6-1. 파이썬 어디까지 써 봤니?!
파이썬의 성능과 한계
이 세상에 다양한 언어들이 존재하고 그 언어를 이용하여 각국의 사람들과 소통할 수 있는 것처럼, 다양한 프로그래밍 언어들을 이용해서 컴퓨터와 대화할 수 있습니다. 컴퓨터에게 명령을 내리고 결과를 받아 볼 수 있는 것이죠
C, C++, C#, JAVA, PHP, JavaScript, Python, Ruby, Objective-C, Perl 등 용도에 따라 수많은 언어가 있지만 우리는 여기서 파이썬(Python) 을 다뤄보고자 합니다.
우리는 왜 파이썬을 배워야 할까요?
파이썬에 대해 더 깊이 들어가기에 앞서 '왜 파이썬인지' 한번 알아보도록 하겠습니다.
퍼포먼스 vs 생산성
프로그래밍 언어에서 가장 중요하게 고려돼야 할 것을 꼽으면 바로 '퍼포먼스'와 '생산성' 입니다.
1. 퍼포먼스
먼저 퍼포먼스(성능) 란 어떤 언어든 코드를 짜서 실행을 시켰을 때 얼마나 빨리 처리가 되는가를 말합니다.
자전거와 자동차를 이용해 좀 더 자세히 설명해 보겠습니다. 자전거는 사람이 엔진이 되어 움직이는 이동 수단입니다. 그리고 자동차는 기계가 엔진으로 있는 성능이 매우 좋은 이동 수단입니다. 성능이 좋고 나쁘고는 이동수단이 얼마나 빨리 움직이는지에 따라 정해집니다. 자전거를 타고 가는 것보다는 자동차를 타고 움직이는 것이 훨씬 빠르겠죠?
언어도 똑같습니다. 퍼포먼스가 좋은 언어는 특정한 연산을 빠르게 수행하고 퍼포먼스가 안 좋은 언어는 연산이 느리게 수행되게 되죠.
아래는 언어별 특정 연산에 대한 수행 속도 결과입니다.
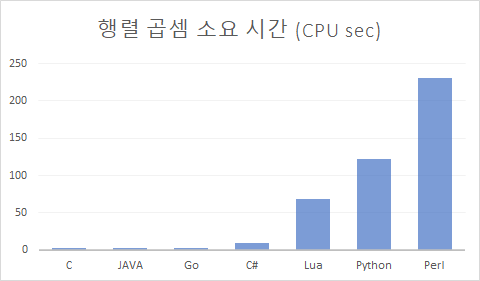
위를 보시면 C 언어가 퍼포먼스 상위를 차지하고 있고 파이썬은 상대적으로 하위에 위치에 있는 것을 보실 수 있습니다.
2. 생산성
그렇다면 생산성은 무엇을 의미할까요?
답은 시간에 있습니다. 시간은 항상 우리에게 충분히 주어지지 않을 때가 더 많습니다. 생산성이란 한 마디로 똑같은 기능을 하는 프로그램을 얼마나 빨리 작성할 수 있는가 입니다.
빠른 시간 안에 기능을 구현해야 할 때, 높은 생산성은 큰 의미가 있습니다.
예를 들어, 저희가 사진을 분류하는 프로그램을 만든다고 해봅시다. 같은 기능을 가진 프로그램이라도 파이썬으로는 일주일 만에 짤 수도 있지만, C++로는 한 달이 걸릴 수도 있습니다. 훨씬 많은 코드를 쳐서 만들어야 하죠.
3. 퍼포먼스 vs 생산성
C와 파이썬만 보더라도 이렇게 생산성이 올라가면 퍼포먼스가 떨어지고, 퍼포먼스가 올라가면 생산성이 떨어지는 trade-off가 상당한 걸 보실 수 있습니다. 그렇다면 생산성과 퍼포먼스 중에서는 어떤 것을 우선적으로 선택해야 할까요?
생산성과 퍼포먼스가 모두 뛰어난 언어를 선택하면 좋겠지만 사실 생산성이 좋은 언어들은 퍼포먼스가 떨어지고 퍼포먼스가 좋은 언어는 생산성이 떨어집니다. 이런 상황에서 우리는 선택을 해야 합니다.
그래서 어떤 언어를 써야 돼?
목적에 맞게, 상황에 맞게 언어를 선택하고 사용하는 방법을 배우면 됩니다.
실무에서는 먼저 회사의 각 프로그램들에서 기존에 사용하고 있는 언어를 가장 먼저 고려하고, 그다음에는 개발하고자 하는 프로젝트의 성능과 개발 기간을 고려해서 언어를 정하게 됩니다.
결국 성능도 고려하고 시간도 고려해야 한다는 말이네요. trade-off에 있는 두 가지를 잘 배합하여 상황에 따라 적절한 언어를 골라야 합니다.
파이썬의 성능
일단, 우리가 배우려는 언어는 파이썬이므로 파이썬을 배우면 좋은 이유를 좀 더 알아보겠습니다.
1. 높은 생산성

위 그림은 파이썬 터미널에서 import antigravity를 실행하면 나오는 이스터에그 이미지입니다. 파이썬의 Battery Included라는 모토에 충실하게, 파이썬은 '이런 것까지 이미 다 포함해 두었나!' 하고 놀라울 만큼 다양한 모듈을 이미 라이브러리화해서 제공하고 있습니다. 뿐만 아니라 pip를 통해 얼마든지 쉽게 설치할 수 있는 써드파티 라이브러리를 통해 개발 기간을 크게 단축시킬 수 있게 되죠.
하늘을 나는 기능조차 직접 구현하지 않고 import로 불러다 사용하면 된다는 건 우스개이긴 하지만, 파이썬을 사용하고 있다면 어떤 기능을 직접 구현하려 들기 전에 한번 검색해 보시기를 권합니다. 대부분의 기능은 이미 어떤 패키지로 만들어져 있을 가능성이 높습니다.
- 코드의 간결함
2.1. java
if(true) {
System.out.println("첫 번째");
if(true) {
System.out.println("두 번째");
}
}2.2. python
if True :
print("첫 번째")
if True :
print("두 번째")3. 빠른 개발 속도
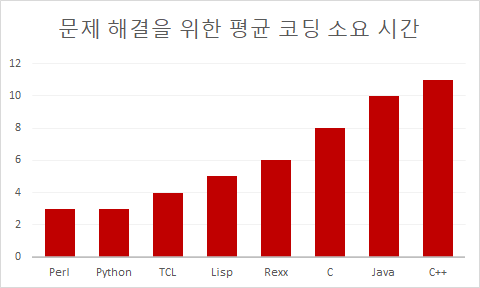
위의 표를 살펴봅시다. 같은 문제를 C++로 짜게 되면 평균 11시간 정도의 시간이 걸리고 파이썬으로 짜게 되면 약 3시간의 시간이 걸리는 걸 확인할 수 있습니다. 따라서 성능과 상관없이 개발이 빨리 돼야 하는 프로젝트를 하시게 된다면 파이썬을 사용하시면 좋습니다.
4. 스크립트 언어(인터프리터 언어)
스크립트 언어는 인터프리터 언어라고 불리기도 합니다. Python과 같은 스크립트 언어는 컴파일 언어에는 없는 강력한 장점을 가지고 있기 때문에 유용합니다. 아래 컴파일 언어와 스크립트 언어의 비교를 통해 이해해 봅시다.
