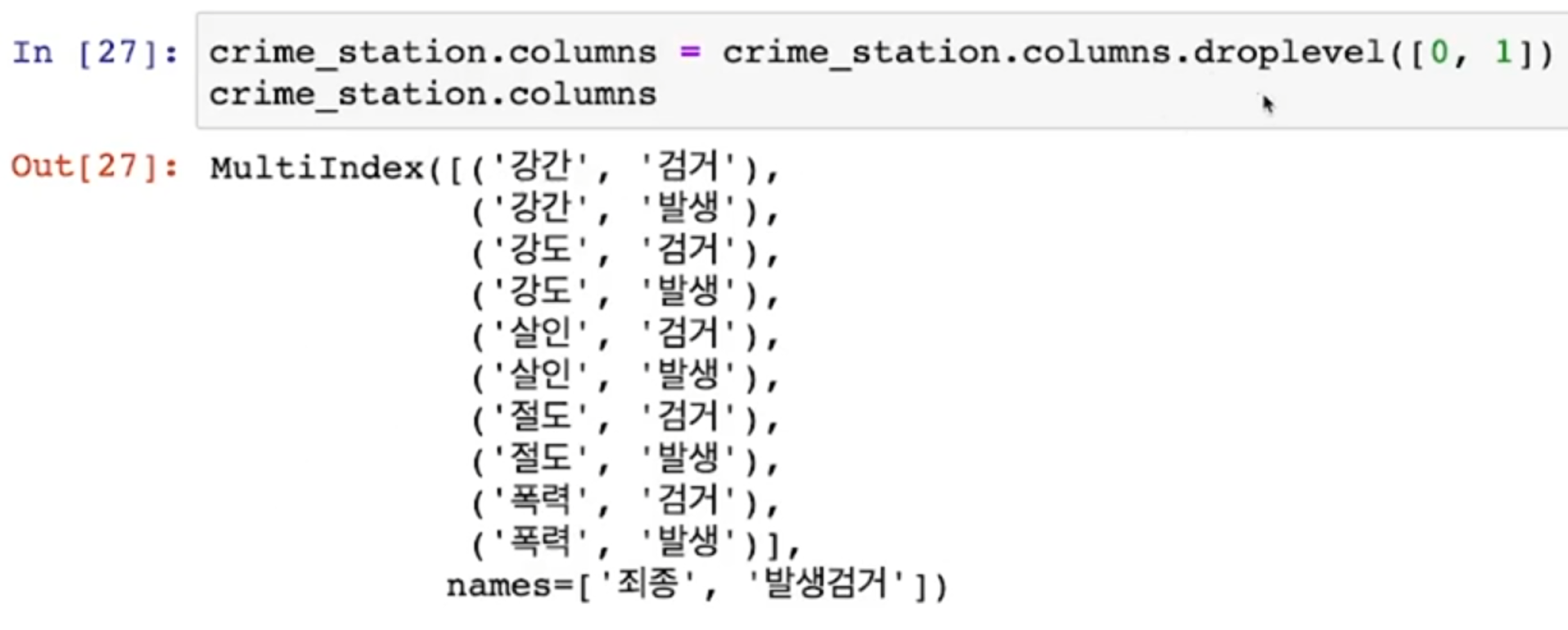
- 다중 컬럼에서 특정 컬럼 제거 -> droplevel()
- 현재 index는 경찰서 이름으로 되어 있다
- 경찰서 이름으로 구이름을 알아야 한다


07 pip 명령과 conda 명령
pip 명령
- Python의 공식 모듈 관리자
- pip list: 현재 설치된 모듈 리스트 반환
- pip install module_name: 모듈 설치
- pip uninstall module_name: 설치된 모듈 제거
conda 명령
- pip를 사용하면 conda 환경에서 dependency 관리가 정확하지 않을 수 있다
아나콘다에서는 가급적 conda 명령으로 모듈을 관리하는 것이 좋다- conda list : 설치된 모듈 list
- conda install module_name : 모듈 설치
- conda uninstall module_name : 모듈 제거
