책 "파이썬 머신러닝 판다스 데이터 분석"을 바탕으로 정리한 게시글입니다.
누락 데이터 처리
누락 데이터 확인
info()
데이터프레임의 요약 정보 출력
velue_counts()
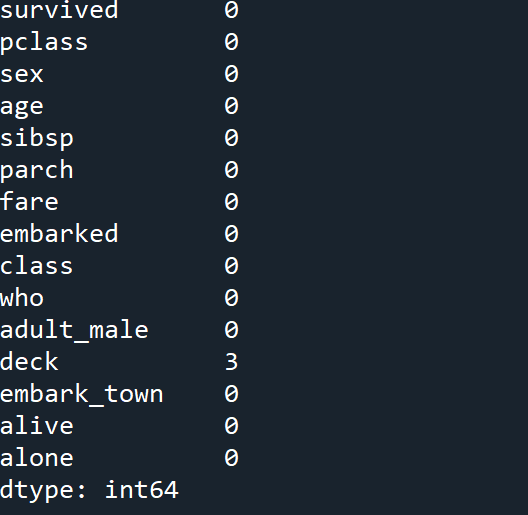
특정 열에 누락 데이터 갯수 확인
nan_deck=df['deck'].value_counts(dropna=False) #deck열의 누락 데이터 개수
#dropna를 false로 해줘야 누락 데이터 개수가 뜸isnull()
누락 데이터면 True, 데이터 존재시 False 반환
notnull()
유효한 데이터가 존재하면 True, 누락이면 False 반환
#isnull() 메소드로 누락 데이터 개수 구하기
print(df.head().isnull().sum(axis=0)실행 결과
누락 데이터 제거
dropna()
결측값이 들어간 데이터 삭제
df_trash=df.dropna(axis=1,thresh=500) # 결측값이 500개 이상인 열 모두삭제age열의 행 중에서 결측값이 있는 모든 행을 삭제
df_age+df.dropna(subset=['age'],how='any',axis=0)
#how는 기본적으로 any옵션 적용 -> 결측값이 하나라도 있으면 삭제