컴파일 언어
- 실행 전 소스 코드를 컴파일하여 기계어로 변환 후 해당 파일을 실행
- 이미 기계어로 변환된 것을 실행하므로 비교적 빠름
- 컴파일 시점에 소스 코드의 오류를 잡기 쉬움
- 같은 소스 코드도 다른 환경(PC, mobile 등)에서 실행하려면 다시 컴파일(기계어로 변환) 해야함
스크립트 언어(인터프리터 언어)
- 코드를 작성함과 동시에 인터프리터가 기계어로 번역하고 실행함
- 코드 번역 과정이 있어 비교적 느림
- 주 사용 목적이 뚜렷하게 개발되어 사용하기 쉬운 편
- 명령줄로 코드를 즉시 실행할 수 있음
컴파일 언어와 스크립트 언어에 대한 자세한 설명은 아래를 참고하세요. 다만 그 내용이 매우 어렵고 컴퓨터 발전에 따라 변화가 크기 때문에 너무 깊이 빠져들지 않도록 조심하세요.
- Interpreter (computing)
이제 왜 파이썬을 배우면 좋은지 감이 오시나요?
높은 생산성과, 간결한 코드, 빠른 개발 속도, 스크립트 언어의 장점을 두루 갖춘 파이썬! 다음 스텝에서는 파이썬을 더욱 파이썬답게 잘 사용하는 방법을 알아보도록 하겠습니다.
6-2. 파이썬을 더 잘 사용해보자!
(1) for문 잘 사용하기
이번 스텝에서는 while보다 훨씬 많이 쓰이는 반복문인 for문을 더욱 효과적으로 쓰는 방법을 알아보도록 하겠습니다.
enumerate(), 이중for문, list Comprehension, Generator 총 4가지 개념이 소개됩니다.
for문 잘 써보기 - enumerate()와 이중 for문
for문을 잘 쓰면 반복적으로 코드를 쓰지 않아도 돼 간결한 코드를 만드는 데 큰 도움이 됩니다.
아래와 같이 my_list에 있는 값들을 하나씩 출력하는 코드를 보겠습니다. 일단 먼저 돌려보시죠!
my_list = ['a','b','c','d']
for i in my_list:
print("값 : ", i)>> 값 : a
값 : b
값 : c
값 : d출력 결과가 어떻습니까? 값이 쭉 출력되었죠? 그럼 print 되는 각각의 값이 몇 번째로 출력되어 나왔는지는 어떻게 확인할까요? 물론 위의 예제는 4개의 값밖에 안 되어 바로 몇 번째인지 한눈에 확인이 가능하나, 100개 정도의 값을 출력한다고 했을 때는 '50번째에 출력된 값이 무엇인가?'라고 물으면 대답하기가 어려워질 것 같습니다.
확인하는 방법은 enumerate()라는 기능을 이용하는 것입니다. enumerate()는 리스트, 문자열, 튜플 등이 있는 경우 순서와 리스트의 값을 함께 반환해 주는 기능입니다. 그럼 아래 코드를 통해 확인해 보겠습니다.
my_list = ['a','b','c','d']
for i, value in enumerate(my_list):
print("순번 : ", i, " , 값 : ", value)>> 순번 : 0 , 값 : a
순번 : 1 , 값 : b
순번 : 2 , 값 : c
순번 : 3 , 값 : dfor i, value in enumerate(my_list)를 이용하면 i에 순번이, value에 해당 순번의 데이터 값이 나오게 됩니다. 즉, enumerate()를 통해 단순 for문이 아니라 순서에 대한 결괏값도 함께 추가되었다고 생각하시면 됩니다.
자 이번엔 이중 for문에 대해서 알아보겠습니다. for 안에 또 for를 쓴 것을 이중 for문이라고 합니다.
눈치 빠르신 분들은 삼중 사중 for문도 있지 않을까 하실 텐데 맞습니다! for문의 개수에 따라서 몇 중의 for문이고 생성할 수 있습니다. 사실은 삼중 for문 이상이고 데이터가 많아지면 매우 느리게 동작하기 때문에 이중 for문까지만 쓰는 경우가 많습니다. 물론 필요한 경우는 그 이상도 사용할 수는 있습니다만 효율적인 코드는 아닐 수 있습니다.
설명이 길어졌는데 바로 이중 for문을 돌려보겠습니다.
my_list = ['a','b','c','d']
result_list = []
for i in range(2):
for j in my_list:
result_list.append((i, j))
print(result_list)>> [(0, 'a'), (0, 'b'), (0, 'c'), (0, 'd'), (1, 'a'), (1, 'b'), (1, 'c'), (1, 'd')]결과를 보시면 i에 대한 값은 0,0,0,0,1,1,1,1 이런 순서로 나오고 j에 대한 값은 a,b,c,d,a,b,c,d 순으로 나오는 것을 확인할 수 있을 것입니다. 즉, i안에 j가 있기 때문에 j가 다 돌 때까지 i는 0에서 고정되고 j가 순서대로 a,b,c,d로 나오게 됩니다. j가 전체 다 돌면 i는 다음으로 넘어갑니다. 이런 방식으로 [0, 1]과 ['a','b','c','d'] 두 리스트를 조합해서 만든 새로운 리스트를 얻게 됩니다.
참고 - range()
range(start, stop, step):range(2)와 같이 정수가 들어가야 하며, list() 함수를 통해 값을 뽑아오면 0부터 시작해서 2개인list([0, 1])를 만듭니다. 즉, stop 까지 포함하지는 않습니다. range(1, 10, 2) 이라면 1부터 9까지 2씩 증가하는[1, 3, 5, 7, 9]를 만듭니다. 하지만 실제로 반환하는 타입은 range이며, 리스트로 받아오고 싶다면list(range(1, 10, 2))를 하시면 됩니다.
리스트 컴프리헨션(list Comprehension)
파이썬이 제공하는 편리한 기능 중에 리스트 컴프리헨션이 있습니다. 이것은 리스트 등 순회형 컨테이너 객체로부터 이를 가공한 새로운 리스트를 생성하는 아주 간결하고 편리한 방법입니다. 파이썬이 가진 가장 큰 매력적인 특징 중 하나입니다. 컴프리헨션 기능은 비단 리스트뿐 아니라 셋(Set), 딕셔너리(Dict)에 대해서도 적용 가능합니다. 아래 코드를 살펴봅시다.
my_list = ['a','b','c','d']
result_list = [(i, j) for i in range(2) for j in my_list]
print(result_list)>> [(0, 'a'), (0, 'b'), (0, 'c'), (0, 'd'), (1, 'a'), (1, 'b'), (1, 'c'), (1, 'd')]위에서 이중 for문으로 구현했던 내용과 완전히 동일한 기능을 리스트 컴프리헨션을 이용하여 1줄로 구현해 보았습니다. 앞으로도 컴프리헨션을 적용한 코드 사례를 자주 접하게 될 것입니다.
제너레이터(Generator)
머신러닝을 하면 매우 많은 데이터를 다루게 됩니다. 데이터는 1건만 존재하는 법은 없기 때문에 우리는 데이터를 처리하는 반복 구조를 위해 for문을 떠올리게 될 것입니다. 위에서 살펴본 코드를 다시 한번 가져와 봅시다.
우리는 my_list에 있는 데이터셋을 하나씩 가져와서 공급해 주는 제너레이터를 만들 것입니다. my_list를 총 2번 반복하여 8개의 데이터를 공급할 계획이죠
단순히 for문을 사용해서 데이터를 공급해 보도록 하는 첫 번째 코드와, Generator의 개념을 이용하여 데이터를 공급하는 두 번째 코드를 비교해 봅시다.
my_list = ['a','b','c','d']
# 인자로 받은 리스트를 가공해서 만든 데이터셋 리스트를 리턴하는 함수
def get_dataset_list(my_list):
result_list = []
for i in range(2):
for j in my_list:
result_list.append((i, j))
print('>> {} data loaded..'.format(len(result_list)))
return result_list
for X, y in get_dataset_list(my_list):
print(X, y)>> 8 data loaded..