- conda install -c channel_name module_name : 지정된 배포 채널에서 모듈 설치
- 모든 모듈이 conda로 설치되는 것은 아니다
08 ~ 09 google maps api 사용 준비하기
Python 모듈 설치
conda install -c conda-forge googlemapsGoogle Map API
[구글맵 활용]
- 경찰서 이름을 가지고 해당 경찰서가 속해 있는 구를 알아내자
- 이때 구글 검색처럼 경찰서 이름을 검색해서 해당 구를 알아낼 수 있으면 좋겠다 (구글맵)
- conda install -c conda-forge googlemaps
- 이때 Google Map API Key도 필요하다
10 ~ 11 python의 for문
For - loop
- 모든 언어에는 다 반복문이 있다
- MATLAB의 반복문
- C/C++의 반복문

Python의 반복문
- MATLAB 반복이든, 조건이든, 함수이든 end로 끝나게 해서 구분
- C/C++은 중괄호로 구문의 시작과 끝을 구분
- Python은 들여쓰기(intent)로 구분



Pandas에 잘 맞춰진 반복문용 명령iterrows()
- Pandas 데이터 프레임은 대부분은 2차원
- 이럴때 for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들 때 iterrows()라는 옵션을 사용하면 편함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의
12 ~ 13 Google Maps에서 구별 정보를 얻어서 데이터를 정리
Google Maps를 이용해서 주소와 위치 정보 얻기
- 구글맵 import
- 구글맵 API 단순 테스트
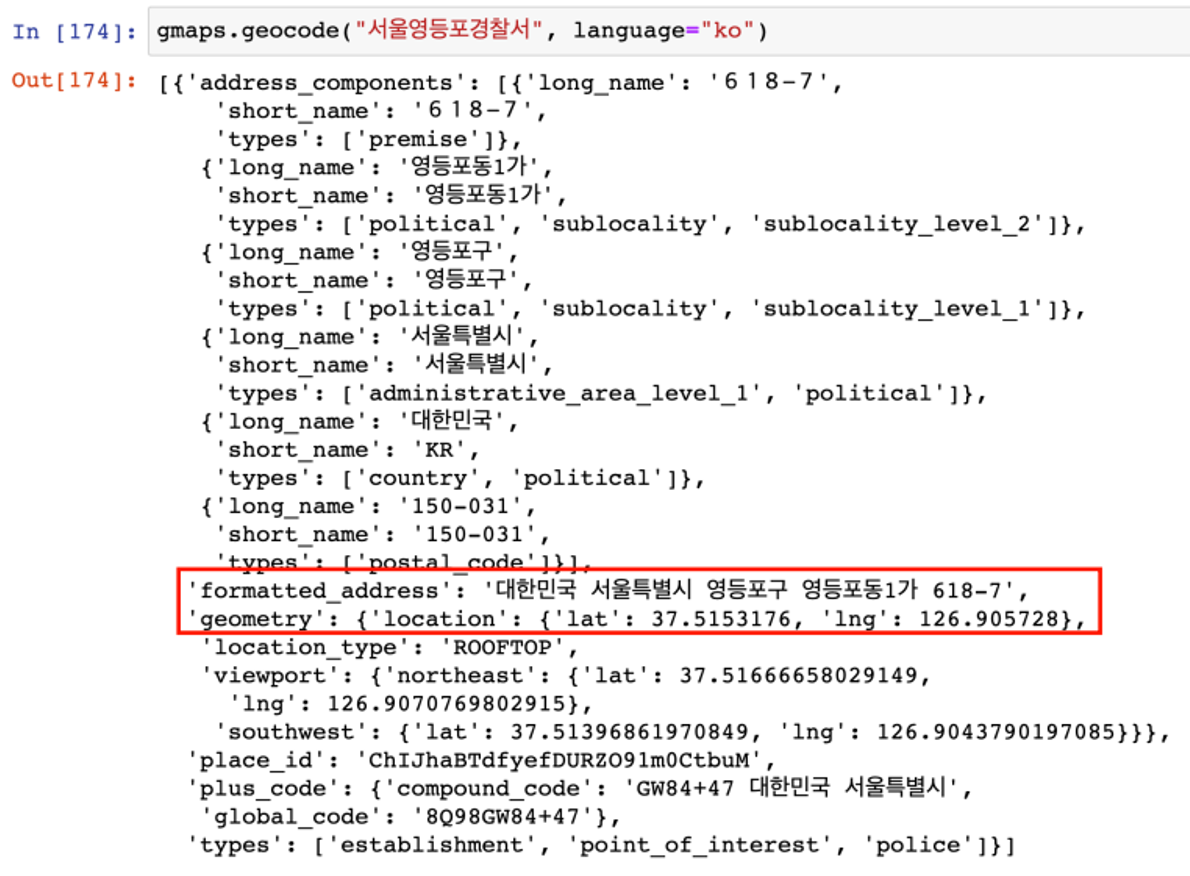
- 구글맵 API에서 데이터 얻기
- 전체 결과 크기가 1인 list형이라서 tmp[0]로 접근
- 큰 리스트 안에 dict형이다
- dict형에서 데이터를 얻는 get명령을 사용
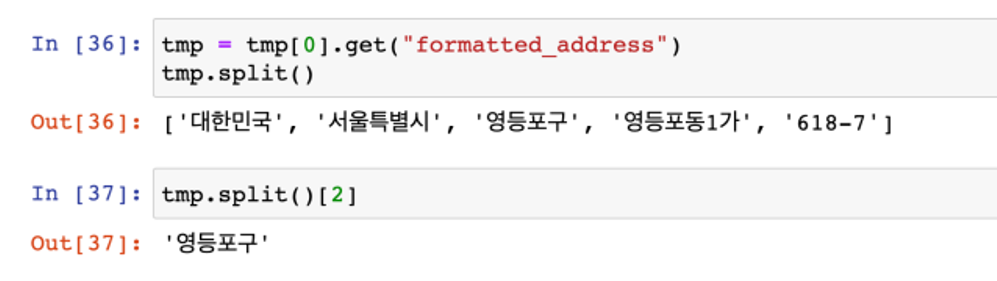
