
프로젝트를 진행 하다보면 DB 설계를 하고 개발에 들어가며 처음에는 큰 문제없이 잘 작동하다가 많은 사람들이 사용하게 됨에 따라 서버 서능, DB 설계의 문제나 혹은 DB 최적화가 되어있지 않으면 서비스가 느려지는 현상이 발생하게 된다. 그 결과 관계형 데이터베이스에 최적화를 위해 인덱싱을 하게 되고 이점은 굉장히 중요한 작업이며 어떻게 인덱싱을 하냐에 따라 퍼포먼스가 다르게 나타난다.
엘라스틱 서치 역시 데이터에 다양한 규칙으로 최적화된 인덱싱을 처리 할 수 있어서 검색에 빠른 성능을 보이게 된다. 이번 포스팅에서는 엘라스틱 서치에 기본 개념들을 정리하고자 한다.
Elasticsearch란?
Elasticsearch는 Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색엔진이다.
Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, 거의 실시간으로 저장, 검색, 분석할 수 있다.
*루씬 라이브러리 : 검색 어플리케이션을 만드는데 사용하는 검색 라이브러리.
Elasticsearch와 RDB의 비교
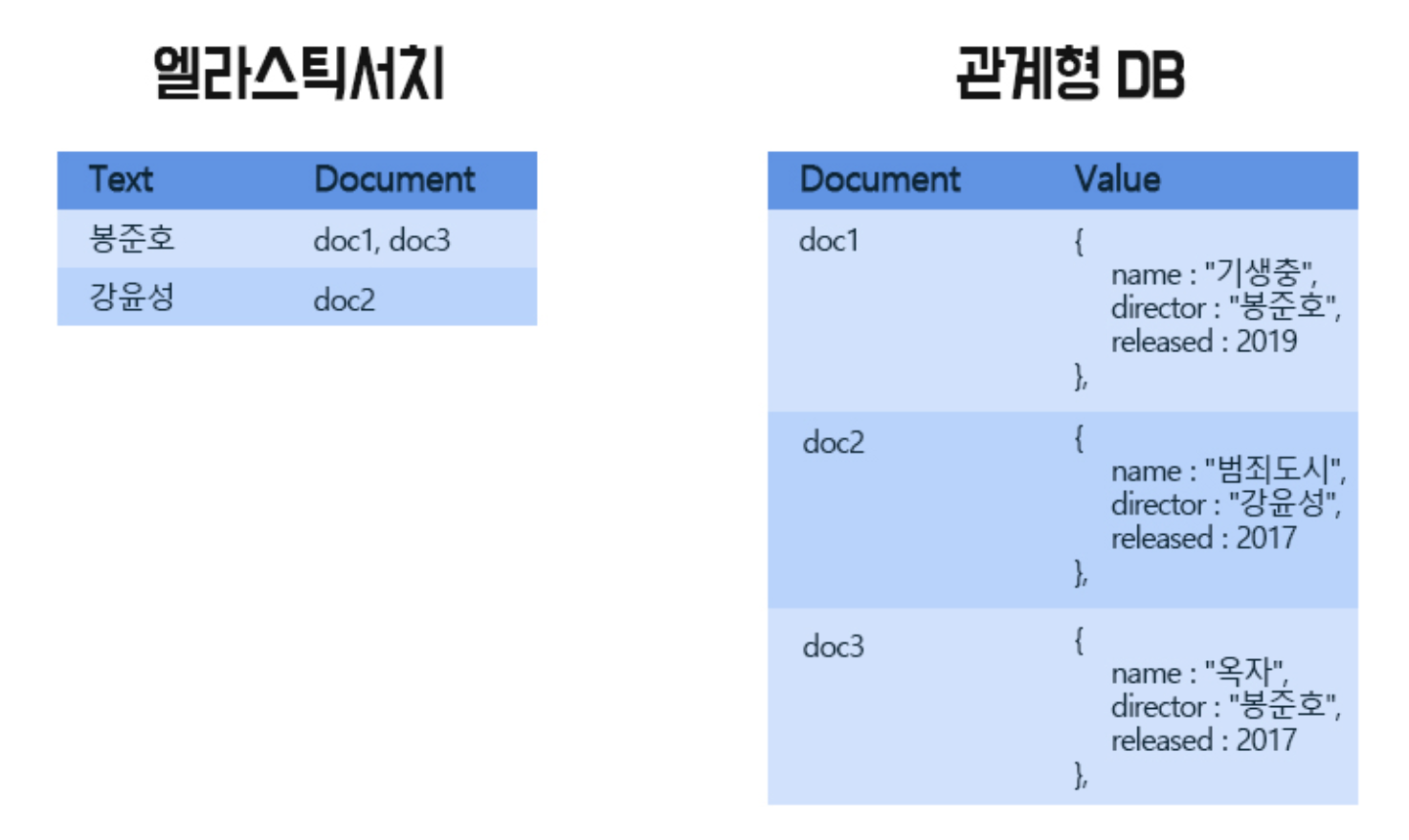
위의 사진처럼 관계형 데이터베이스는 document 중심이라면 Elasticsearch는 텍스트 중심이라고 보면 된다.