0 a
0 b
0 c
0 d
1 a
1 b
1 c
1 d첫 번째 코드의 문제가 뭘까요? 이중 for 문이 다 돌아가는 걸 기다린 후, 반환된 result_list 값에 대해 또 for 문을 돌려야 한다는 것입니다. 뭔가 중복되는 느낌도 들고, 확실히 느리겠죠? 지금은 my_list 에 데이터 4개밖에 없지만 만약 1억 개가 담겨 있다면 또 어떤 문제가 있을까요? 바로, get_dataset_list(my_list) 를 위해 엄청난 양의 데이터를 전부 메모리에 올려놔야 한다는 것입니다.
import sys
my_list = ['a','b','c','d']
# 인자로 받은 리스트로부터 데이터를 하나씩 가져오는 제너레이터를 리턴하는 함수
def get_dataset_generator(my_list):
for i in range(2):
for j in my_list:
yield (i, j) # 이 줄이 이전의 append 코드를 대체했습니다
print('>> 1 data loaded..')
dataset_generator = get_dataset_generator(my_list)
for X, y in dataset_generator:
print(X, y)
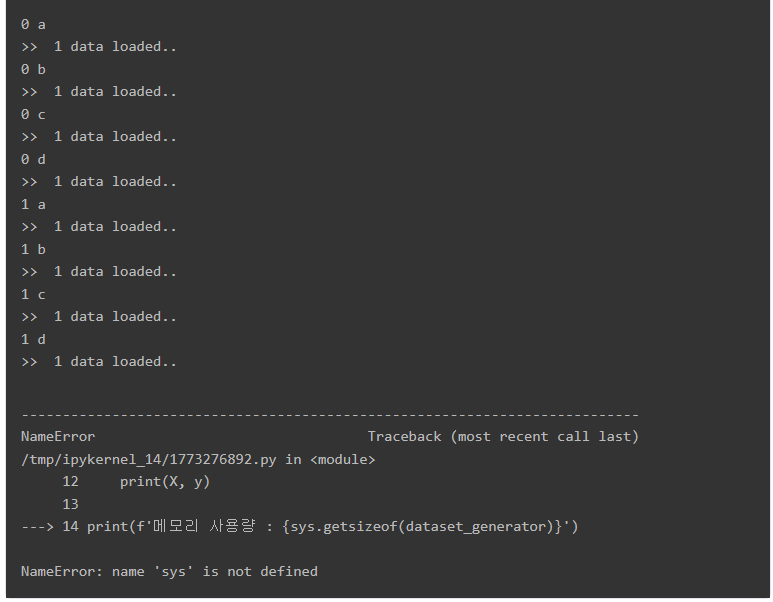
print(f'메모리 사용량 : {sys.getsizeof(dataset_generator)}')
두 번째 코드가 이 문제를 해결합니다. 8번째 줄에 yield라는 새로운 키워드가 보이네요.
영어로 "Yield"라는 단어는 "양보하다"라는 뜻을 갖고 있죠. 파이썬에서도 마찬가지로 yield는 코드 실행의 순서를 밖으로 "양보"합니다. 즉, dataset_generator = get_dataset_generator(my_list) 을 실행해도 "generator object" 만 반환할 뿐, 저희가 원하는 값을 바로 반환하고 있지 않습니다. 실질적으로 데이터를 반환하는 건 for 문에서 값을 하나씩 불러올 때죠.
위 코드 블록의 실행 결과를 보면 값을 한 번 반환 후 "1 data loaded.." 를 출력하는 걸 반복합니다.
그렇기 때문에 yield는 메모리 사용을 효율적으로 만들 수 있습니다.
실제 메모리 사용량을 확인해보면 yield를 사용한 반복문이 사용하지 않은 반복문보다 메모리 사용량이 적은걸 확인할 수 있습니다.
이처럼 제너레이터가 없다면 우리는 길이 1억짜리 리스트를 리턴 받아 메모리에 전부 올려놓고 처리를 시작해야 합니다. 그러나 제너레이터를 활용할 때는 1억 개의 데이터를 전부 메모리에 올려놓을 필요가 없이 현재 처리해야 할 데이터를 1개씩 로드해서 사용할 수 있게 됩니다. 이것은 빅데이터를 처리해야 할 머신러닝 상황에서 매우 요긴합니다.
(2) Try-Except 예외 처리
프로그램을 개발하다 보면 필연적으로 에러에 늪에 빠지게 됩니다. 에러를 잡기 위한 수많은 노력들 중 하나가 바로 Try - Except 입니다. 이것을 예외 처리를 위한 방법이라고 합니다. 여기서 예외(exception)란 코드를 실행하는 중에 발생한 에러를 뜻합니다. 즉, 예외 처리는 코드를 수행하다가 예외(에러)가 발생했을 때 그 예외(에러)를 무시하게 하거나 예외(에러) 대신 적절한 처리를 해주게 하는 등의 작업을 의미합니다. Try - Except의 작동 구조는 아래와 같습니다.
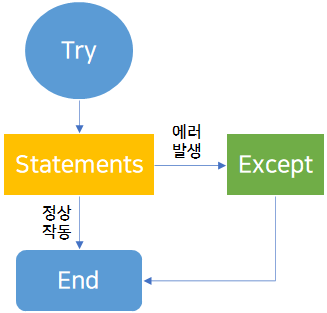
그림에서 보시는 것처럼 Try 이하의 코드가 먼저 실행됩니다. Try 안에 있는 Statements(코드)를 수행하게 되고 만약 이 코드상에서 어떠한 이유로 인해 에러가 발생하면 Except 안에 있는 코드가 바로 실행되게 됩니다.
반대로 Try 안에 있는 Statements에서 에러가 발생하지 않았다면 해당 코드가 정상적으로 작동되었기 때문에 성공! 즉, 저희가 따로 추가적인 작업을 할 필요가 없습니다 (에러를 파악하여 Statements를 재작업하는 등의 행위를 할 필요가 없음). 이제 실제 코드를 통해 Try - Except가 어떻게 작동하는지 보여드리겠습니다.
아래 코드를 돌려보겠습니다.
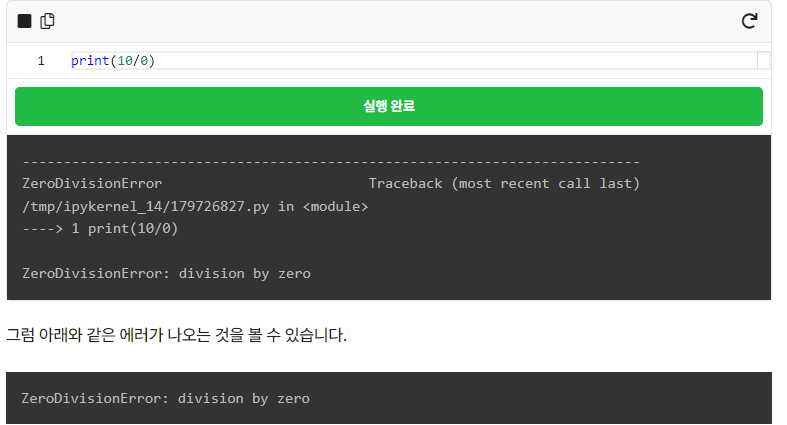
여러분들도 아시다시피 0으로는 어떠한 값도 나눌 수 없습니다. 파이썬 언어 내에서도 0으로 나누면 안 된다는 것이 자명하므로 해당 에러문으로 출력됩니다.