- 전체 주소에서 필요한 구 이름만 가져오기
- 경찰서 이름에서 소속된 구 이름 얻기
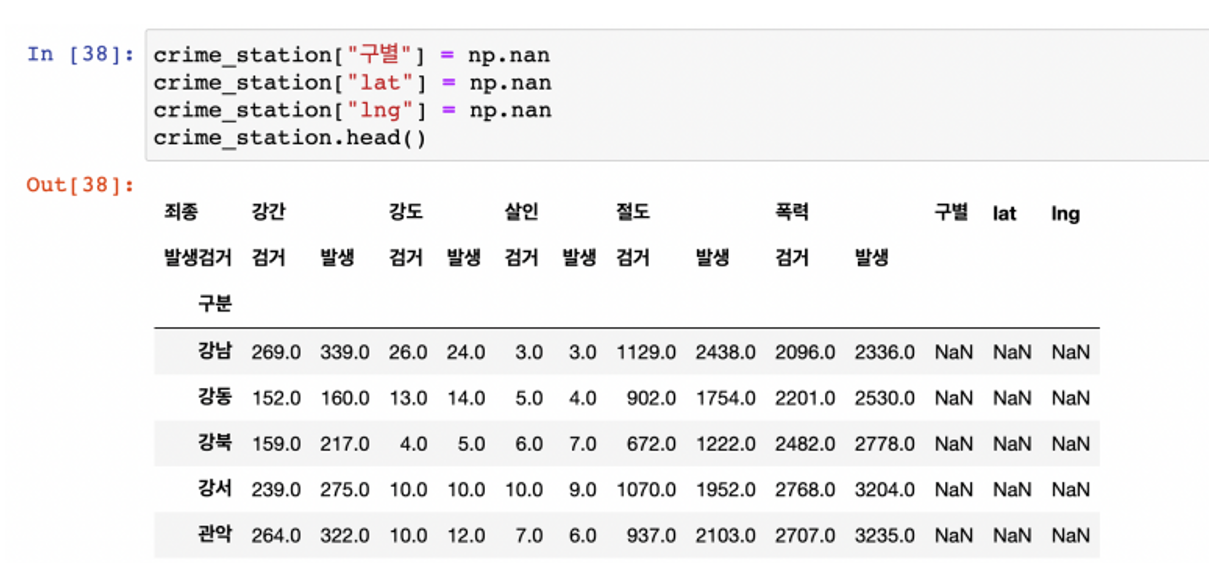
- 구 이름과 위도 경도 정보를 저장할 준비
- 반복문을 이용해서 위 표의 NaN을 모두 채우자
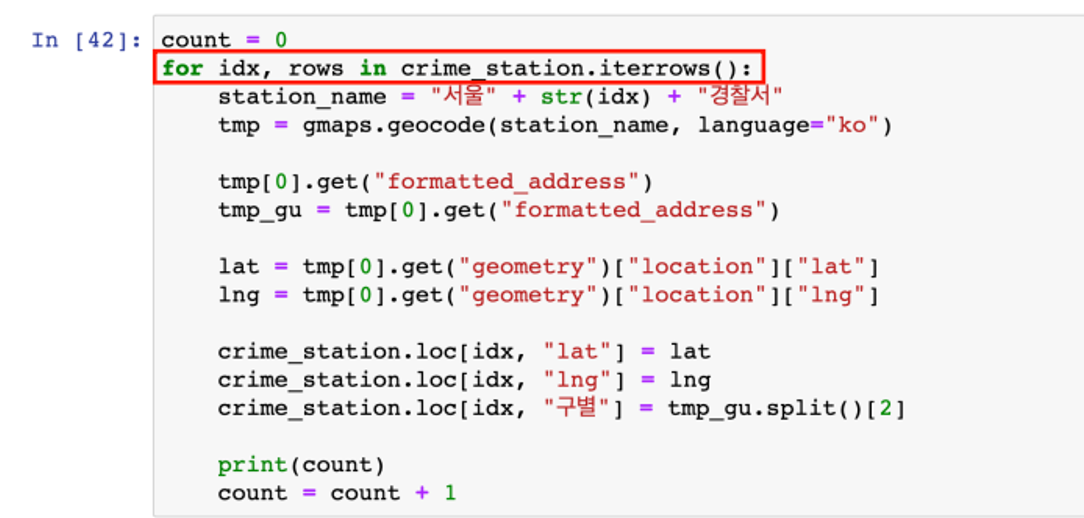
- crime_station에서 index(idx)와 나머지(rows)를 받아서 반복문을 수행
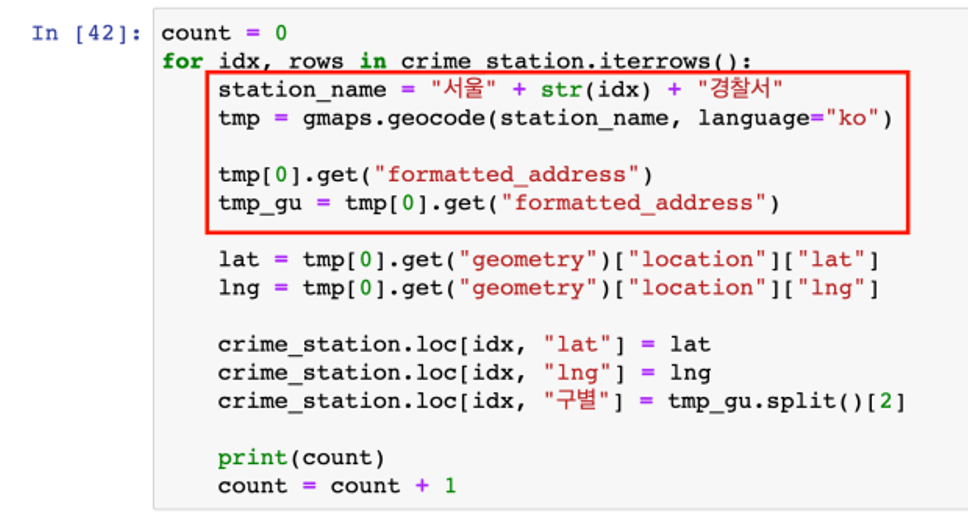
- station_name : 구글 검색을 용이하게 하기 위해 검색어를 가급적 상세하게 잡아줌
- 앞서 수행한 formatted_address에서 구 이름을 잡는 과정은 그대로
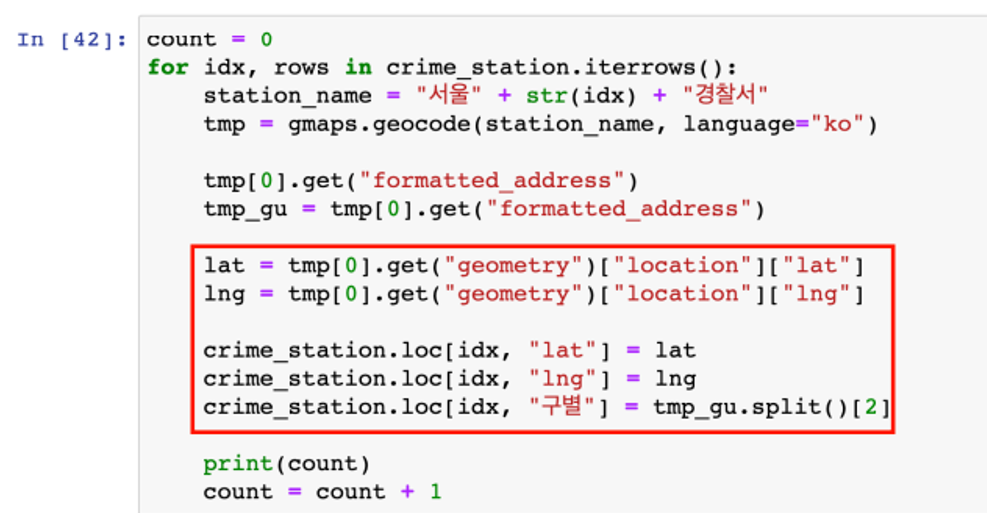
- loc 옵션을 사용
- 행(idx)과 열('lat', 'lng', '구별')을 지정해서 구글 검색에서 얻은 정보를 기록
