정규화 기법(2)
Drop out
뉴런의 연결을 임의로 삭제하여 일부의 퍼셉트론을 학습과정에서 계산하지 않는 방법
과적합 방지를 위한 방법이며, 하나의 신경망을 여러개의 작은 신경망으로 나눠서 계산하다보니 계산량을 오히려 늘어난다.
학습시점에서만 사용하며 테스트 과정에서는 모든 퍼셉트론을 계산한다. 이 방법은 과적합 현상이 줄어들지만 학습속도를 떨어뜨리는 단점이 있다.
Batch normalization
각 층의 활성화 함수의 출력값이 정규분포를 이루도록 하는 방법
대상 값들에 동일한 선형 변환을 가해주어 평균이 0, 표준편차가 1인 분포로 만들어주는 방법이다.
주로 Fully connected, Convolutional layer바로 다음에서 정규화를 진행한다.
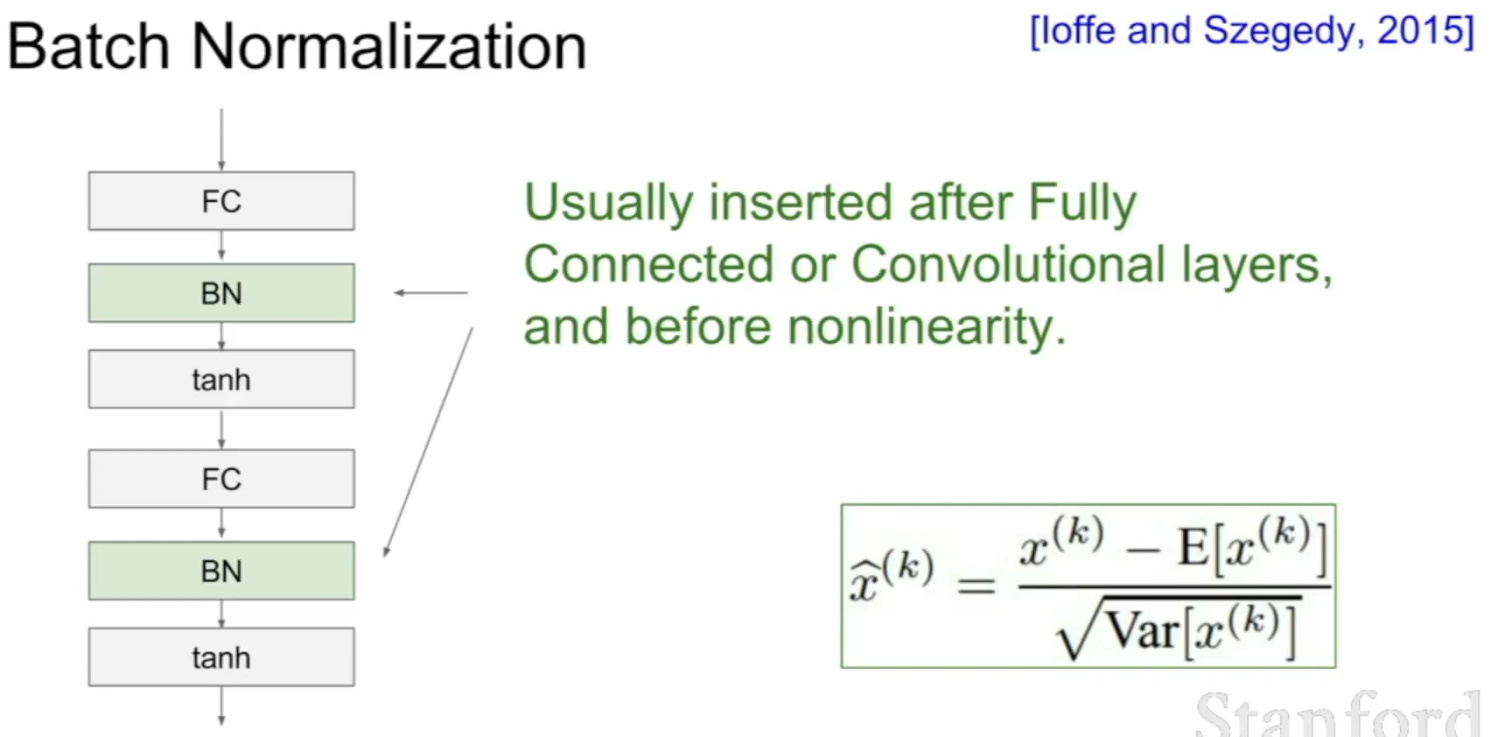
출처 : https://forums.fast.ai/t/lesson-2-using-batch-normalization-after-non-linearity-or-before-non-linearity/4817
미니배치의 데이터를 정규화 대상으로 정해서 매번 달라지는 미니배치의 평균과 분산을 이용하여 노이즈 효과를 발생시킨다.
CNN (자연어 처리)
model = Sequential()
model.add(Embedding(5000, 256))모델을 생성하고 단어를 임베딩해준다. 5000이라는 숫자는 단어의 개수를 뜻하며 이는 유의미한 단어의 개수로 정한다.
256은 워드임베딩의 차원을 뜻하며 데이터의 수, 복잡도 등을 통해 결정한다.
model.add(Conv1D(256, 4, padding='valid', activation='relu'))
model.add(GlobalMaxPooling1D())CNN의 은닉층은 convlution layer와 pooling layer들의 연속이므로 두 층을 생성해준다.
입력층의 갯수 만큼 커널을 생성해주고, 그 커널의 크기를 4로 정해주었다. 커널의 크기는 몇개의 데이터 당 하나의 출력을 낼지 결정하는 것으로 커널의 약수로 정해준다.
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))다차원의 데이터를 1차원의 데이터로 flatten해준다.
dense 벡터로 바꿔서 이중 분류를 위한 활성화 함수를 거쳐 출력을 한다.
분할 정복법
그냥을 해결 못하는 문제를 분할하여 해결한 후 해결한 결과를 하나로 모아서 최종 결과를 내는 방법이다. 재귀를 주로 사용한다.
Divide -> Conquer -> Combine
느낀점
- 이번주 내내 수업이 너무 듣기가 싫다. 번아웃이 온거 같은 느낌이다...
- 어떻게 공부를 해야할까? 사람들이랑 같이 하자니 너무 시간이 아까운거 같기도 하다. 토이프로젝트를 진행하자니 아는게 너무 없다
- 이번주의 반이 지났지만 이번주에 공부한게 없는거 같아 뭔가 불안하다
매일 불안과 힘듦의 연속인거 같다