그럼 이 에러를 회피하고 싶다면 어떻게 해야 할까요? 물론 아예 처음부터 저렇게 0으로 나누는 경우를 만들지 않으면 됩니다. 😀
하지만 실제 데이터 분석이나 프로그래밍을 하다 보면 자주 저런 경우가 발생합니다. 우리가 모든 데이터 목록이 어떻게 생겼는지 미처 확인을 못 했을 수도 있고, 또 데이터를 내 입맛에 맞게 처리를 하다 보면 예상치 못하게 0이 생성될 수도 있습니다. 데이터 자체를 하나하나 확인하고 코드를 실행하기 어려울 수 있으니 예외 처리 구문을 통해 이 문제를 해결해야 합니다.
에러가 발생했을 때 위의 에러 메시지를 출력되는 대신 에러가 발생했다는 문구가 출력되도록 해보겠습니다. 즉, '에러가 발생했습니다.' 라고 뜨게 해보겠습니다.
a = 10
b = 0
try:
#실행 코드
print(a/b)
except:
#에러가 발생했을 때 처리하는 코드
print('에러가 발생했습니다.')>> 에러가 발생했습니다.a = 10
b = 1
try:
#실행 코드
print(a/b)
except:
#에러가 발생했을 때 처리하는 코드
print('에러가 발생했습니다.')10.0try 내부의 코드가 정상적으로 실행이 되었으므로 except 내부는 실행되지 않고 try 내부의 결과가 출력된 것을 확인할 수 있습니다.
except에서 에러가 발생했다는 것만 단순히 알려주고 끝내는 것이 아니라, 에러가 발생했을 경우 알아서 '에러가 발생하지 않을 값'으로 바꿔서 결과를 출력하고 싶다면 어떻게 해야 할까요? 아래 코드를 한번 보시죠.
a = 10
b = 0
try:
#실행 코드
print(a/b)
except:
print('에러가 발생했습니다.')
#에러가 발생했을 때 처리하는 코드
b = b+1
print("값 수정 : ", a/b)>> 에러가 발생했습니다.
값 수정 : 10.0이렇게 하면 except 내부에서 b의 값을 수정하도록 한 줄을 추가하였고 수정된 값이 정상적으로 출력되게 만들었습니다.
(3) Multiprocessing
이번 스텝에서는 코드의 실행 시간을 측정하는 방법을 간단히 알아보고, Multiprocessing에 대해서 자세히 알아보겠습니다.
실행 시간 측정
특정 프로그램을 짜다 보면 내가 짠 코드의 성능을 측정하고 싶을 때가 종종 있습니다. 내가 짠 코드를 실행시킬 때 얼마나 시간이 소요되는지 아래의 코드를 통해 확인해 보겠습니다.
import time
start = time.time() # 시작 시간 저장
a = 1
for i in range(100):
a += 1
# 작업 코드
print("time :", time.time() - start) # 결과는 '초' 단위 입니다.>> time : 0.00012683868408203125Multiprocessing(멀티프로세싱)
Multiprocessing(멀티프로세싱) 은 컴퓨터가 작업을 처리하는 속도를 높여주는 방법 중 하나입니다. 그렇다고 멀티프로세싱을 이용하면 갑자기 자전거가 자동차의 속도로 빨리 가게 되지는 않습니다. 비유하자면 하나의 자전거를 이용해 여러 명이 한 명씩 순차적으로 목적지까지 가다가, 여러 자전거를 이용해서 여러 명이 동시에 목적지까지 가게 되는 것입니다.

아래의 이미지를 보면 parallel processing, serial processing이 있습니다. parallel processing은 병렬 처리로, serial processing은 순차 처리로 번역이 가능합니다. 우리가 지금까지 짠 코드는 순차 처리의 방식이었습니다. 즉, 4개의 자전거를 가용할 수 있으나 그중 1개의 자전거만 사용하고 있는 것과 같습니다. 그럼 어떻게 하면 놀고 있는 나머지 3개 자전거도 함께 사용할 수 있는지 알아보겠습니다.
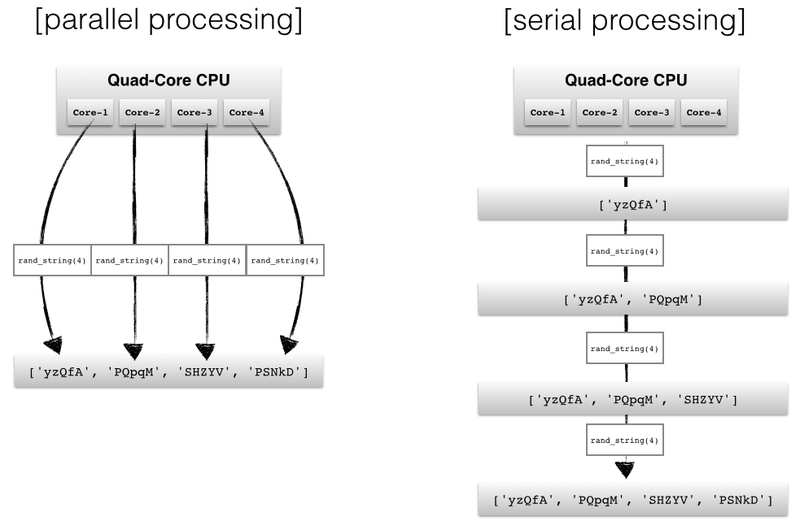
왼쪽 그림을 보시면 병렬 처리는 4개의 문자열이 동시에 처리가 되어 저장되는 것을 볼 수 있고, 순차 처리는 문자열이 하나씩 차례대로 처리되어 저장되는 것을 볼 수 있습니다.
먼저 순차 처리의 예제를 밑에 코드로 확인해 보겠습니다. 변수를 1억 번 돌려보는 코드입니다.
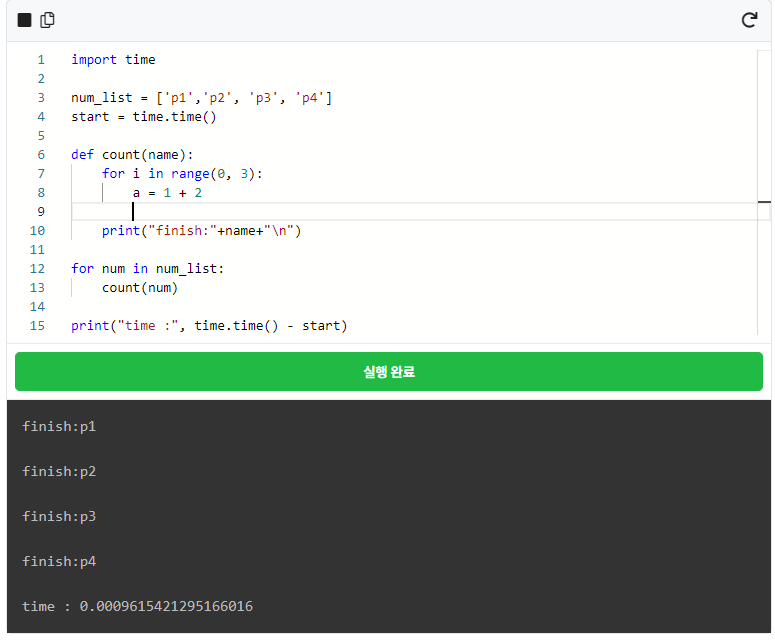
finish로 나오는 문자는 p1, p2, p3, p4의 순서로, 원래의 리스트['p1', 'p2', 'p3', 'p4']의 순서가 동일합니다. 그리고 아래에 출력된, 총 걸린 시간을 기억해 주세요!