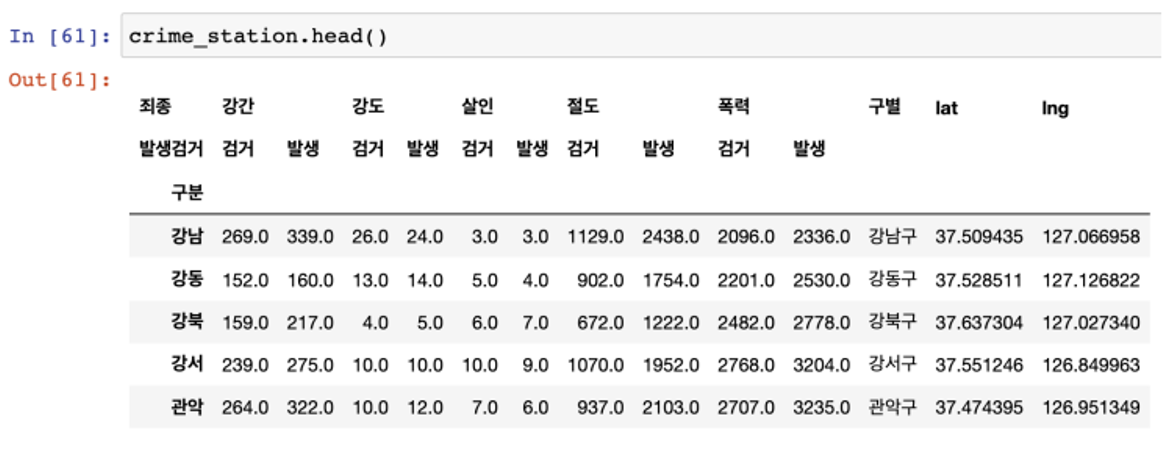
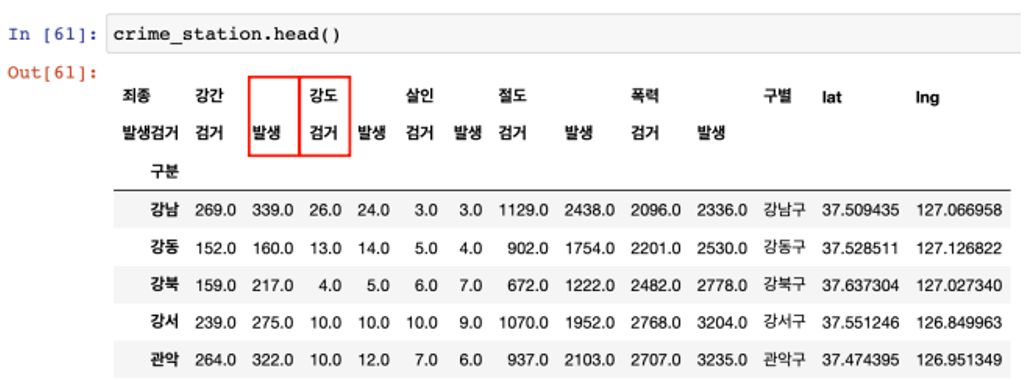
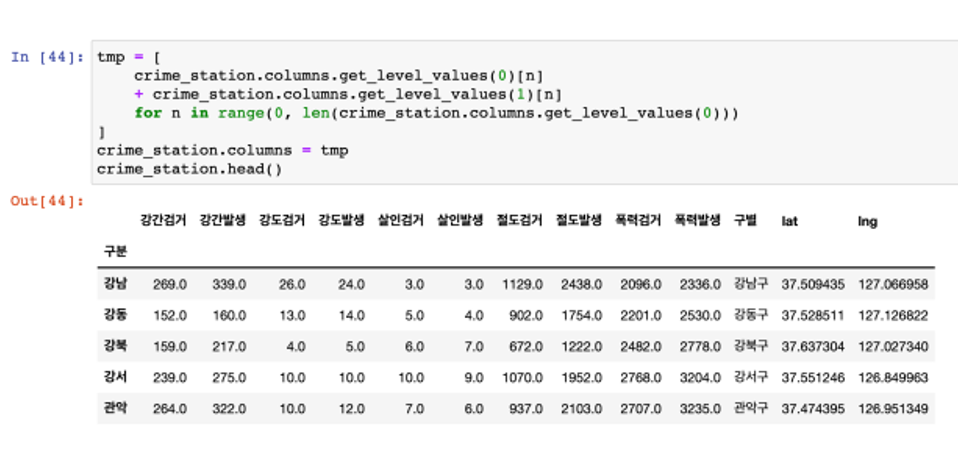
- 여기서 두 줄의 컬럼을 하나씩 합치는 걸로 하자
- 예를 들어 강도검거, 강도발생
- 저장




14 ~ 15 구별 데이터로 변경하기
구별 데이터 얻기
- 경찰서별 데이터로 정리되어 있다
- 서울은 한구에 경찰서가 두곳인 구가 있다
- 구의 이름으로 다시 정렬해야 한다
구별 데이터 생성
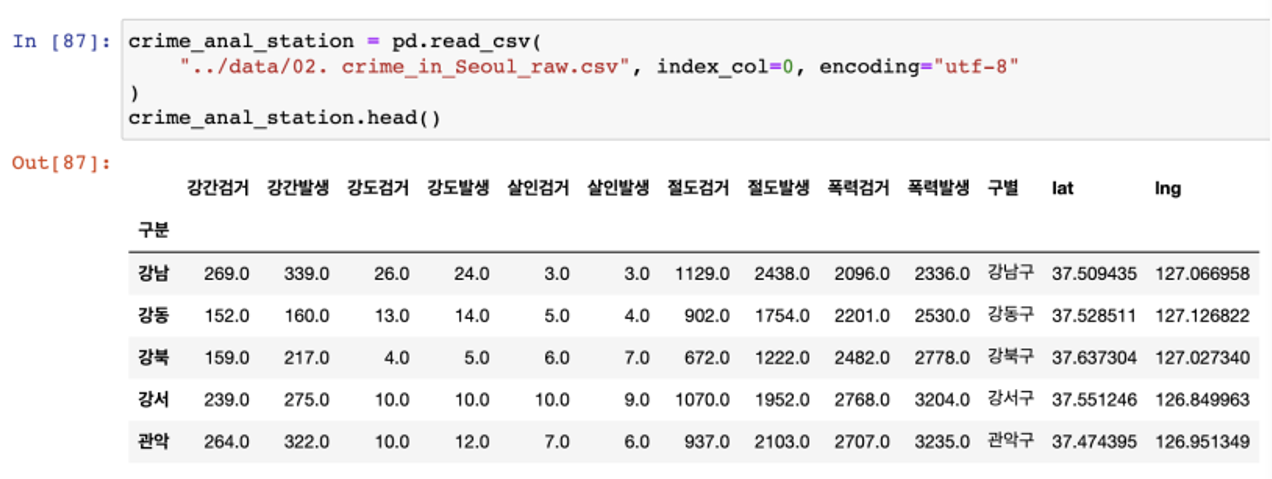
- 데이터를 다시 읽어오자
- 이렇게 중간 중간 데이터를 파일로 저장해두면 테스트 코드가 긴 경우 중간부터 다시 작업할 수 있다
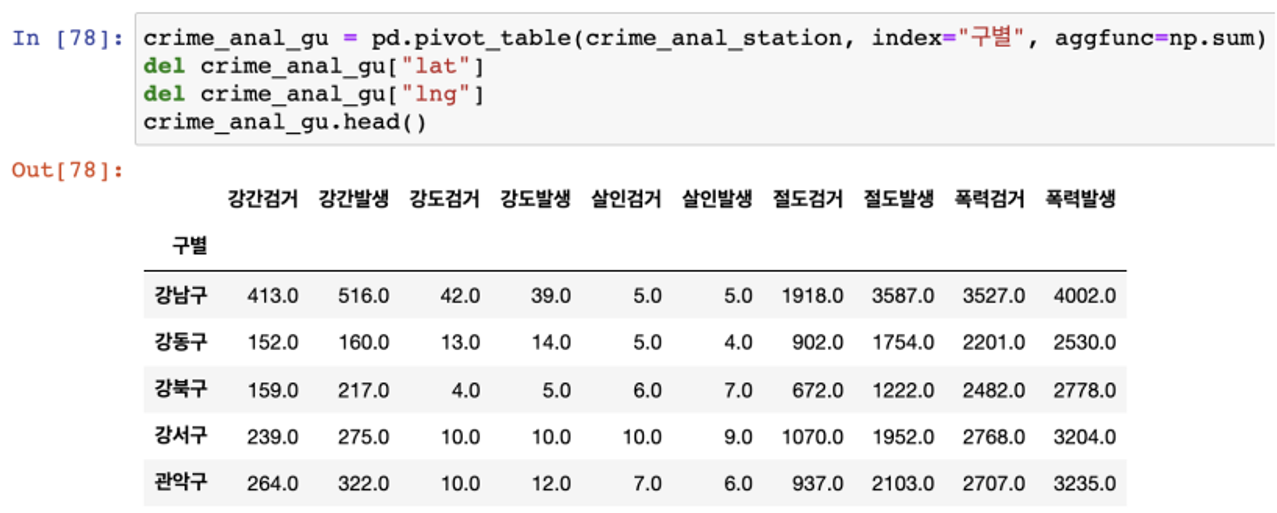
- pivot_table을 이용해서 구별로 정리하자
- pivot_table의 func을 sum으로 잡자