#how=all 이면 모든 데이터가 결측값일 경우에만 삭제됨누락 데이터 치환
fillna()
- 새로운 객체를 반환하기 때문에 원본을 변경은 inplace=True 옵션 추가
age의 결측값에 평균값 치환
mean_age =df['age'].mean(axis=0) #중간값은 median()사용
df['age'].fillna(mean_age,inplace=True) >> 누락 데이터가 NaN으로 표시가 되지 않을 경우
NaN대신 0,'-','?'으로 입력되어 있을 경우
import numpy as np 로 numpy 라이브러리 임포트
df.replace('?',np.nan,inplace=True)이웃하고 있는 값으로의 치환
finllna()메소드 옵션중
- method='ffill' : 직전 행의 값으로 변경
- method='bfill' " : 다음 행의 값으로 변경
중복 데이터 처리
중복 데이터 확인
duplicated()
행의 레코드가 중복되는지 여부 확인
중복되는 행이면 True, 처음 나오는 행이면 False 반환
col_dup=df['c2'].duplicated() #c2열의 데이터중 중복값 찾기중복 데이터 제거
drop_duplicates()
중복되는 행을 제거
- 원본 객체 변경시 inplace=True 옵션 추가
- subset 옵션에 열 이름 리스트를 전달해 해당하는 열 기준으로 판단 가능
