python으로 취업 사이트들을 웹 크롤링 하며 배운 점과 느낀 점을 기록합니다. 이 글은 노마드코더의 파이썬 강의를 토대로 작성됐습니다.

요약
우선 내가 생각했던, 제대로 된 크롤링은 아니었다. 내가 생각한 웹크롤링은 정보의 바다와도 같은 인터넷에서 고래가 되는 웅장한 일 같았다. 그러나 갓 파이썬과 모듈 개념을 배운 나에게는 사이트 하나의 HTML 데이터를 다루는 것부터 어려웠다.
웹 크롤링의 전체 로직
- 취업사이트의 HTML문서를 요청한다. (파이썬에서는 request모듈을 통한 요청.)
- 응답으로 온 페이지에서 페이지네이션 리스트 요소만 가져온 뒤 (BeautifulSoup을 사용), 마지막 페이지의 숫자값을 구한다.
- 첫번째 페이지부터 마지막 페이지까지 실행하는 반복문을 만든다.
- 데이터를 추출할 함수를 만든다. 구인 칸마다 반복문으로 해당 칸의 직업타이틀, 회사이름, 링크, 회사 위치를 얻는다.
- 그렇게 모은 배열을 csv의 엑셀함수를 통해서 엑셀 파일로 바꾼다.
1. requests 모듈 : HTML문서 요청하기
requests모듈은 파이썬 내장 모듈으로, HTTP통신중에서 요청을 하는데에 쓰인다.
내가 놀란 점은, 너무나 간단하다는 거!

이 한 줄로 나는 requests모듈의 다양한 함수들을 쓸 수 있게 됐다. (쓸 수만)
내가 처음으로 가져온 HTML문서는 indeed의 파이썬 검색 결과다.
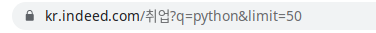

요청할 페이지의 URL을 그대로 가져와서 requests.get함수의 인자값으로 넣은 뒤 실행한다. (다른 HTTP 함수로는 post, put, patch가 있다. 언젠가 만질 일이 오겠지.)
이제 응답내용을 print해보면,
예상대로 html문서를 볼 수 있다. (사실 정말 반가웠다. 이렇게 칙칙한 텍스트들을 인터랙티브한 웹사이트로 바꿔주는 브라우저가 새삼 놀랍다.)
User-Agent
여기서 내가 강의와 다르게 했던 점은 user-agent부분이다. request모듈을 통해 받아온 데이터와 브라우저를 통해 보이는 화면의 데이터가 조금씩 다른 게 마음에 안 들었다. 그래서 내 브라우저에서 요청을 할 때 headers에 어떤 정보를 담는지를 찾아봤다.
친절하게 크롬의 개발자 도구에는 HTTP통신으로 주고받은 모든 데이터를 볼 수 있는 창이 있다. 바로 network.

그리고 requests는 요청을 할 때 특정한 headers를 사용자가 바꿀 수 있도록, 함수의 인자값으로 넣어 보낼 수 있다. 그렇게 해서 파이썬에서도 내 브라우저와 동일한 HTML문서를 볼 수 있었다.
2. BeautifulSoup4 : 페이지네이션 얻기
BeautifulSoup는 HTML을 텍스트로 파싱해주고, 전체 HTML문서에서 내가 원하는 요소만을 얻을 수 있게 해주는 모듈이다. 파이썬 내장 모듈이 아니기 때문에 따로 설치를 해야 한다.


BeautifulSoup를 import해준 뒤, 1단계에서 받아왔던 HTML문서를 파싱해준다. 이제 soup변수에 해당 페이지 전체 HTML이 할당된 셈이다.

