7월달 부터 Attention paper 논문 읽기 및 스터디를 진행했습니다. 이번 콘텐츠는 제가 발표를 맡은 논문입니다.
Today's Content
An_Image_is_worth_16x16_words: Transformer For Image Recognition At Scale
0. Abstract:
- Reliance on CNN is not necessary and a pure transformer applied diriectly to sequence of image patches can perform very well on image classification.
- Pretrained on large amounts of data and transferred, excellent result with fewer computational resource.
요약에서 가장 중요하다고 생각하는 두가지를 적어봤습니다.
- 본 논문에서는 image classification에서는 SOTA는 무조건 CNN 이 아니라는 것을 보여줬습니다.
- 또한 Large Scale Dataset으로 pretrain한 경우 적은 computational resource로 좋은 결과를 냈다고 합니다.
1. Motivation
먼저 해당 논문이 왜 나왔는지 부터 알아보겠습니다. 그건 Self-Attention-based architecture들중 Transformer가 NLP에서 엄청나게 성공적인 결과를 냈기 때문입니다. Transformer의 Computational efficiency와 scalability때문에 엄청나게 큰 데이터 셋도 학습할 수 있게 되었고 이로 인해 NLP Task들이 잘 작동하는것을 확인할수 있었습니다. 기존에 Self-attention을 Computer Vision task에 적용한 적은 있었지만 모두 CNN과 Attention 모듈을 두어서 적용했습니다. 본 논문에서는 CNN을 사용하지않고 NLP에서 사용하는 Pure Transformer를 이미지에 적용해 보자는 것으로 부터 시작되었습니다.
2. Limitation
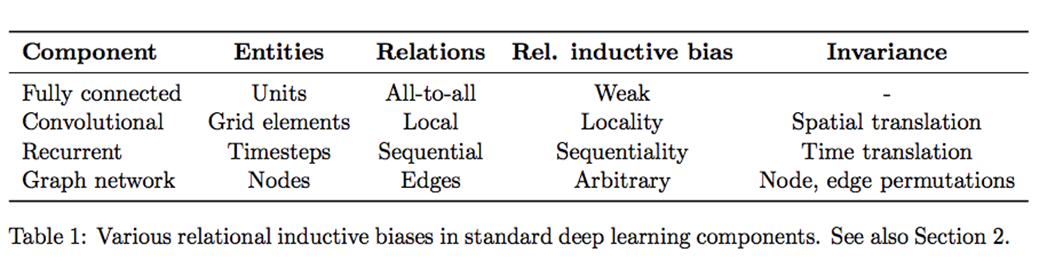
Limitation: 먼저 ViT의 한계 부터 먼저 보자면 Vit는 sequential한 데이터를 학습하는것 이기 때문에 Image specific inductive bias가 부족합니다. 그렇기에 Vit에서는 엄청난 양의 데이터셋을 이용해 이 문제를 해결합니다. 즉 CNN에서는 Locality Inductive bias가 존재하고 이것을 통해서 상대적으로 적은 데이터 셋으로도 좋은 성능을 냈습니다. 하지만 Vit는 아니기 때문에 데이터의 양으로 승부를 봅니다.
Q. Image에서는 어떤 Inductive bias가 중요할까?
A. Locality가 중요하다.
Inductive bias: 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용되는 추가적인 가정을 의미합니다.
ref)https://stackoverflow.com/questions/35655267/what-is-inductive-bias-in-machine-learning
3. Method
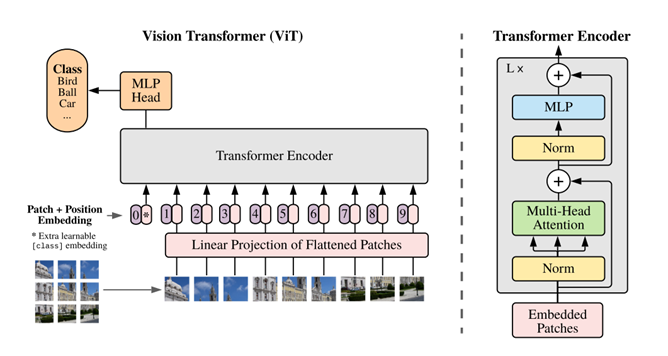
NLP-> sentence를 tokenize
Vit-> image를 patch 단위로 자른뒤 Linear projection
즉 Visiton Transformer는 최대한 NLP의 pure transformer 구조를 따라가기 위해 이미지를 sequential 하게 flatten 시켜 input으로 넣어줍니다.