df3=df.drop_duplicates(subset=['c2','c3'])데이터 표준화
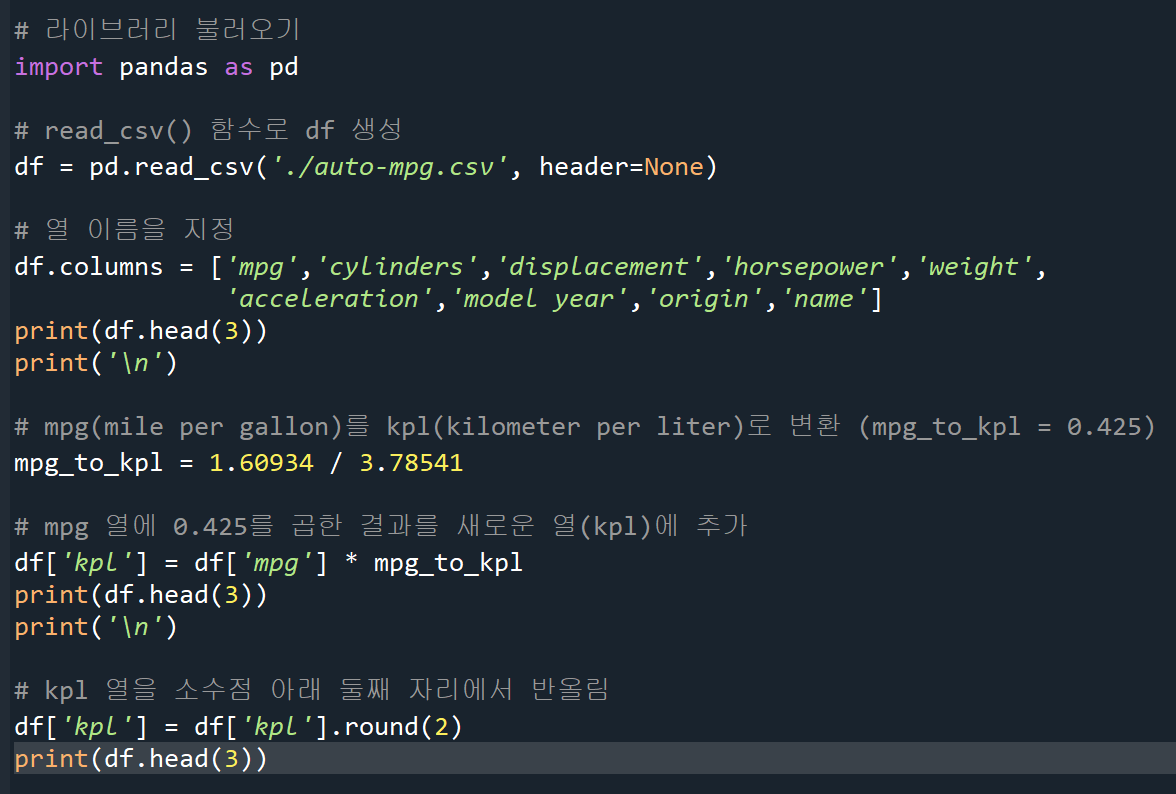
단위 환산
책 예제 코드
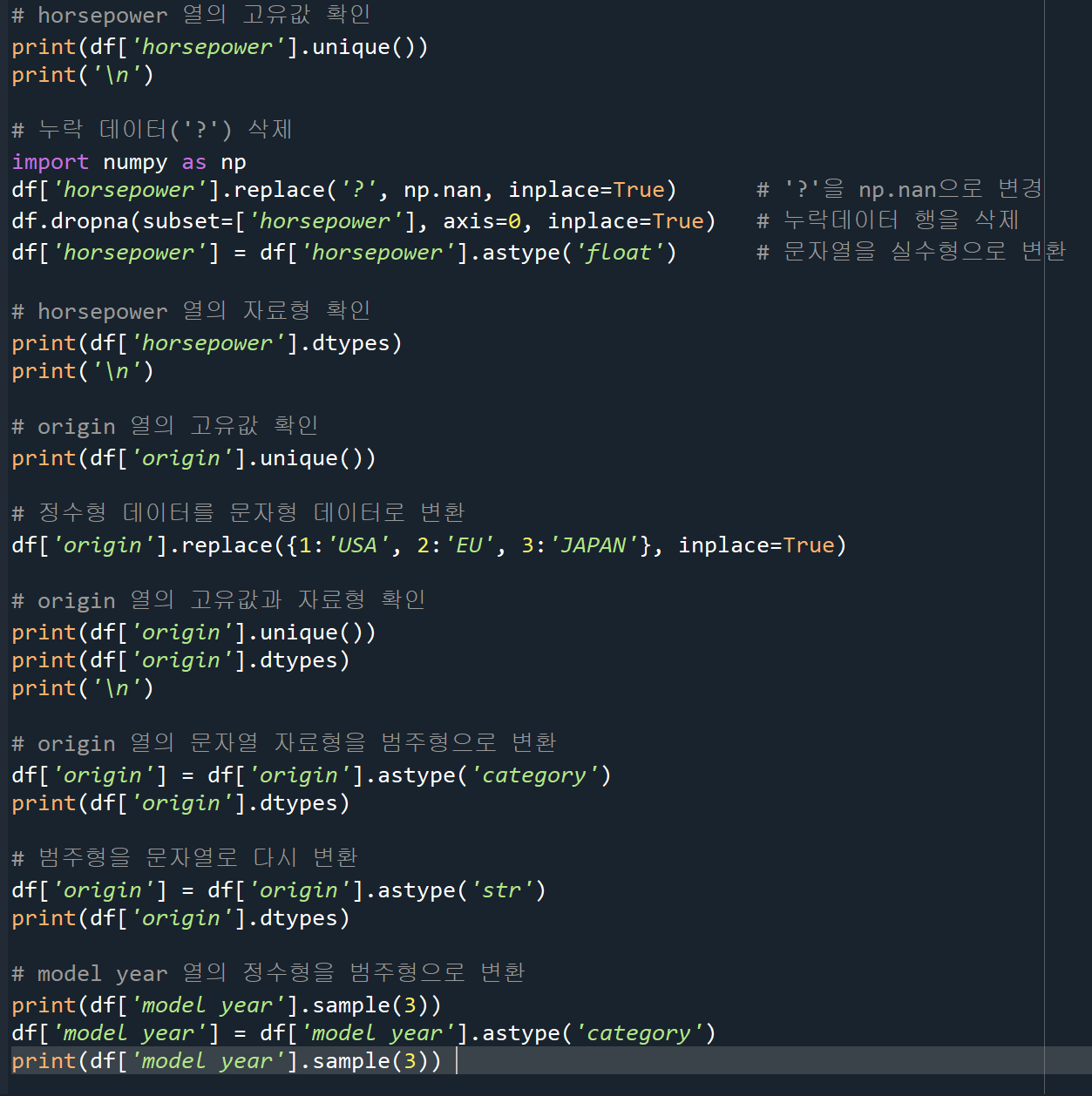
자료형 변환
- dtypes : 데이터 프레임의 각 열의 자료형 확인 / info()도 가능
- unique() : 열의 고유값 확인
- astype() : 자료형 변경 / float-실수형 category-범주형 srt-문자형
책 예제 코드
범주형(카테고리) 데이터 처리
구간 분할
경계값 구하기 - np.histogram()
나누려는 구간 (bin)개수를 bins옵션에 입력하면 각 구간에 속하는 값의 개수(count)와 경게값 리스트(bin_dividers)를 반환
count, bin_dividers=np.histogram(df['horsepower'],bins=3)
print(bin_dividers) # [46. 107.3333 168.6667 230.] 출력horsepower열을 저출력, 보통출력, 고출력으로 분할
# 3개의 bin에 이름 지정
bin_names = ['저출력', '보통출력', '고출력']