Ex) 사용자가 영화감독 봉준호를 검색하는 순간 RDB는 doc1 ~ doc3을 하나하나 확인하며 봉준호의 영화 데이터 위치를 찾지만, Elastic search는 검색하는 순간 데이터를 찾을 수 있기 때문에 RDB 검색 속도보다 현저히 빠르다고 할 수 있다.
아래 사진은 Elasticsearch와 RDB의 각각 대응되는 용어들을 나타낸다.
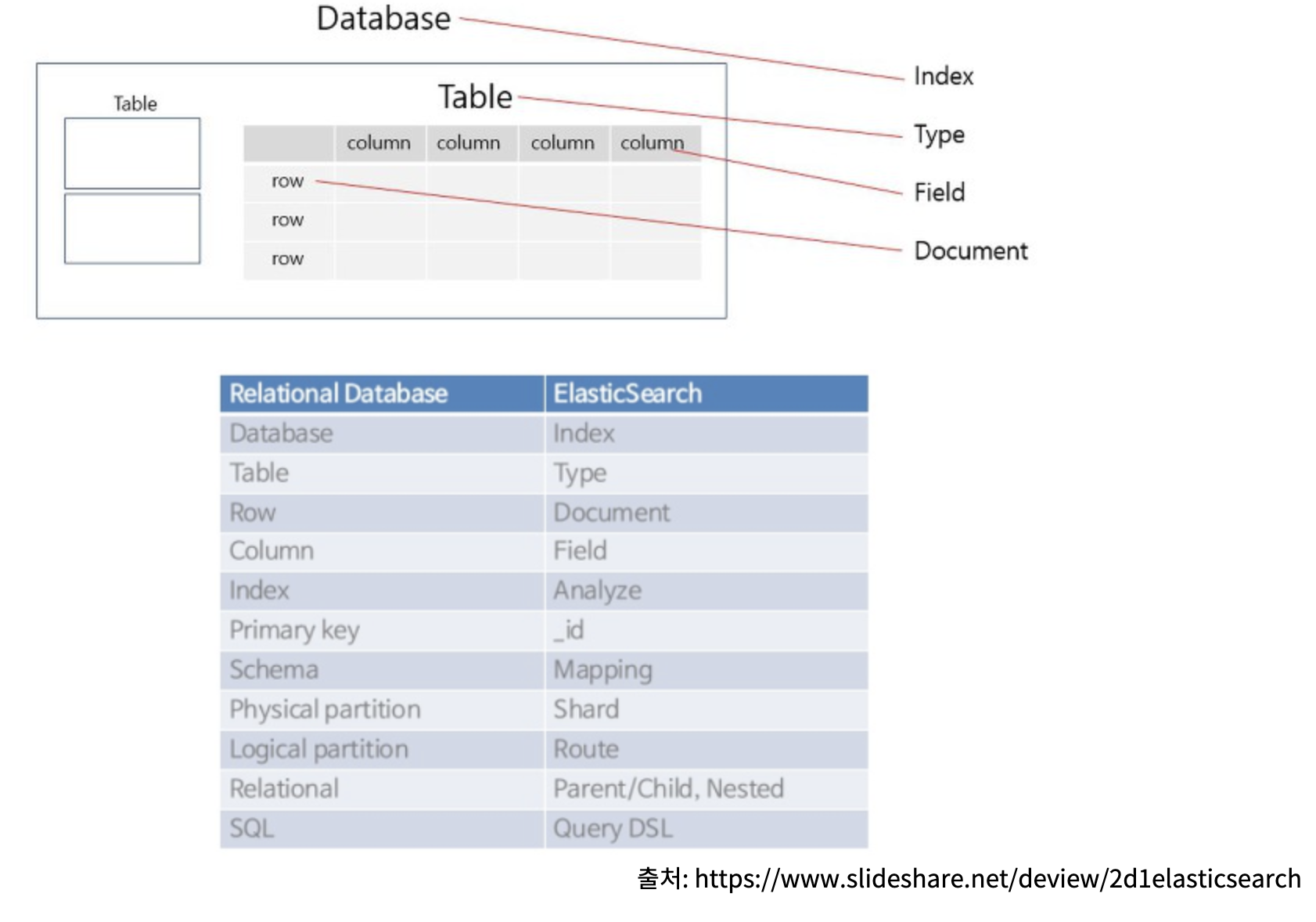
Elasticsearch 아키텍쳐 / 용어 정리

클러스터(Cluster)
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합.
