BERT
사전학습된 대용량의 레이블링 되지 않는 데이터를 이용하여 언어 모델을 학습하고 이를 토대로 문서 분류나 질의 응답, 번역등을 위한 신경망을 추가하는 전이 학습 방법
대용량의 데이터를 직접 학습시키기 위해서는 매우 많은 자원과 시간이 필요하지만 BERT 모델은 기본적으로 대량의 단어 임베딩 등에 대해 사전 학습이 되어 있는 모델을 제공하기 때문에 상대적으로 적은 자원만으로도 충분히 자연어 처리의 여러 일을 수행할 수 있다.
bert는 사전 훈련모델 중 하나임. 따라서 bert를 검색하면 어떻게 fine tunning을 하는지 잘 찾을 수 있음.
이해
문장의 일부를 다른 단어로 대체하거나 제거한 뒤 원래의 문장을 복원하는 방식으로 학습한다. 즉 I번째 토큰이 MASK라는 토큰으로 대체되었다면 확률이 가장 높은 토큰을 찾아 I번 째 토큰 자리에 다시 넣어줄 수 있도록 해당 조건부 확률을 학습하는 것이다.
언어 모델을 학습시켰다면 이를 분해한 뒤 그 속에 있는 잠재 변수를 꺼내어 문장 또는 문서의 임베딩으로 활용할 수 있다. 만약 학습한 언어모델이 multilayer perceptron과 softmax 함수를 이용해 문자열을 확률공간으로 사용했다면 softmax의 바로 이전 layer의 출력값을 임베딩으로 사용할 수 있다.
임베딩을 얻었다면 풀고자 하는 문제에 맞추어 알고르짐을 적용하면 된다. 언어모델의 학습 과정에서부터 딥러닝 알고리즘을 사용하므로 임베딩을 얻은 후에도 동일한 알고리즘을 이용해 학습시킬 수 있다.
구조
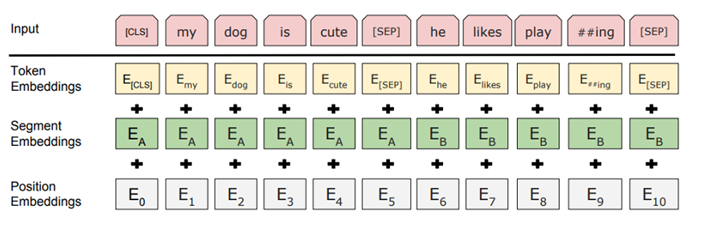
1) 토큰 임베딩
토큰 임베딩은 Word piece 임베딩 방식을 사뇽한다. 이 방법은 자주 등장하면서 가장 긴 길이의 sub-word를 하나의 단위로 만든다. 즉 자주 등장하는 단어는 그 자체가 단위가 되고, 자주 등장하지 않는 단어는 더 작은 sub-word로 쪼개어진다.
이는 이전에 자주 등장하지 않은 단어를 전부 Out-of-vocabulary로 처리하여 모델링의 성능을 저하했던 문제를 해결할 수 있다.
입력받은 모든 문장의 시작으로 CLS 토큰(Special classification token)이 주어지며 이 토큰은 모델의 전체 계층을 다 거친 후 토큰 시퀀스의 결합된 의미를 가지게 된다. 여기에 간단한 classifier를 붙이면 단일 문장, 또는 연속된 문장을 분류할 수 있고 만약 분류 작업이 아니라면 이 토큰을 무시한다. 또한 문장의 구분을 위해 문장의 끝에 SEP 토큰을 사용한다.
2) Segment Embeddings
토큰으로 나누어진 단어들을 다시 하나의 문장으로 만들고 첫번 째 SEP 토큰까지는 0으로 그 이후 SEP 토큰까지는 1 값으로 마스크를 만들어 각 문장들을 구분한다.
3) Position Embeddings
토큰의 순서대로 인코딩 하는 것을 뜻한다.
BERT는 위 세 가지 임베딩을 합치고 이에 정규화와 Dropout을 적용하여 입력으로 사용한다.