내가 원하는 요소는 페이지네이션이므로, 페이지네이션을 찾으면 된다. (실제 사이트의 페이지를 inspect하는 과정이 있었지만 생략) 주로 요소들의 class이름을 이용했다.
3. 모든 페이지에 대한 반복문 만들기
마지막 페이지를 구했으므로, 모든 페이지에 대해서 반복문을 쓸 준비가 된 셈이다.
range
새로 알게 된 함수는 range로, 숫자값을 인자값으로 넣으면 해당 숫자의 갯수만큼 0부터 나열된 배열을 얻을 수 있다.
ranged_by_ten = range(10)
print(list(ranged_by_ten))
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]반복문에 들어갈 땐 list함수를 쓸 필요없이, 리스트로 변환해주는 것 같다. 앞으로 배열에 대한 반복문을 다룰 때 많이 쓰게 될 함수.
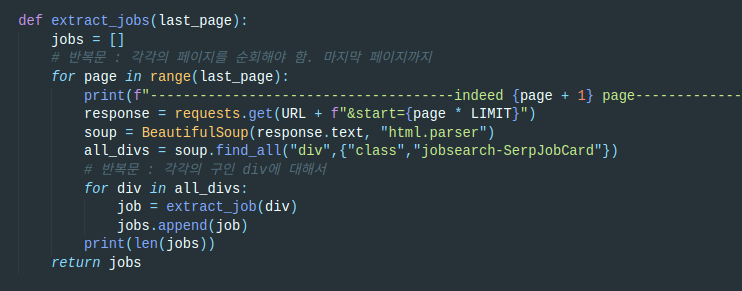
페이지 숫자에 따른 요청
페이지에 대해서 요청하고 HTML문서를 파싱하는 과정은 위와 동일하다. 다만 URL에 들어가는 페이지 파라미터만 달라진다.
이제 all_divs에 해당 페이지의 모든 구인 칸이 할당된다.
빈 리스트와 append
모든 페이지에 대해 반복문을 실행하기 이전에, 빈 리스트를 하나 선언해두었다. indeed사이트의 모든 구인 정보(파이썬)가 담길 리스트이다.
그리고 all_divs에 대한 반복문이 실행된다.
각각의 div에 대해 함수를 실행하고, return받은 값을 하나씩 배열에 넣게 된다.
마지막 페이지가 10이고 한 페이지당 구인공고가 50개 올라왔다면, 각각의 페이지의 각 구인공고를 하나씩 추출하며 배열에 집어넣는 식이다. 최종적으로 직업명, 회사명, 회사위치, 링크가 담긴 객체가 총 500개 쌓이게 된다.
4. 데이터 추출 함수
위의 반복문에서 호출한 함수이다. 인자값으로는 각각의 구인공고 div가 들어온다.