다음은 병렬 처리를 이용한 코드입니다. 먼저 실행해 보겠습니다.
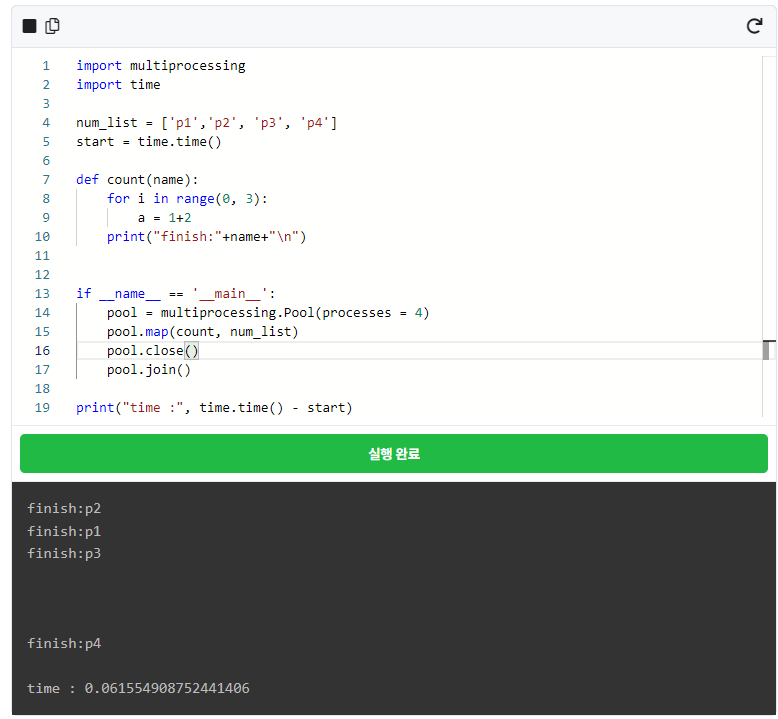
우와, 속도 보이십니까? time이 순차 처리 보다 병렬 처리를 시행했을 때 2배 이상 빨라진 것을 볼 수 있으실 겁니다. 그런데 병렬 처리의 경우, finish의 순서가 순차 처리의 코드와 다를 것입니다. 제가 돌렸을 때는 p2, p1, p3, p4 순서대로 종료되었다고 나왔습니다. 여러분들의 결과는 저랑 같을 수도 있고 다를 수도 있습니다.
그 이유는 각 프로세스에 작업 코드가 거의 동시에 들어가서 각자 처리 후 결과가 나오기 때문입니다. 처리되어 나오는 결과는 각 코어의 점유 상황이나 여러 이유로 인해 시간차가 생깁니다.
그럼 병렬 처리를 사용하는 방법에 대해 좀 더 자세히 알아보겠습니다. 일단, multiprocessing모듈을 import합니다. 그리고 병렬 처리를 하고 싶은 함수를 작성합니다. 그 아래에 count(name) 함수를 만들어보겠습니다.
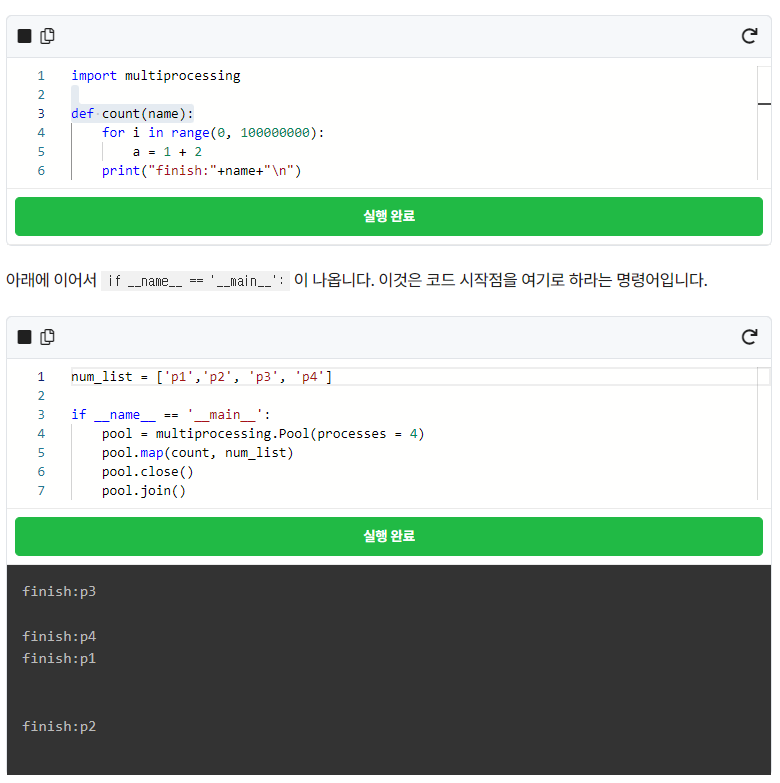
한 줄씩 자세히 설명하자면,
-
pool = multiprocessing.Pool(processes = 2) : 병렬 처리 시, 2개의 프로세스를 사용하도록 합니다. CPU 코어의 개수만큼 입력해 주면 최대의 효과를 볼 수 있습니다. 코어의 개수는 터미널에 grep -c processor /proc/cpuinfo 명령어를 입력하여 확인할 수 있습니다. CPU에 대한 자세한 정보를 알고 싶다면 터미널에 cat /proc/cpuinfo 명령어를 입력하여 확인해볼 수 있습니다.
-
pool.map(count, num_list) : 병렬화를 시키는 함수로, count 함수에 num_list의 원소들을 하나씩 넣어 놓습니다. 여기서 num_list의 원소는 4개이므로 4개의 count 함수에 각각 하나씩 원소가 들어가게 됩니다.
즉, count('p1'), count('p2'), count('p3'), count('p4')가 만들어집니다. -
pool.close() : 일반적으로 병렬화 부분이 끝나면 나옵니다. 더 이상 pool을 통해서 새로운 작업을 추가하지 않을 때 사용합니다.
-
pool.join() : 프로세스가 종료될 때까지 대기하도록 지시하는 구문으로써 병렬처리 작업이 끝날 때까지 기다리도록 합니다.
6-3. 같은 코드 두 번 짜지 말자!
(1) 함수 사용하기
프로그래밍을 하다 보면 같은 코드인데 여러 번 중복해서 입력하는 케이스가 있습니다. 만약 제가 1,000줄 정도 되는 코드를 짰는데 이 코드를 다시 한번 더 아래에 짜야 한다면 어떻게 해야 할까요? 물론 우리에겐 ctrl+c, ctrl+v 가 있습니다!
하지만 1,000줄짜리 코드를 10번 복사 붙여넣기를 한다면 무려 10,000줄짜리 코드가 탄생합니다. 그럼 코드가 눈에 들어올까요?
게다가 만약 1,000줄짜리 코드에 문제가 있는 것을 뒤늦게 발견하여 코드를 수정하려고 하면 나머지 다른 코드들도 일일이 수정하거나 10,000줄의 코드를 1,000줄씩 끊어 다시 삭제하고 붙여넣기를 반복해야 할지도 모릅니다. 그러니 복사 & 붙여넣기도 해답이 아닙니다.
그럼 어떻게 하면 이 문제를 해결할 수 있을까요? 아주 잠시 수학을 언급하겠습니다.