# pd.cut 함수로 각 데이터를 3개의 bin에 할당
df['hp_bin'] = pd.cut(x=df['horsepower'], # 데이터 배열
bins=bin_dividers, # 경계 값 리스트
labels=bin_names, # bin 이름
include_lowest=True) # 첫 경계값 포함
# horsepower 열, hp_bin 열의 첫 15행을 출력
print(df[['horsepower', 'hp_bin']].head(15))실행 결과
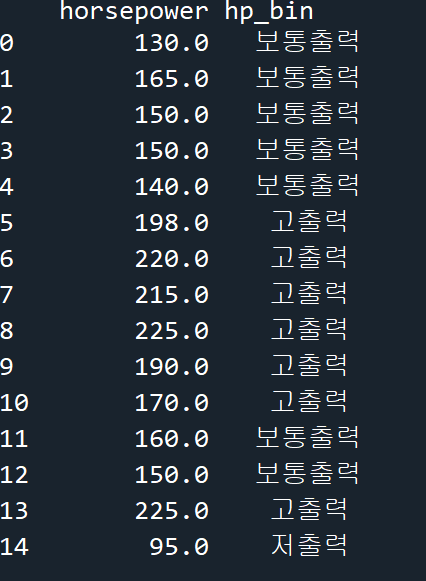
더미 변수 (원핫벡터, 원핫인코딩)
컴퓨터가 인식 가능한 입력값인 더미 변수(0,1)로 변환
이때, 0과 1은 어떤 특성이 존재하면 1, 존재하지 않으면 0으로 구분
get_dummies()
범주형 변수의 모든 고유값을 각각 새로운 더미 변수로 변환 -> 열의 고유값이 각각 새로운 더미 변수 열의 이름이 됨
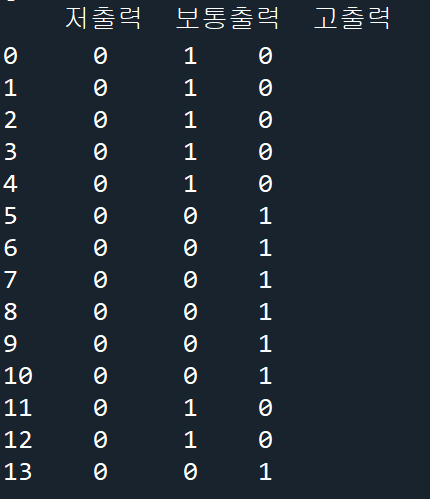
horsepower_dummies=pd.get_dummies(df['hp_bin'])
실행 결과
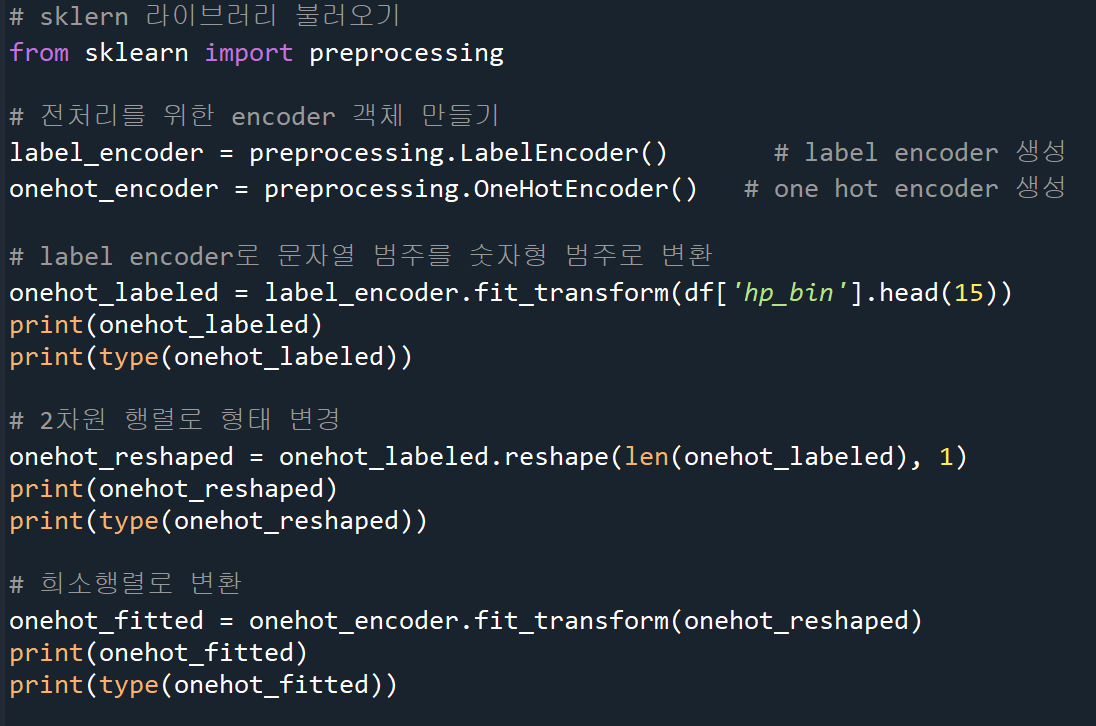
sklearn 라이브러리 이용
hp_bin열에 들어있는 범주형 데이터를 원핫벡터로 변환하면 희소행렬로 정리된다.