내가 필요한 데이터는 총 4가지. 직업명(title), 회사명(company), 회사위치(location), 링크(link)다.
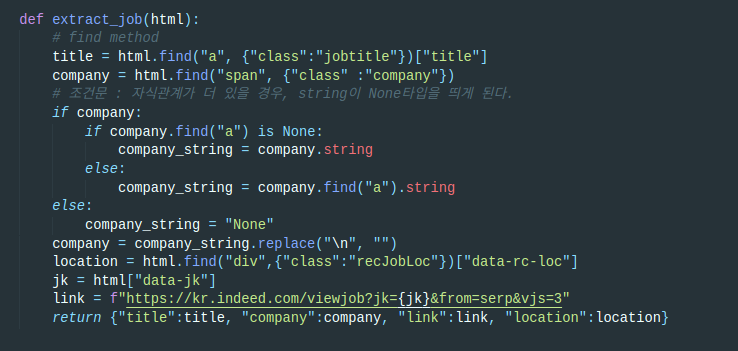
생각보다 별 건 없다. BeautifulSoup모듈이 다 한다고 보면 된다. 웹사이트에서 하나하나 요소들을 검사하고, 각각의 태그명과 class명을 알아내면 90%는 끝난 셈이다.
그러면 BeautifulSoup의 find를 통해서 각 요소들을 가져온 뒤, 요소들의 attribute나 BeautifulSoup의 string을 이용해서 문자열만 가져온다.
마지막으로 4개의 변수를 하나의 객체에 담아서 반환한다.
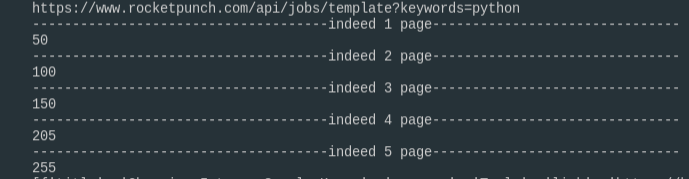
페이지마다 50개씩 쌓이는 공고들. 5페이지니까 총 250개다. 나머지 5개는 고생했다고 보너스로 준 것 같다.
뿌듯.
5. CSV : 데이터를 엑셀 파일로 바꾸기
이쯤되면 내가 파이썬을 만지고 있는지 파이썬 모듈들을 만지고 있는지 분간이 되지 않는다. CSV는 파이썬에서 다른 확장파일을 다루기 위해 쓰이는 내장 모듈이다.
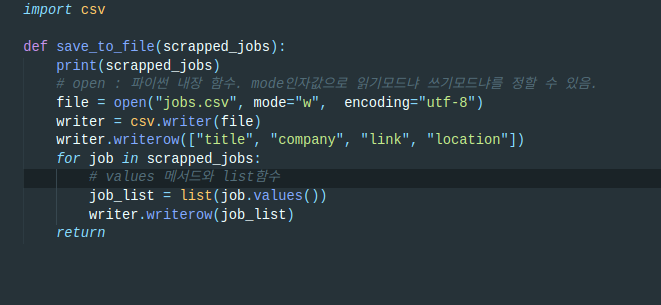
다른 코드는 무시하고, 반복문안의 코드만 보시면 된다. 객체에 들어있는 각각의 구인공고에 대해서 values함수를 이용해 value들만 가져온 뒤, list로 만든다.
[직업명, 회사명, 회사위치, 링크]
이제 CSV의 함수 csv.writerrow를 쓸 차례다. 말 글대로 csv파일에다, 하나의 행당 하나의 리스트를 넣겠다는 얘기다.
이렇게 해서 인디드에서 총 255줄의 구인공고 엑셀파일을 만들었다.
로켓펀치
로켓펀치에서는 총 600개의 구인공고를 가져올 수 있었다.
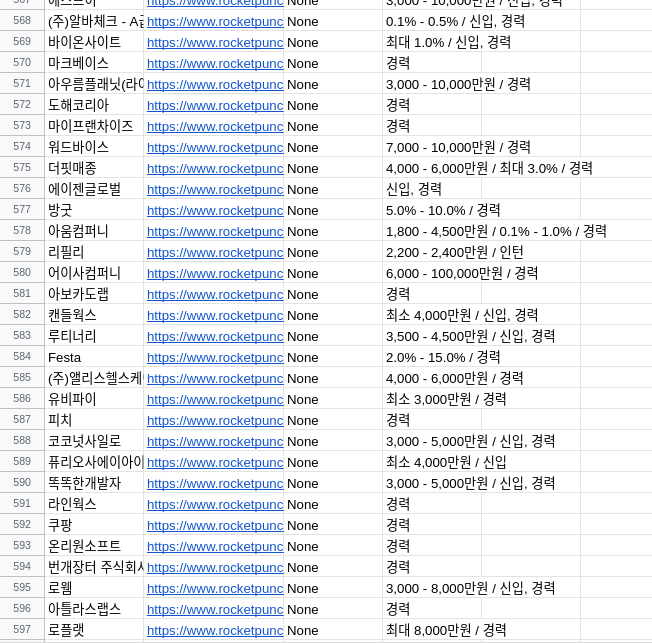
가슴이 웅장해진다. 끝.