이렇게 적어야 하는 양이 상당히 줄어든 것을 볼 수 있습니다. 프로그래밍에서도 이런 역할을 하는 것이 함수(Function) 입니다.
y=f(x) 함수에는 어떤 것이 있죠?
- x : 입력 (정의역)
- f(x) : 수식
- y : 결과(치역)
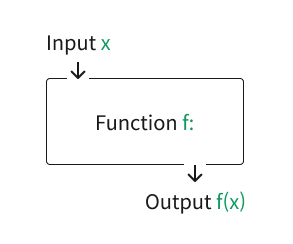
https://ko.wikipedia.org/wiki/함수
코드로는 아래와 같이 만들 수 있습니다.
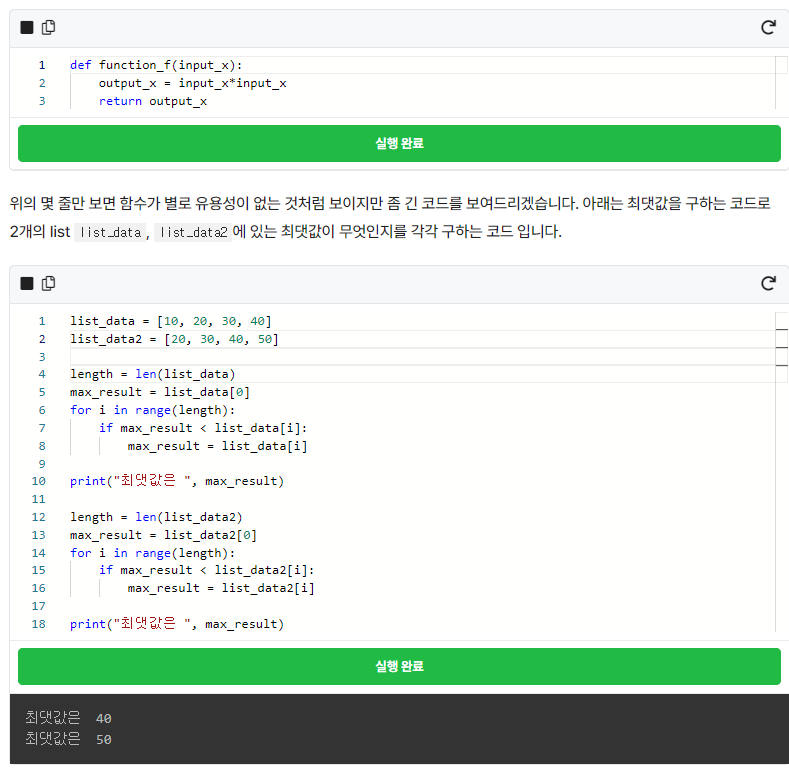
결과로 각각의 최댓값이 나오는 것을 확인할 수 있습니다. 만약 또 추가적인 최댓값을 구하는 코드를 만들려면 어떻게 해야 할까요? 그럼 한 번 더 최댓값 구하는 코드 5줄이 추가될 것입니다.
이제 함수를 이용해서 하면 얼마나 효율적인지 보겠습니다. 아래도 위와 똑같은 기능을 하는 코드입니다.
list_data = [10, 20, 30, 40]
list_data2 = [20, 30, 40, 50]
def max_function(x):
length = len(x)
max_result = x[0]
for i in range(length):
if max_result < x[i]:
max_result = x[i]
return max_result>> 최댓값은 40
최댓값은 50위의 코드와 다르게 같은 코드가 두 번 이상 나오는 경우 함수로 만들면 위에서 5줄이 추가되는 것과 다르게 1줄만 추가하면 됩니다. 이렇듯 함수를 잘 만들어 놓으면
- 코드의 효율성을 높여줄 뿐만 아니라
- 코드의 재사용성을 높여줘 개발하는 시간이 적게 걸리게 되고
- 뭘 하고자 하는지 누구나 알기 쉬워 코드의 가독성도 좋아집니다.
(2) 함수 사용 팁
pass
파이썬에서 함수를 만들기 전에 함수 이름과 입력 정도만 먼저 만들어 놓는 경우가 있습니다. '이런 이런 동작을 하는 함수를 만들 거지만 먼저 일단 이름만 작성해놓고 함수 내부 구현은 나중에 해야겠다~'라는 겁니다. 이런 상황에선 어떻게 해야 할까요? 파이썬은 즉각적인 코드 실행이 가능하기 때문에 만약 함수 안을 비워 놓은 채 이름만 써 놓는다면 에러가 날 것입니다.
한번 테스트해볼까요? 아래 코드를 실행해 보겠습니다!
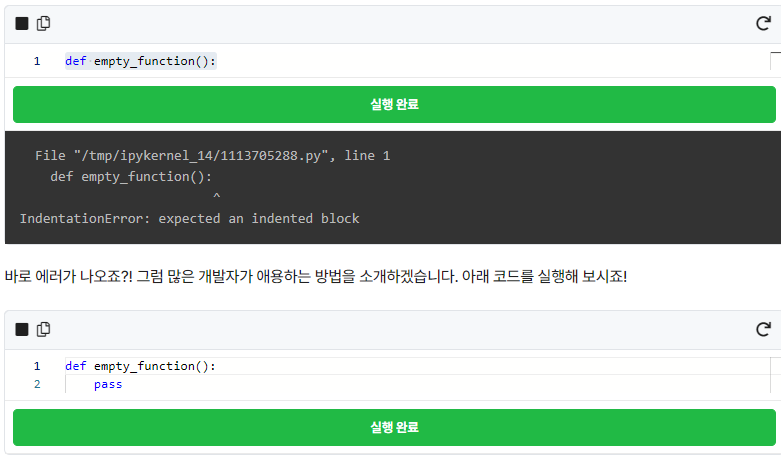
짜잔, 이제 에러가 안 납니다! 에러가 났던 코드랑 비교했을 때 뭐가 추가됐죠? pass가 추가되었습니다.
pass 문은 기타 제어 흐름 도구입니다. pass가 하는 일은.. 놀랍게도 아무것도 하지 않는 일입니다. 즉 문법적으로 해당 문장이 필요하지만, 프로그램이 특별히 할 일이 없을 때 사용할 수 있습니다. 사용 가능한 곳은 다양하며 대표적으로 위에서 사용한 함수 내부, if 내부, while 내부 등 다양한 곳에서 쓸 수 있습니다.
함수 연달아 사용
함수를 연달아 사용할 수도 있습니다. 아래 코드를 실행해 봅시다.
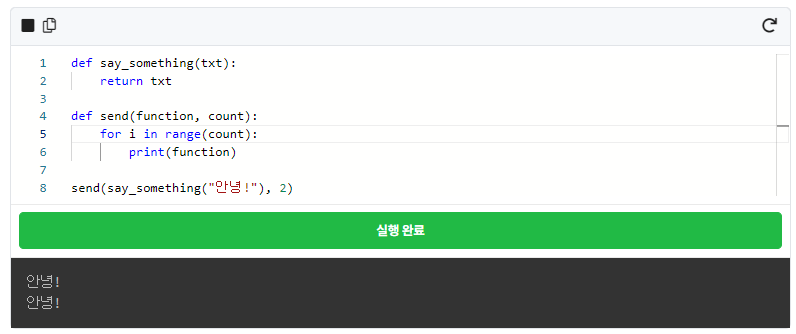
먼저 send라는 함수가 실행됩니다. send 함수는 function이라는 객체와, count라는 객체 두 가지를 입력으로 받습니다. send 함수의 첫 번째 입력값에는 say_something("안녕!")이라는 함수가 들어가고, 두 번째 입력에는 2라는 숫자가 들어갑니다.
say_something(txt) 함수는 입력값을 그대로 반환하는 코드가 짜여 있습니다. send 함수는 function을 count만큼 출력하는 함수입니다.