과정을 크게 3가지로 나눠 보자면 아래와 같습니다.
1. Linear projection and patch embedding
2.Transformer Encoder
3.MLP_head
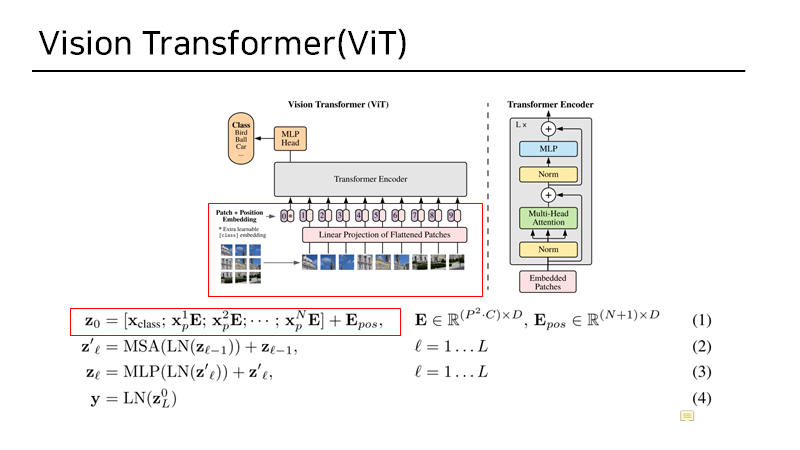
1. Linear Projection and patch embedding
2. Transformer Encoder
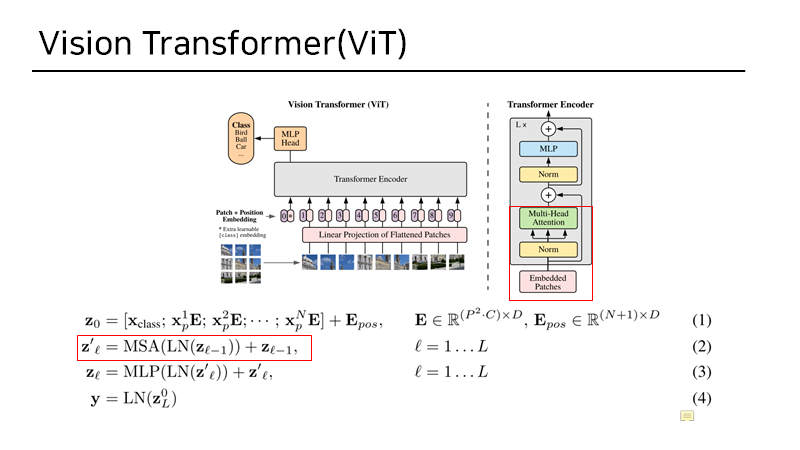
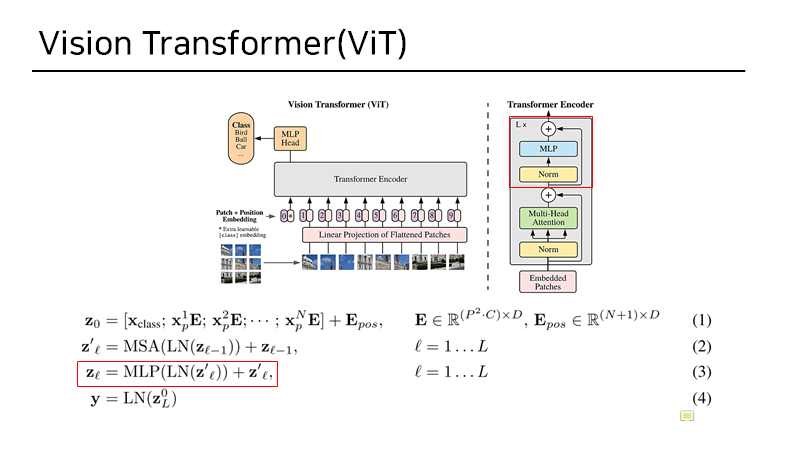
3. MLP_head
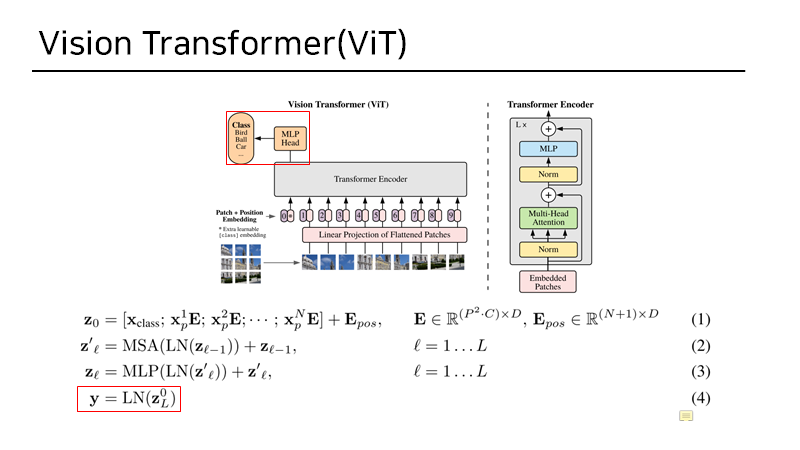
4. Experiments
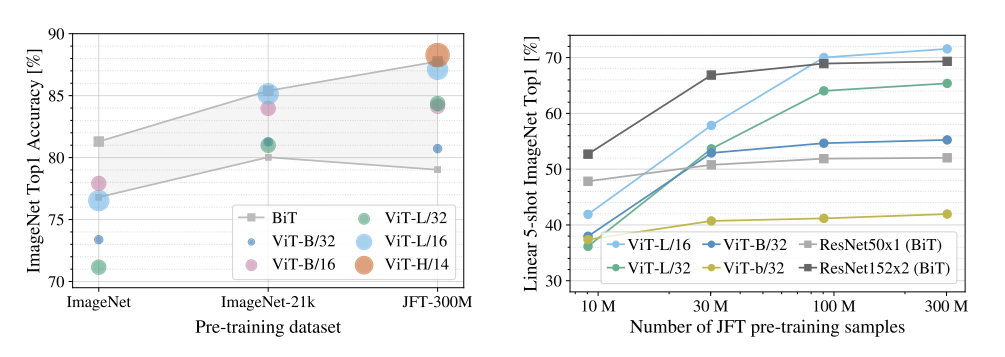