예제의 경우 1차원 벡터를 2차원 행렬로 변환하고 희소행렬로 변환한다. 희소 행렬은 (행,열) 좌표와 값 형태로 정리
(0,1)은 0행의 1열의 위치를 말하고 데이터 값은 숫자 1.0입력
책 예제 코드
정규화
숫자의 상대적 크기 차이를 없애기 위해서 사용
정규화 : 열에 속하는 데이터 값을 동일한 크기 기준으로 나눈 비율로 나타내는것 (범위 : 0~1 / -1~1)
Min-Max Normalization (최소-최대 정규화)
최소-최대 정규화는 데이터를 정규화하는 가장 일반적인 방법
각각의 최소값 0, 최대값 1로, 그리고 다른 값들은 0과 1 사이의 값으로 변환
(X - MIN) / (MAX-MIN)
이상치에 영향을 많이 받는다는 단점이 있음
Z-Score Normalization (Z-점수 정규화)
최소-최대 정규화의 단점을 보완한 정규화방식 (정규분포)
값이 평균 0으로, 평균보다 작으면 음수, 평균보다 크면 양수
계산되는 음수와 양수의 크기는 그 feature의 표준편차에 의해 결정됨
-> 데이터의 표준편차가 크면(값이 넓게 퍼져있으면) 정규화되는 값이 0에 가까워짐.