그럼 function에는 함수 say_something()이 들어갔으니 위의 코드는 어떤 값을 출력할까요?
여러분들은 이미 돌려봐서 결과를 알고 계시겠지만 "안녕!"이 두 번 결과 창에 나오게 될 것입니다. 즉 say_something("안녕!")이라는 함수의 반환값인 "안녕!"이 send의 print() 안에 들어갑니다.
함수 안의 함수 & 2개 이상의 return
여러분이 파이썬에서 열심히 함수를 생성하시다 보면 함수를 이용해서 return값(반환값)을 여러 개 받고 싶을 때가 있습니다. 예를 들어, 숫자들이 있는 list의 최댓값과 최솟값을 한꺼번에 출력하고 싶은데 각각 함수로 짜기에는 귀찮고 한 번에 받고 싶다고 생각해 봅시다. 어떻게 하는지 먼저 보여 드리겠습니다. 바로 아래 코드를 돌려보죠!
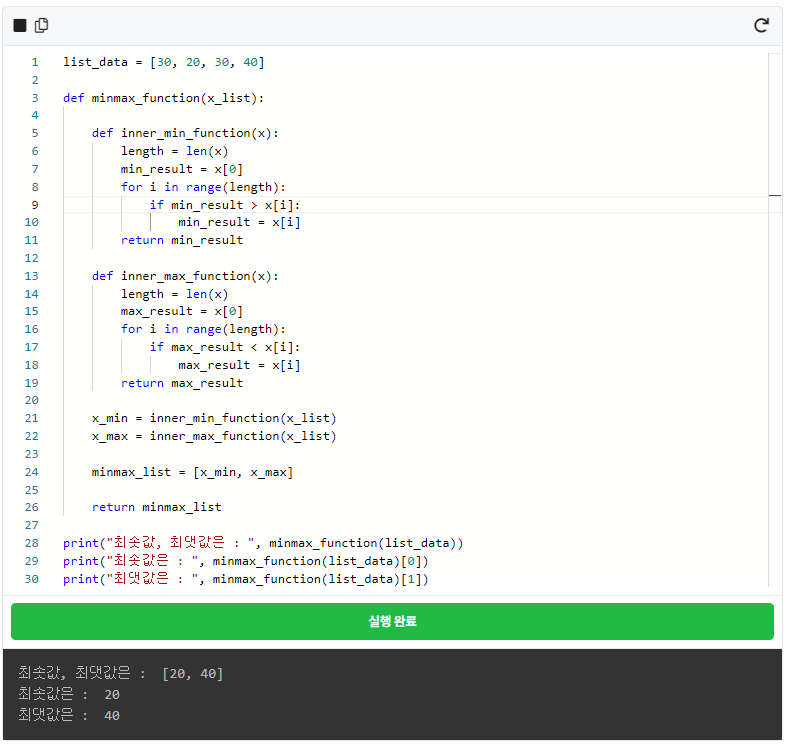
함수(def) 안에 또 함수가 그것도 2개나 들어 있는 걸 확인하셨나요? 눈썰미가 좋으시군요! 맞습니다. 함수 안에 또 함수를 만들어서 쓸 수 있습니다. 하지만 함수 안에서 만든 함수는 해당 함수 내부에서만 사용할 수 있습니다. 위의 예시에서 minmax_function(list_data) 대신 inner_max_function(list_data)로 바꿔서 값을 출력해 보겠습니다.
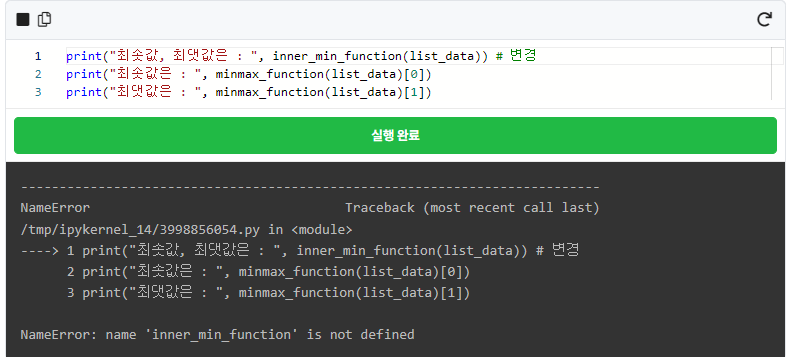
에러!가 출력됩니다. 함수 안에 함수를 만들 수는 있지만 안에 있는 함수는 가장 밖에 있는 def가 쳐놓은 울타리 안에서만 생활할 수 있는 것이죠! 그렇기 때문에 그 울타리 외부에서는 사용하지 못합니다.
다시 돌아와 minmax_function()의 반환 값을 보겠습니다. 아니, 분명 위에서 return을 이용해서 두 개 이상의 값을 반환한다고 했는데 왜 minmax_list 하나만 반환할까요?
...
x_min = inner_min_function(x_list)
x_max = inner_max_function(x_list)
minmax_list = [x_min, x_max]
return minmax_list
...return 위의 3줄을 주목해 주세요. 뭔가 속으신 것 같은 느낌이 오시면 너무나도 자연스러운 현상이랍니다. 😉 최솟값과 최댓값을 각각의 함수 안에 넣어 계산을 하고 그 결괏값을 x_min, x_max라는 변수에 넣습니다. 그리고 그 변수들을 minmax_list 라는 리스트 안에 넣었습니다. 그리고 return에 리스트를 입력하는 것이죠. 즉, return 되는 것은 minmax_list 1개이지만 그 안에 2개의 값을 넣어놨기 때문에 2개 이상을 반환하는 것과 같은 효과를 보게 되는 것입니다. 최솟값 최댓값을 각각 보고 싶다면 minmax_function(list_data)[0]처럼 인덱싱을 활용하시면 됩니다.
여러 변수로 반환하기
실제로 여러 개의 값을 여러 변수로 반환하는 방법도 있습니다. 아래 코드를 실행해 보세요.
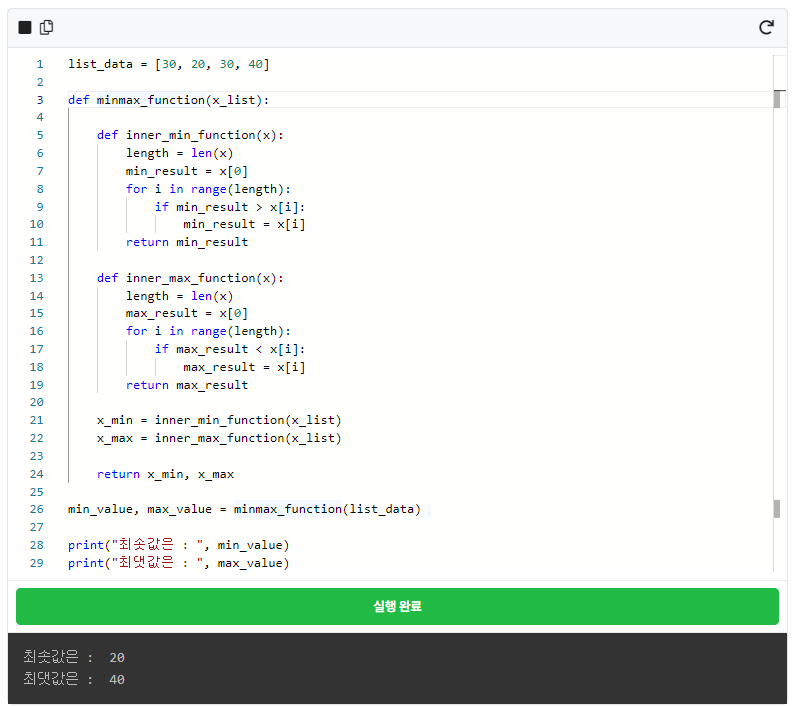
이처럼 ,(콤마)를 이용해 여러 개의 값을 반환하고, 이를 받아 각각을 활용할 수도 있습니다.