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할 수도 있음
노드(Node)
Elasticsearch를 구성하는 하나의 단위 프로세스를 의미.
그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있다
master-eligible node
클러스터를 제어하는 마스터로 선택할 수 있는 노드.
- 인덱스 생성, 삭제
- 클러스더 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당할 것인지
Data node
데이터와 관련된 CRUD 작업과 관련있는 노드.
- 이 노드는 CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요하며, master 노드와 분리되는 것이 좋음
Ingest node
데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할.
Coordination only node
data node와 master-eligible node의 일을 대신하는 이 노드는 대규모 클러스터에서 큰 이점이 있음. 즉 로드밸런서와 비슷한 역할
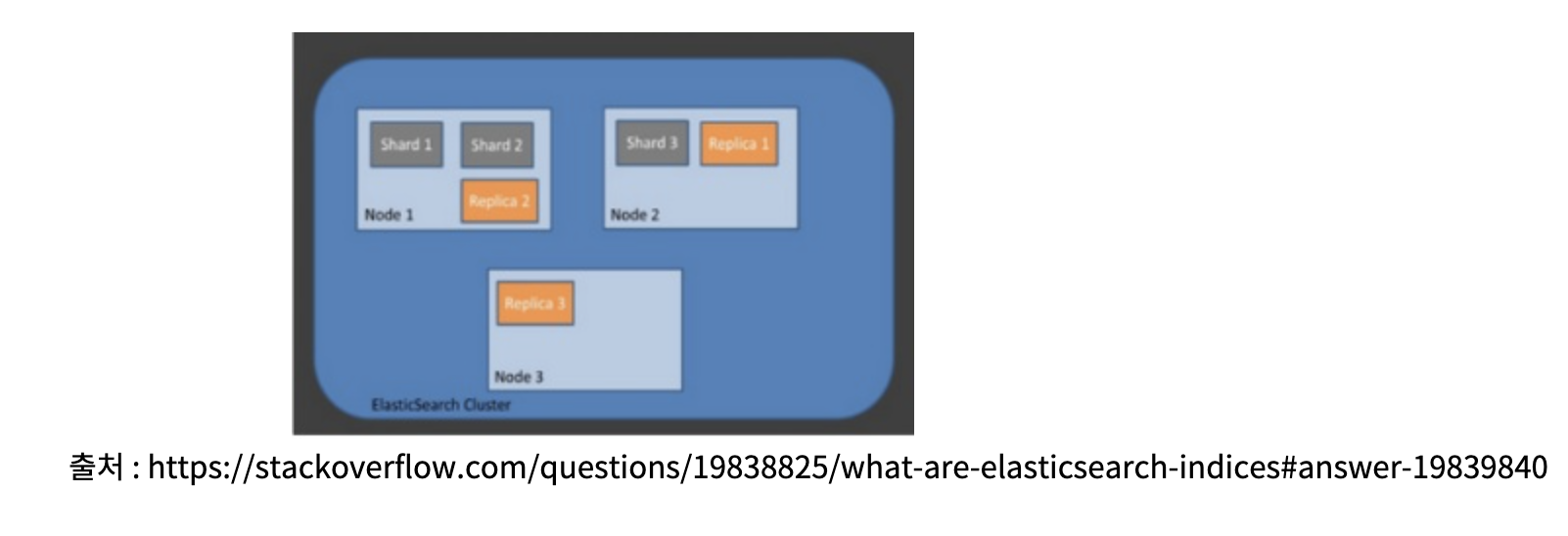
인덱스(index) / 샤드(Shard) / 복제(Replica)
Elasticsearch에서 index는 RDBMS에서 database와 대응하는 개념.
샤딩(sharding)은 데이터를 분산해서 저장하는 방법
즉, Elasticsearch에서 스케일 아웃(로드밸런싱)을 위해 index를 여러 shard로 쪼갠 것
기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 함.
replica는 또 다른 형태의 shard라고 할 수 있음.
노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것.