(X - 평균) / 표준편차
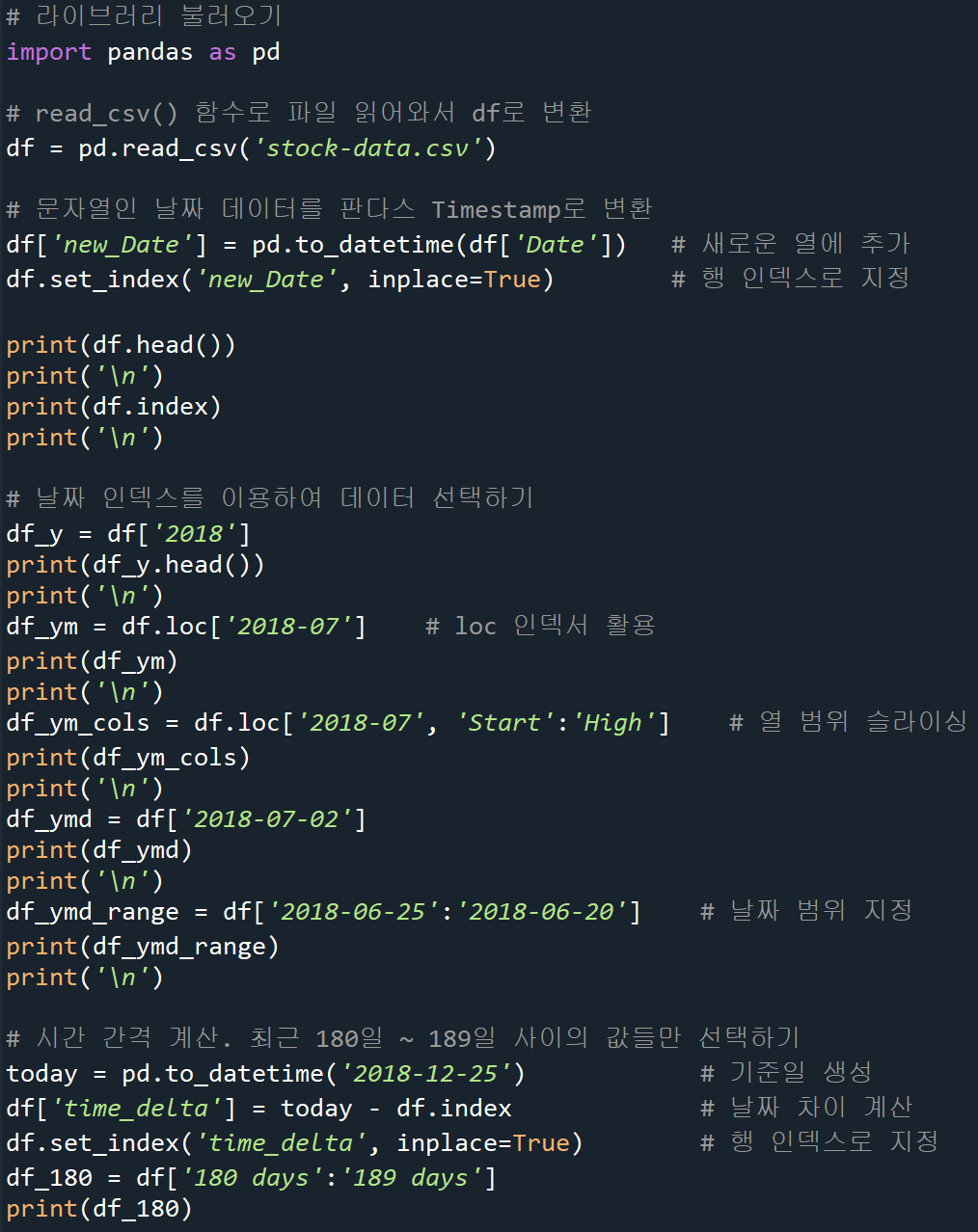
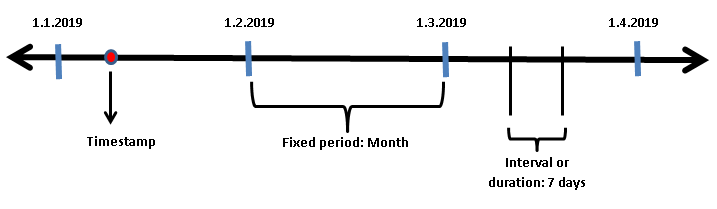
시계열 데이터
시계열 데이터 표현 두가지
Timestamp : 특정한 시점
Period : 두 시점 사이의 일정한 기간
다른 자료형을 시계열 객체로 변환
to_datetime()
문자열(등 다른 자료형) -> Timestamp(datetime64형) 변환
df['new_Date']=pd.to_datetime(df['Date'])to_period()
Timestamp -> period로 변환
- freg옵션에 기준이 되는 기간 설정 / 'D': 1일, 'M': 1달, 'A': 1년
ts_dates=pd.to_datetime(dates) # dates를 timestamp로 변환
pr_day= ts_dates.to_period(freq='D') #period로 변환시계열 데이터 만들기
date_range()
Timestamp 배열 생성
예제 - 한달 간격으로 각 달의 시작 날짜 6개를 생성
