다층 퍼셉트론
다수의 퍼셉트론 계층들을 순서에 따라 배치하여 중간단계의 은닉층부터 출력층을 거쳐 출력벡터를 산출한다.
은닉계층 : 직접 드러나지 않는 계층이며 이를 통한 출력물을 '은닉벡터'라고 한다.
한계층의 파라미터 수 = (입력수) * 퍼셉트론의 수 + 편향의 수
은닉계층의 수나 폭이 너무 많다고 품질이 높아지면 더 많은 학습 데이터가 필요하기 때문에 무조건 좋은것은 아니다.
은닉층 설정은 문제의 규모, 데이터의 양, 난이도 등을 고려해야한다.
다층 퍼셉트론의 결과값은 입력의 일차함수로 나타나게 되어있다. 이를 다차원으로 출력하기 위해서는 중간 계층인 은닉층에서 비선형 활성화 함수를 이용하여 연산결과를 변형시키면 된다.
ReLU 함수
음수의 값을 입력하면 0을 출력하고, 양수의 값은 기울기가 1인 함수값을 출력한다.
LSTM
RNN : 순환 신경망을 말하며, 이는 중간층 중에서 이전 층에서 출력된 결과를 누적하여 입력값으로 사용하는 신경망이다.
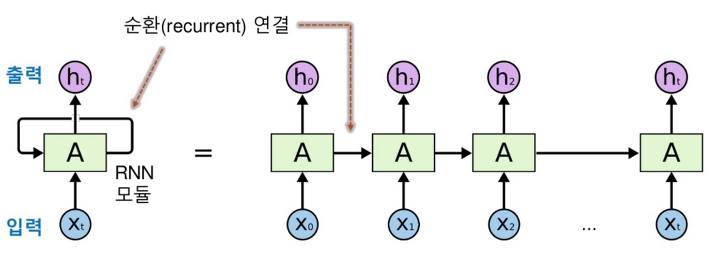
자연어 처리는 단어 하나가 아니라 문장을 사용하기 때문에 순환 신경망을 사용하여 그 단어 하나의 의미를 정확하게 예측한다.
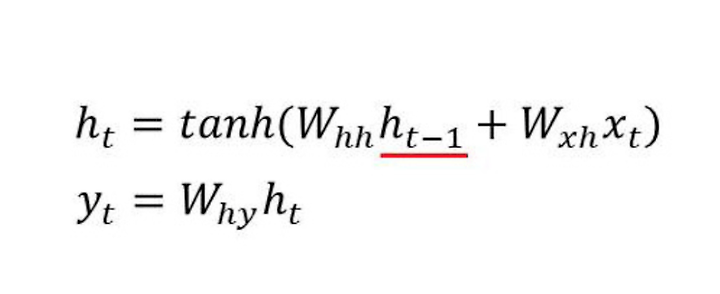
한 계층의 출력 값 = y
은닉상태 즉, 다음 시점으로 넘겨줄 값 = h
값은 위의 식과 같이 계산한다. 하이퍼탄젠트를 이용하여 -1과 1사이의 값으로 바꿔서 출력해준다.
하지만 중간계층이 너무 커지게 되면, 오래전 중간층에 대한 정보가 삭제되게 된다. 이를 해결하기 위한 방법으로 장기기억, 단기기억을 위한 은닉상태를 따로 가지는 LSTM이 나왔다.
LSTM : 은닉상태 중 장기적으로 사용해야하는 정보를 따로 저장해놓음으로써, 정보삭제를 막는 방법이다.