따라서 아래 사진 처럼 replica는 서로 다른 노드에 존재할 것을 권장
Elasticsearch 특징
-
Scale out(로드밸런싱) : 샤드를 통해 규모가 수평적으로 늘어날 수 있음
-
고가용성 : Replica를 통해 데이터의 안정성을 보장
-
Schema Free : Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
-
Restful : 데이터 CRUD 작업은 HTTP Restful API를 통해 수행함
장단점
장점
-
오픈소스 검색 엔진이기 때문에 무료로 사용 가능
-
오픈소스의 장점처럼 많은 전문가들이 버그에 빠르게 대응
-
방대한 양의 데이터를 신속하게 처리 가능
단점
-
진입장벽이 있음
-
Document간의 조인을 수행할 수 없음 (두번 쿼리로 해결 가능)
-
트렌젝션이 제공되지 않음
마무리
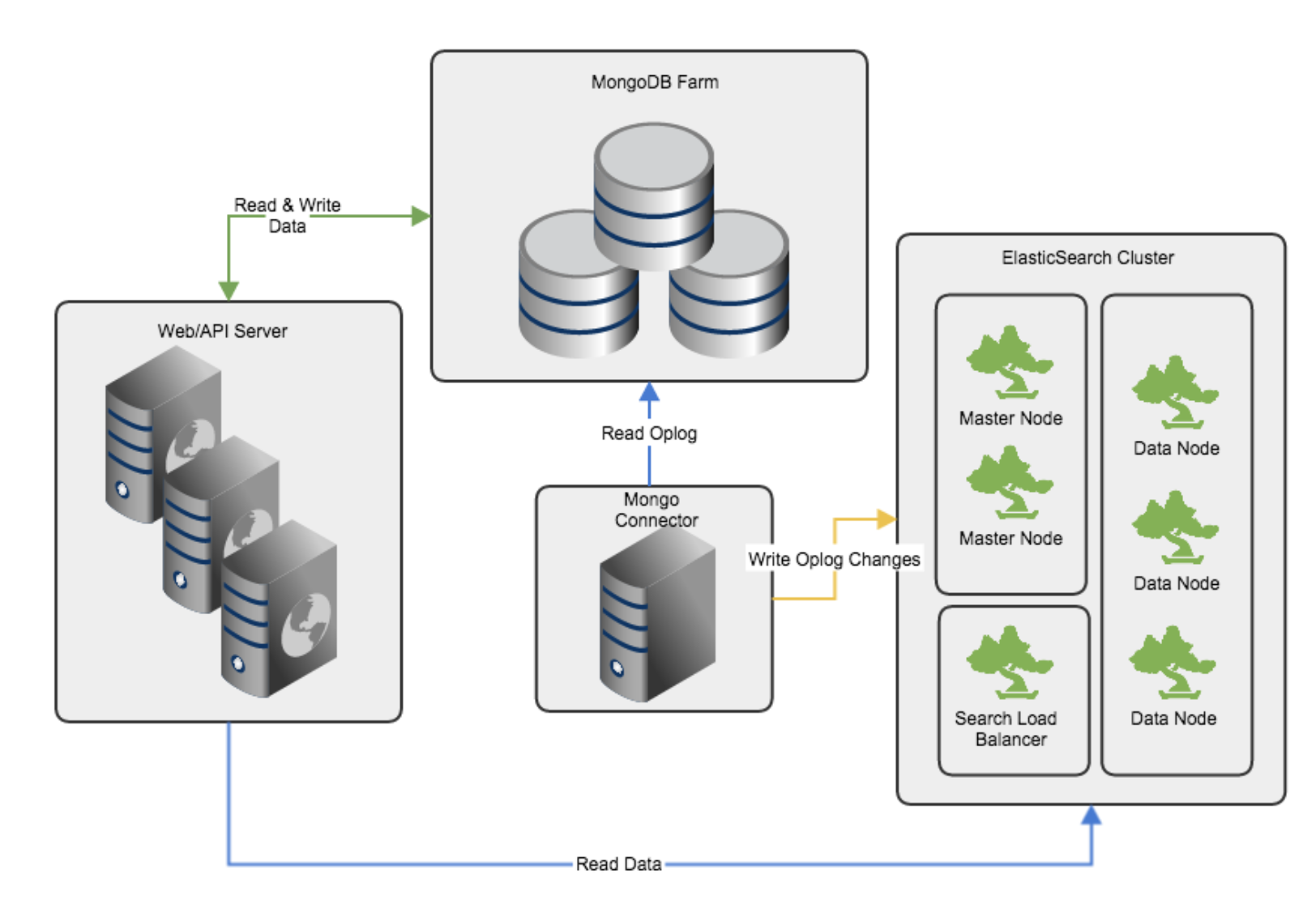
위의 아키텍처 이미지처럼 사용자의 요청에 따라 디비에 저장되고 검색 혹은 분석이 필요한 부분만을 데이터를 추출하여 엘라스틱 서치에 자동 저장시켜서 방대한 양의 데이터를 빠르고 다양하게 검색할 수 있도록 처리하게 된다.
추가적으로 디비에서 필요한 데이터를 추출하여 자동적으로 엘라스틱에 데이터를 넣는 부분을 담당하는 Logstash 등을 사용한다. 위의 그림에서 MongoConnector를 나타낸다
참고자료
https://victorydntmd.tistory.com/308,
https://sudarlife.tistory.com/entry/Elasticsearch-%EA%B0%84%EB%8B%A8-%EA%B0%9C%EB%85%90-%EC%9E%A5%EB%8B%A8
