
-
requests를 활용한
-
find(), split() 등을 활용한 문자열 파싱
-
정규식(regex)를 활용한 패턴검색
-
쿼리스트링에 대한 이해
-
beautifulsoup을 활용한 편리한 html 파싱
-
css selector를 활용한 손쉬운 파싱
네이버 시장지표
환율지표 시장은 이렇게 생겼다.
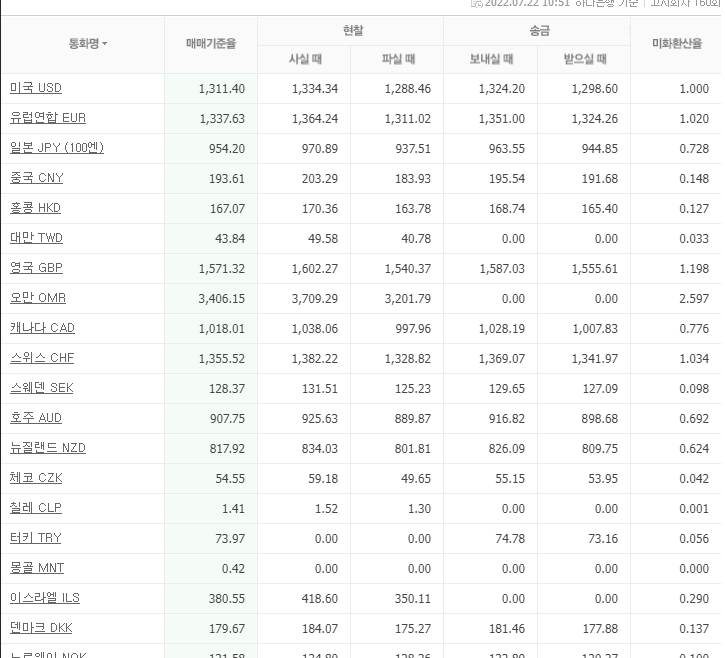
처음 미국 usd를 찾으면
market_price = res.text
usd_pos = market_price.find("미국 USD")
print(usd_pos)
하지만 우리가 찾아야 될 것은 "미국 usd"가 아니라 한참 뒤의 환율 가격, "미국 usd"가 있는지만 확인하는 용도가 된다. 때문에 다음과 같은 방법을통해 찾을 수 있다.

print(market_price.split('')[1].split("")[0])
정규식(Regular Expression)
줄여서 regex, regexp로 패턴검색기법이다.
-
(): 캡쳐
-
[]: 이 중 아무거나
-
.: 아무거나
-
*: 0개 이상
-
+: 1개 이상
-
?: 없을수도
-
\: 위 특수 기호 무효화
ex) A, B, C, F
print(re.findall(r'이 영화는 (.)등급 입니다.', s))
-> A
print(re.match(r'이 영화는 [A,B,C,D]등급 입니다.', s))
정규식의 이용
우리는 한꺼번에 가져오기 위해 공통점을 파악해야만 한다. 즉 미국환율과 일본환율이 게시되는 원리를 깨달아야 하는데

r = re.compile(r'"h_lst.?blind\">(.?).?value\">(.?)', re.DOTALL)
captures = r.findall(body)
print(captures)
미국통화
이런식으로 공통적인 글자가 포함되어 있지만 "h_lst.?blind\">(.?) 같이 표현될 수 있음을 알 수 있다. " 앞에는 \이 와주고 공통적인 html 문법 앞에는 .*를 입력한다. 그리고 .이 줄바꿈까지 포함할 수 있도록 re.DOTALL을 추가해준다.
환율
이것도 똑같이 입력하면

다음과 같이 만들어지는 것을 확인할 수 있다.
쿼리스트링
url의 뒤에 입력데이터를 함께 제공하는 가장 단순한 데이터 전달 방법, 웹개발에서 데이터를 요청하는 방식 중 대표적인 것이 GET과 POST인데, 주로 GET 방식을 이용한다.
?로 url과 구분한다.
&로 값들이 구분된다.
requests: http 통신을 편하게
beautifulsoup: html 통신을 편하게
beautifulsoup
-
html 문자열 파싱
-
html 노드 인식 및 편리한 기능들
-
prarent, children, contents, descendants, sibling
-
string, strings, stripped_strings, get_text()
-
prettify
-
html attribute
bs4를 불러와서 "html.parser"를 통해 불러올 수 있다. 그리고 문법을 제외하고 입력하여 원하는 정보를 불러올 수 있다.
from bs4 import BeautifulSoup as BS
soup = BS(res.text, "html.parser")
print(soup.title)
스트링을 추가해서 NAVER 마 불러올 수도 있다.
print(soup.title)
soup = BS(res.text, "html.parser")
tds = soup.find_all("td")
a_s = soup.find_all("a")
print(a_s)
names = []
for td in tds:
if len(td.find_all("a")) ==0:
continue
names.append(td.get_text(strip=True))
prices =[]
for td in tds:
if "class" in td.attrs:
if "sale" in td.attrs["class"]:
prices.append(td.get_text(strip=True))
css
html이 구조 잡은 곳에 스타일링을 하는데 스타일링에 스타일 이름을 붙힌다.
스타일 이름이 없는 구조에도 스타일링을 함(css selector)
구조는 스타일 이름으로 특정지어질 수 있음
프로그래머가 웹을 만들 때, CSS Selector를 직접 활용해서 이름붙여 만든다.