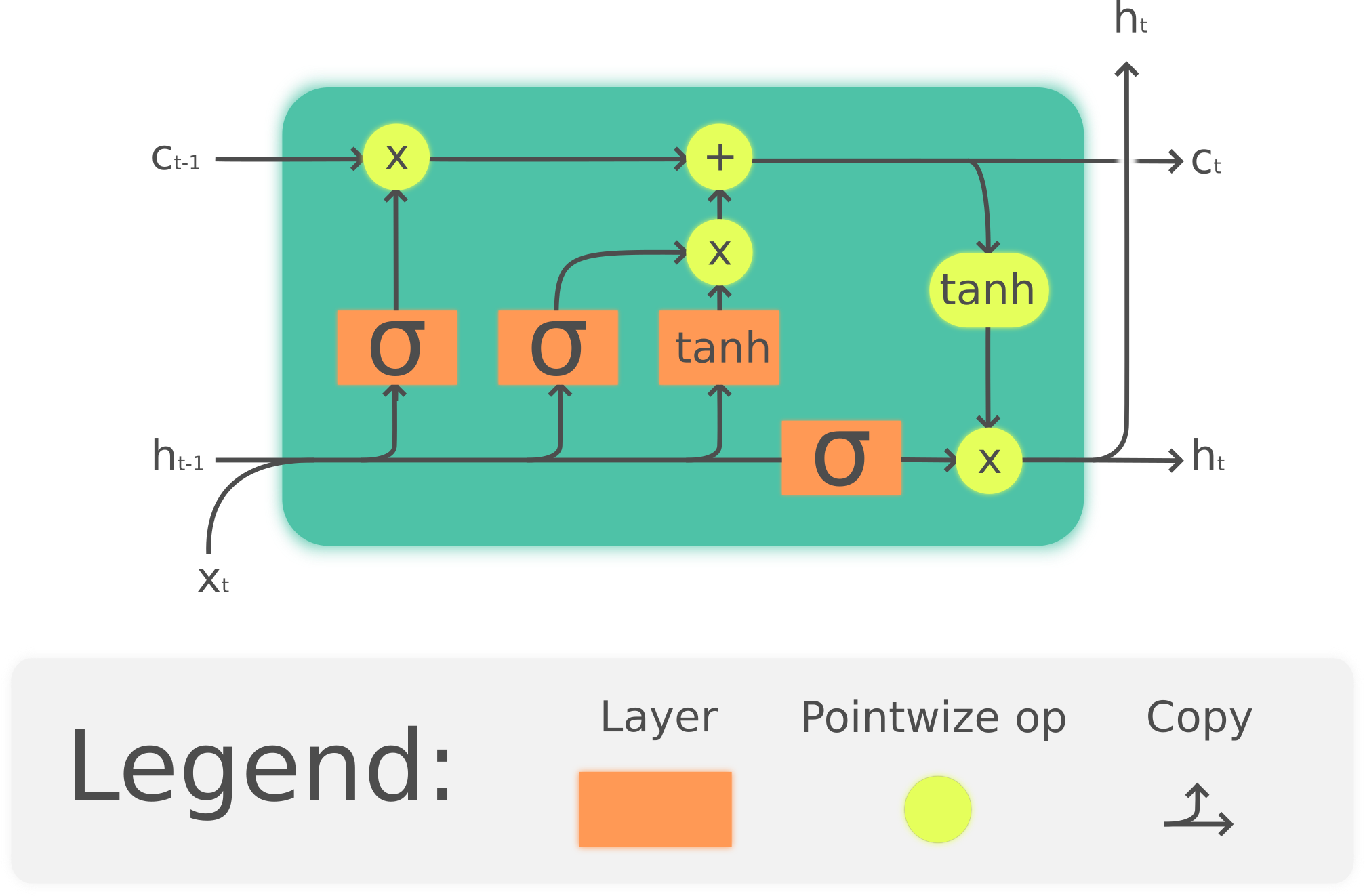
총 4개의 게이톨 이루어져있으며, layer의 시그모이드를 이용하여 확률값으로 바꿔준다. 이를 통해 은닉상태가 어느정도 적용되는지를 결정한다.
Logistic Regression
회귀라고 써있지만, 분류방법이다.
파라미터 수가 적으며, 빠르게 예측이 가능하다. 직선이 아닌 s자 곡선을 사용하여 0과 1사이의 값을 출력하여 분류를 진행한다.
model = LogisticRegression()
model.fit(X.reshape(-1, 1), y)다른 모델과 마찬가지로 모델을 선언하고, 데이터를 입력하여 fit()함수를 통해 모델을 학습한다. 이때, 입력데이터의 값은 2차원 데이터여야한다.
가중치 값과 편향값을 조정하면 다음과 같이 그래프가 이동하는 것을 알수 있다.
느낀점
- 이번주 초는 이런저런 일이 생겨서 정신이 없는 시간들이었다. 하루만에 광주도 다녀오고...
- 내가 생각한 머신러닝, 딥러닝보다 생각보다 간단한 코드로 돌아가는게 신기하다