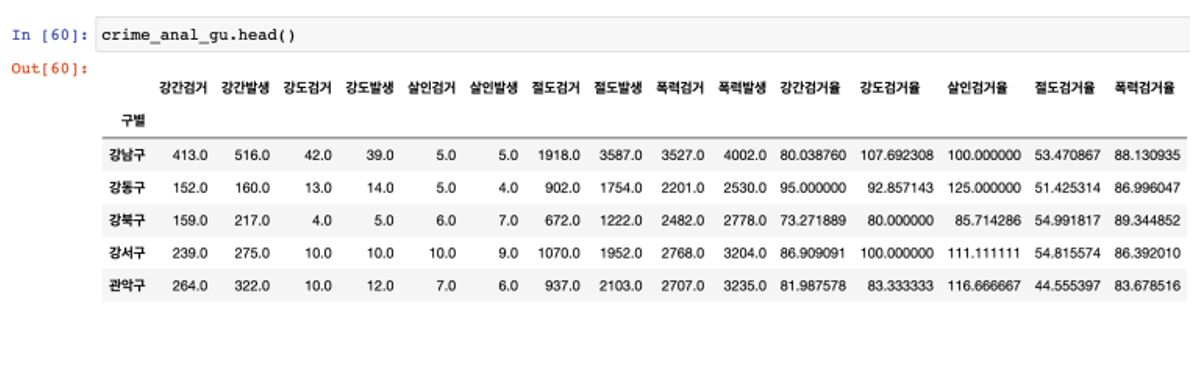
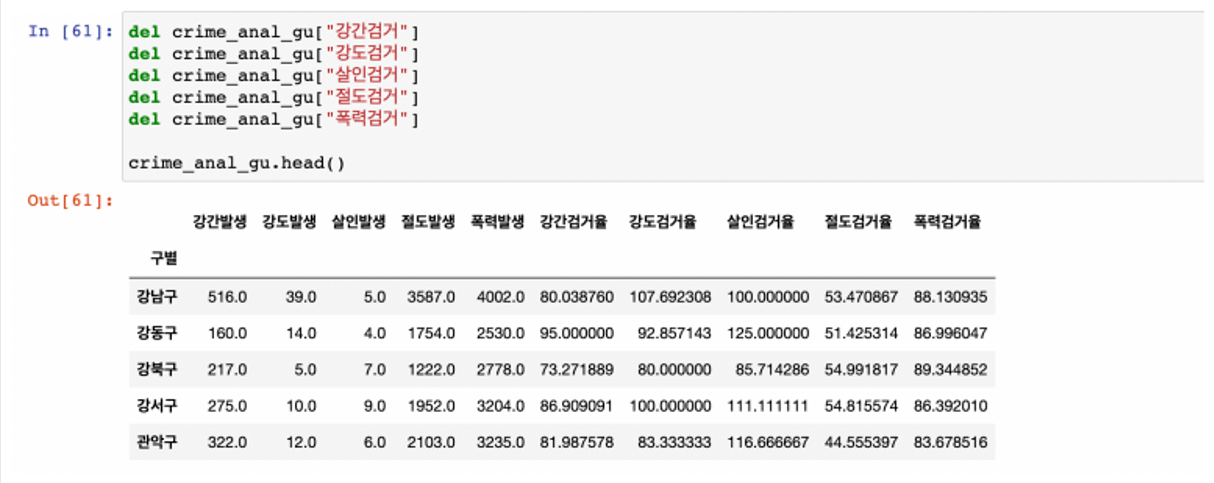
- 필요없는 칼럼은 제거(del)
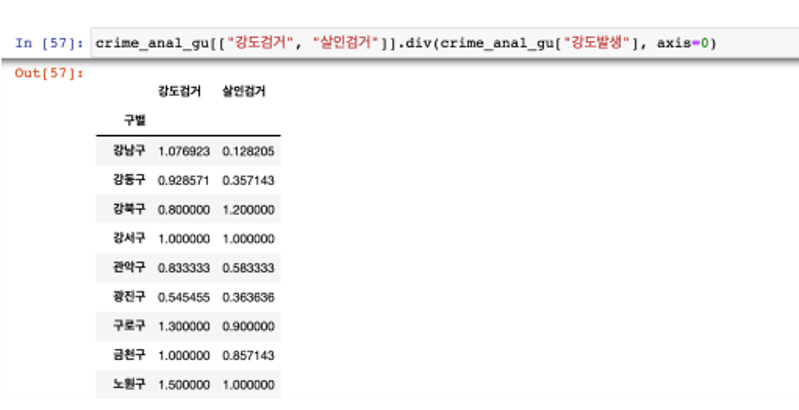
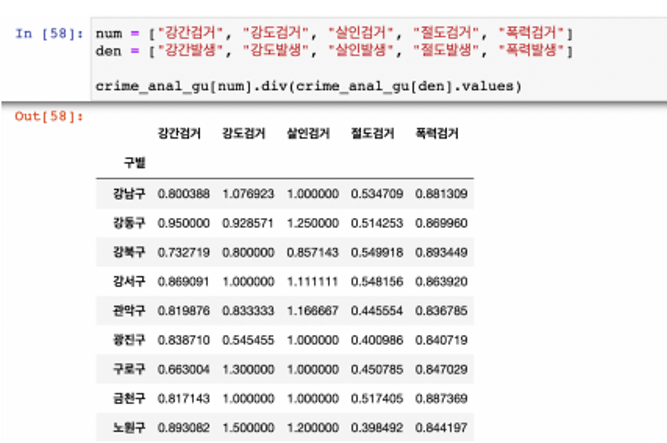
- 검거율을 만들자
- 이 경우 불가능 X
- 이 경우 가능 O
- 다수의 컬럼을 다수의 컬럼으로 각각 나누고 싶다면 이 방법 사용
- 필요없는 컬럼 제거
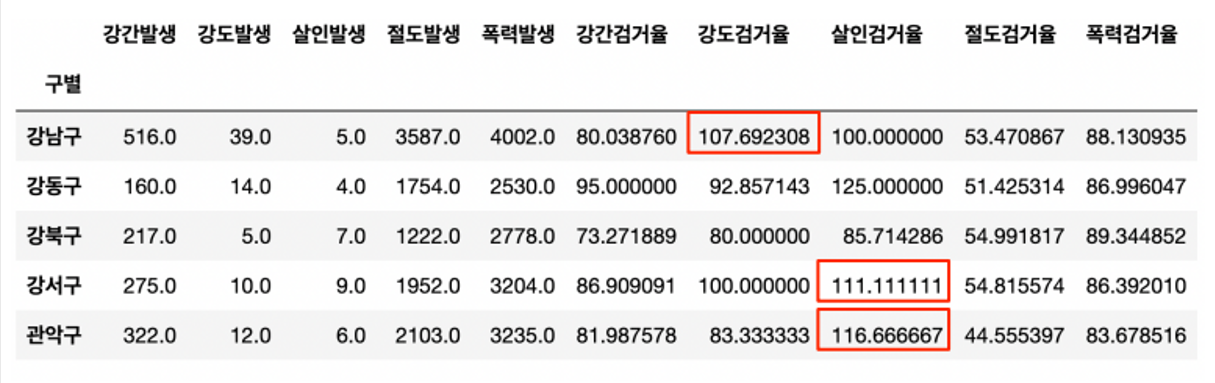
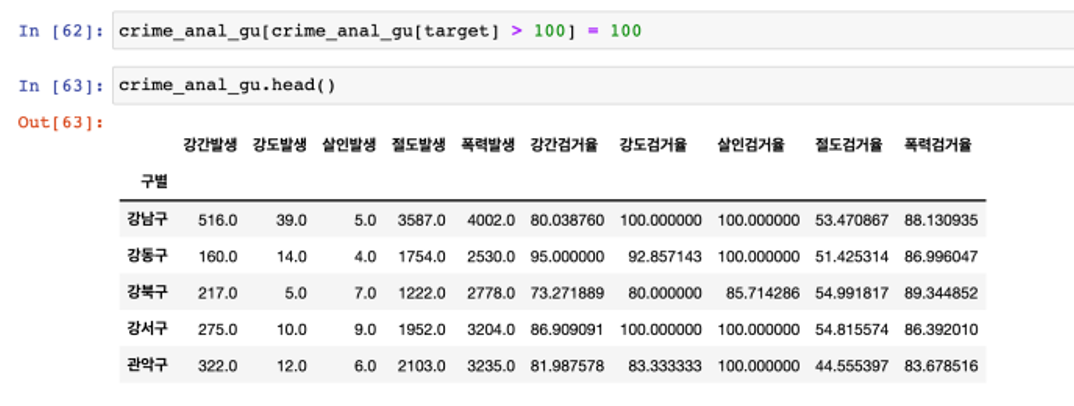
- 당연히 작년 발생 범죄도 검거 했을테니 단순 계산상으로는 검거율이 100이 넘을 수 있다
- 이에 발생연도와 검거 연도를 구분하고 분석해야겠지만 heatmap 등의 그래프에서 문제가 될 수 있어서 강제로 100 이상의 수치는 100으로 만든다
- 100보다 큰 숫자를 찾아서 바꾸기