위 표를 보면 데이터 셋의 크기가 커질 수록 Vit의 Top 1 Accuracy가 증가하는 것을 확인 할 수 있습니다. 이때 BiT는 Resnet152을 의미하고 ViT-B/32는 ViT모델 중 base variant이며 patch_size=32를 의미합니다.
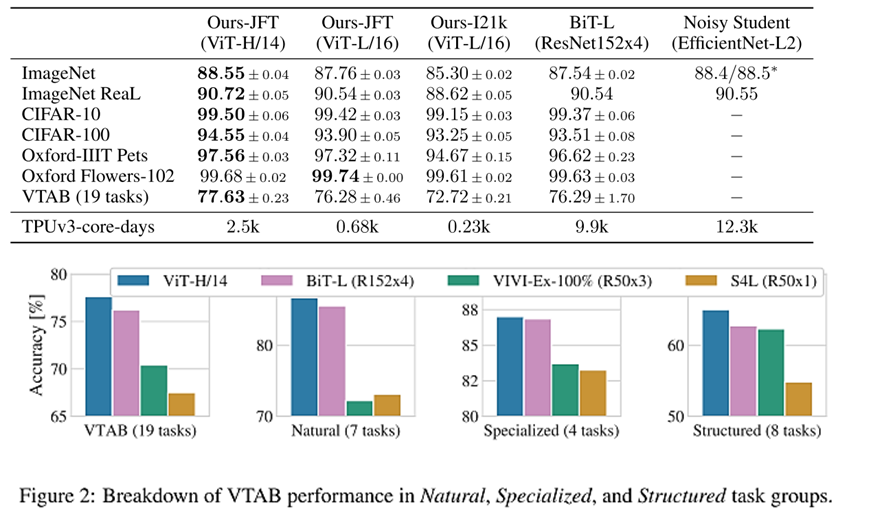
위 결과를 보면 Large/Huge dataset에 대해서는 BiT보다 좋은 성능을 내는것을 확인 할 수 있었습니다.

좌측 부터 patch embedding시 사용된 28개의 filter들을 시각화 한 결과, Position embedding시 사용된 Linear layer의 Cosine similarity를 구한 결과, Mean attention distance를 구한 결과 입니다.