ts_ms = pd.date_range(start='2019-01-01', # 날짜 범위의 시작
end=None, # 날짜 범위의 끝
periods=6, # 생성할 Timestamp의 개수
freq='MS', # 시간 간격 (MS: 월의 시작일)
tz='Asia/Seoul') # 시간대(timezone)- 월의 마지막 날 : freq='M'
- 3개월 간격 : freq='3M'
period_range()
Period 배열 생성
pr_m = pd.period_range(start='2019-01-01', # 날짜 범위의 시작
end=None, # 날짜 범위의 끝
periods=3, # 생성할 Period 개수
freq='M') # 기간의 길이 (M: 월)- 1시간 간격 : freq='H'
- 2시간 간격 : freq='2H'
시계열 데이터 활용
날짜 데이터 분리
책 예제
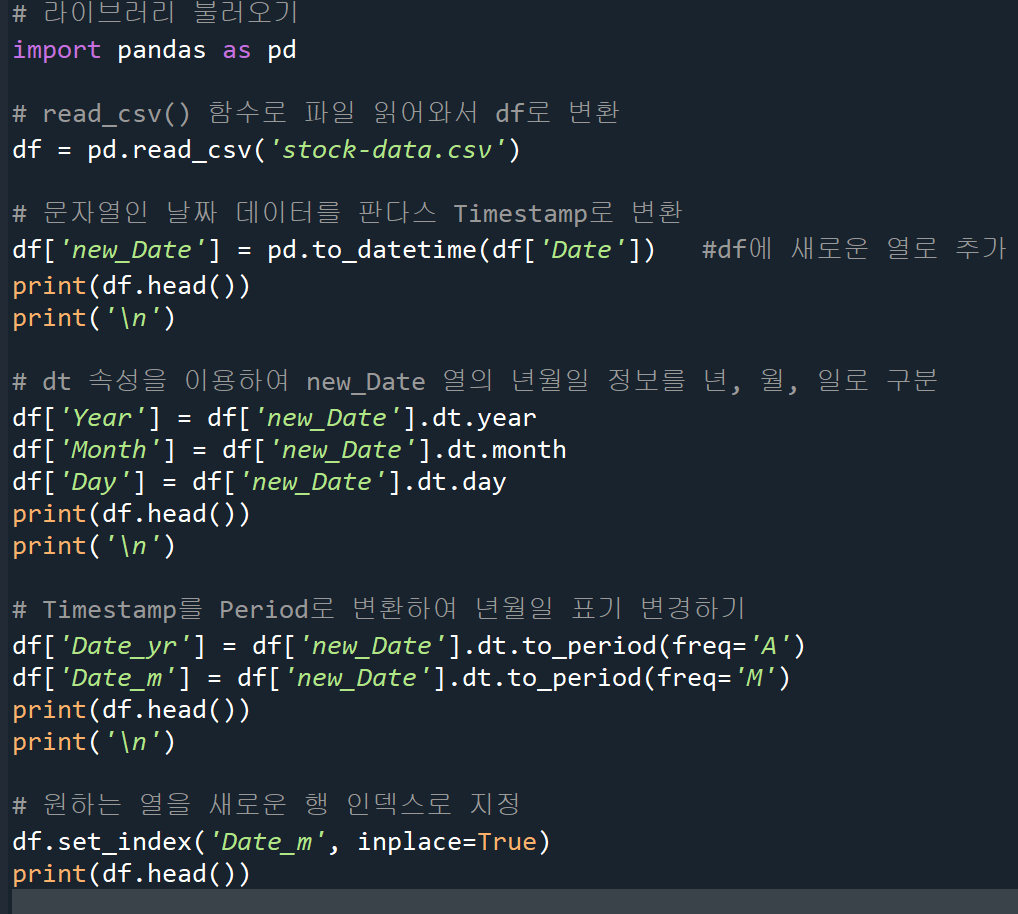
날짜 인덱스 활용
Timestamp로 구성된 열을 행 인덱스로 지정시 DatetimeIndex라는 고유 속성으로 변환(Period 동일)
책 예제