- Pandas의 버전과 dependency에 따라 위 코드가 동작하지 않는 경우가 있다
- 그럴때 위의 코드를 적용
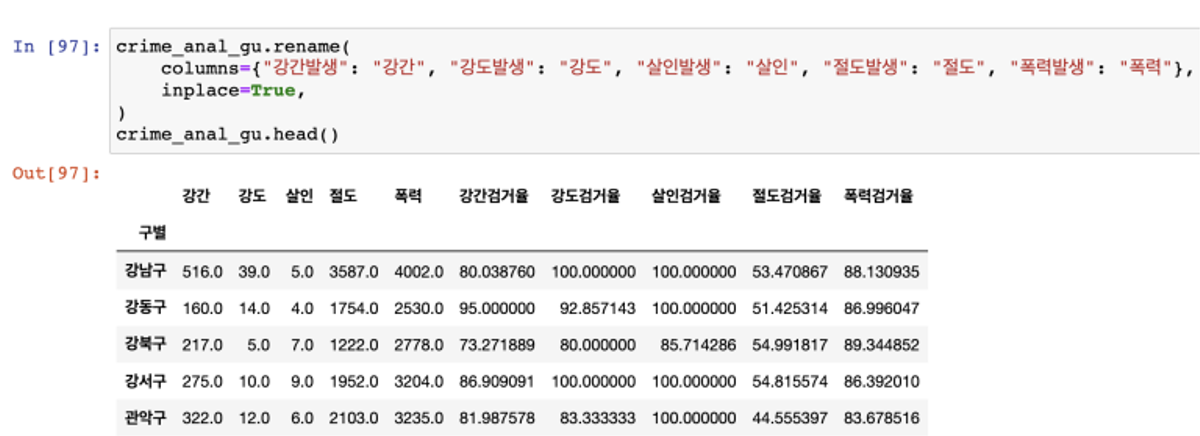
- 컬럼 이름을 간단하게 바꿈



16 ~ 17 서울시 범죄현황 데이터 최종 정리
구별 데이터에서 발생건수 정규화 데이터 생성
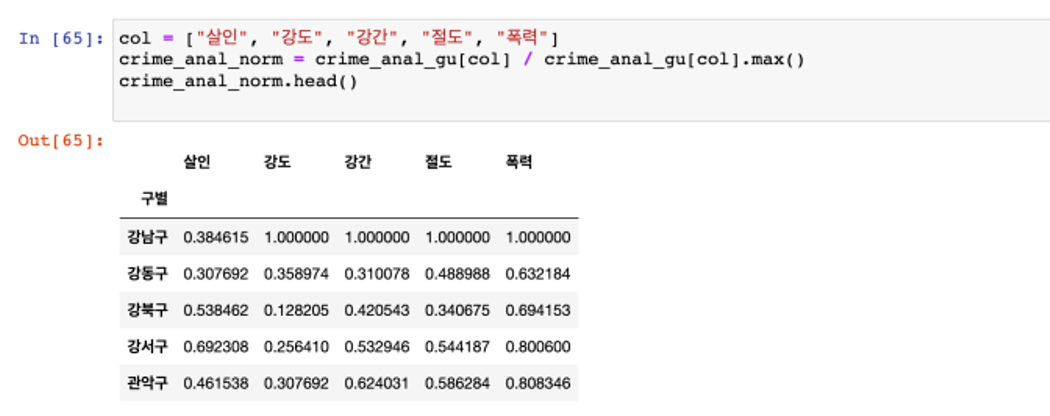
- 정규화
- 본래의 DataFrame은 두고, 정규화된 데이터를 따로 만들자
- 최고값을 1로 두고, 최소값을 0으로
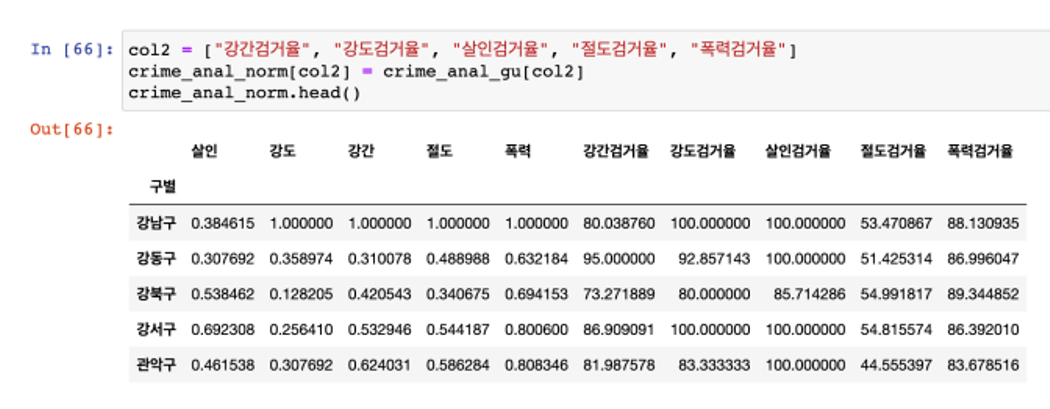
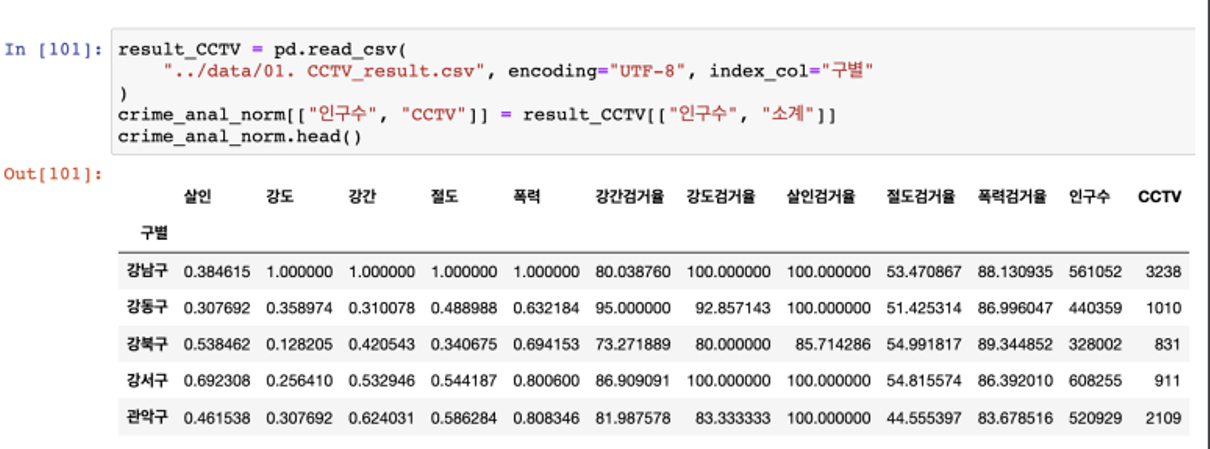
인구와 CCTV 데이터 추가
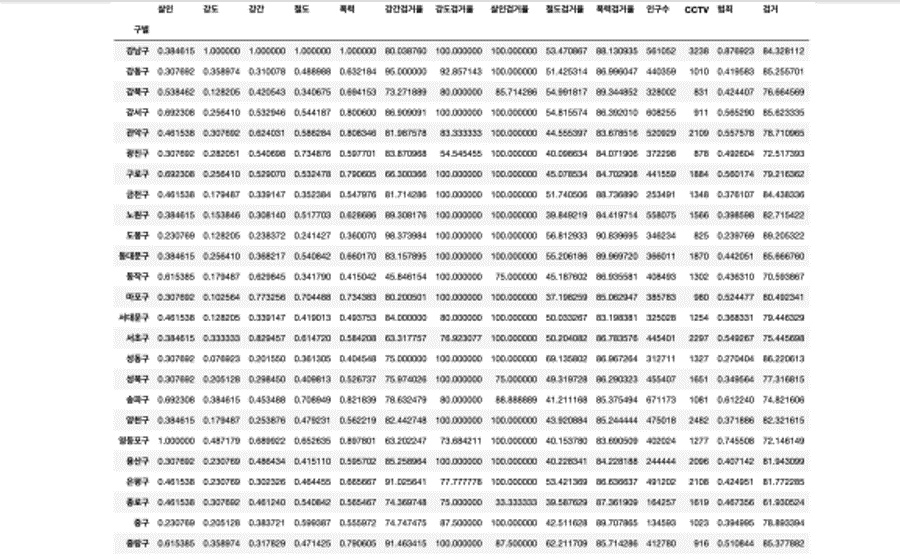
- 데이터 정리 완료
- 구별 CCTV 자료에서 인구수와 CCTV 수를 가져오자
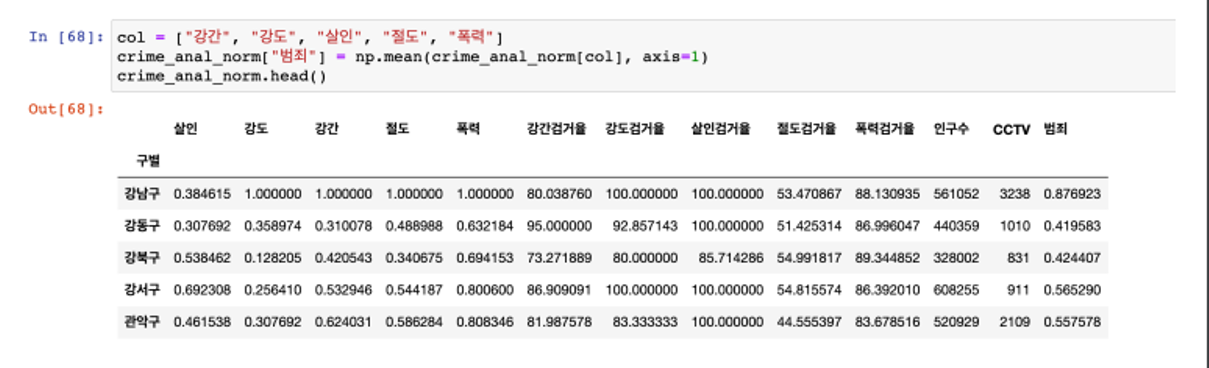
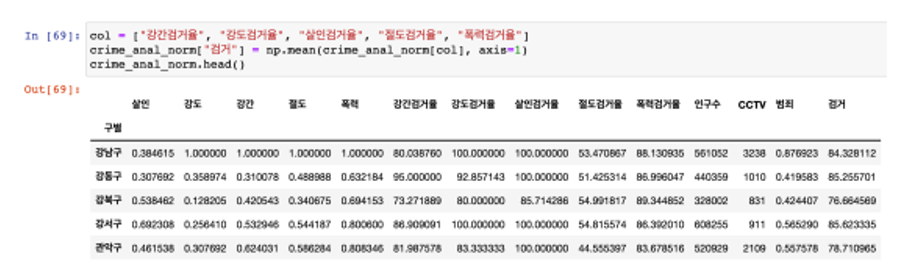
지표 데이터 추가
- 정규화된 범죄발생 건수 전체의 평균을 구해서범죄의 대표값으로 사용하자
- 검거율의 평균을 구해서 검거의 대표값으로 사용하자
재미있었던 부분
Google Maps에서 구별 정보를 얻어서 데이터를 정리하는 부분을 처음 접했는데 가입은 복잡했지만 데이터를 다룰때는 새롭게 재미있었다
어려웠던 부분
자주 나오는 코드 작성은 이제 눈에 익지만 새로운 구조를 많이 배워서 다 기억할 수 있을지 걱정이다
특히 오류가 한번 나면 해결하는데 오래걸린다
자료 자체가 최근 자료가 아니어서 오류 해결에 애를 먹었다
느낀점 및 내일 학습 계획
Google Maps에서 API를 이용하면서 드디어 본격적인 데이터를 활용하는구나 싶은 생각이 들었다
기대되기도 하지만 배울때마다 한번에 다 기억하기는 어렵다는 생각도 들었다
내일은 나머지 서울시 범죄 현황 데이터 분석을 공부하고 웹 데이터 분석도 공부할 예정이다

데이터 부트캠프 참여중