(3) 람다 표현식
람다는 런타임에 생성해서 사용할 수 있는 익명 함수입니다. 쉽게 말하자면, 함수 이름이 없는 함수라고 생각하시면 됩니다. 람다 표현식은 식 형태로 되어 있어 람다 표현식(lambda expression)이라 부릅니다. 람다를 이용한 기능들은 많이 있지만 우리가 먼저 알아볼 것은 한 줄로 된 함수입니다.
먼저 더하기를 하는 함수를 짜보겠습니다.
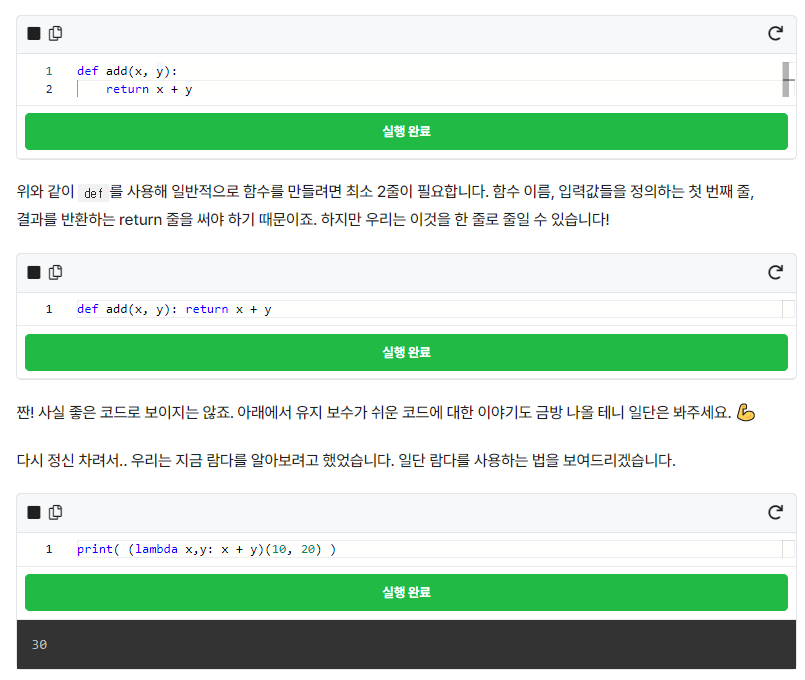
먼저 lambda라고 적혀져 있고 그 옆에 위의 add 함수와 같은 역할을 하는 코드가 적혀져 있습니다. 순서대로 살펴보겠습니다.
- 먼저 x, y 는 입력값을 의미합니다. 즉, x값과 y값이 입력으로 들어온다는 의미입니다.
- 두 번째, x + y는 return 부분과 같습니다. add 함수에도 return x + y가 있었던 것과 같이 lambda 에도 ':' 이후에 반환값으로 나오게 됩니다.
- 마지막은 (10, 20) 입니다. 각각 앞에 있던 x, y 입력값입니다. 만약 입력이 x, y, z 이라면 (10, 20, 30) 이렇게 세 개의 값을 넣게 됩니다. 보통 함수 안의 함수를 간단히 만들 때, def를 이용해 만들지 않고 람다를 이용해서 함수를 만들게 됩니다.
람다 표현식을 사용하는 가장 중요한 이유는 함수의 인수 부분을 간단히 하기 위함입니다. 이런 방식으로 사용하는 대표적인 예가 map()입니다.
람다 표현식을 사용하기 전에 먼저 def로 함수를 만들어서 map()을 사용하는 예제를 보여드리겠습니다.
map() 함수는 입력받은 자료형의 각 요소가 함수에 의해 수행된 결과를 묶어서 map iterator 객체로 출력하는 역할을 합니다. 무슨 말인지 좀 복잡하죠? 아래 예시를 보면서 이해해 보도록 하겠습니다. 먼저 코드를 돌려보겠습니다.
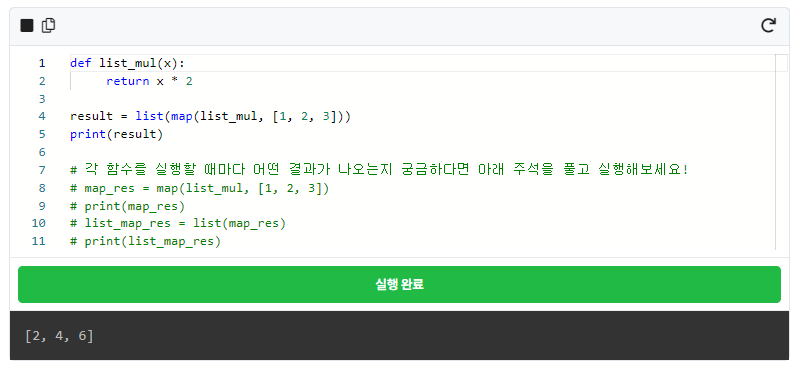
코드를 먼저 설명하면, 함수 list_mul()은 숫자를 받은 뒤 그 두 배 값을 반환하는 함수입니다. map()에 list_mul()함수와 리스트 [1, 2, 3]을 넣습니다. 주의할 점은 map()의 결과는 그냥 map 객체이므로 결과 창에서 직접 눈으로 확인할 수 있는 형태로 바꾸기 위해 list()를 사용해 리스트 형태로 변환해 준다는 것입니다.
map(f, iterable) 는 입력으로 함수 f 와 반복 가능한 iterable 객체(리스트, 튜플 등)를 받습니다. 코드에서 보시면 f에는 list_mul() 함수가 들어갔고 iterable에는 [1,2,3] 리스트가 들어가 있습니다. 코드를 수행하면 리스트에 들어가 있는 값들에 2를 곱한 결과가 나옵니다. 즉, 리스트 안의 원소들을 1(0번째) 부터 시작해서 2(1번째), 3(2번째) 순서로 list_mul() 함수에 차례로 넣고 출력을 받아서 list 형태로 바꾼 것입니다.
그럼 이 map()이 lambda와 결합을 하면 어떻게 될까요?! 아래의 코드와 같이 list_mul() 함수를 lambda로 대체하면 총 3줄이었던 코드가 1줄로 줄어드는 매직을 보게 됩니다.
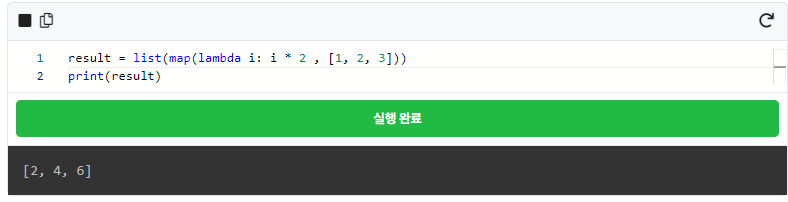
map() 이외에도 filter(), reduce() 등 람다 표현식과 자주 쓰이는 함수가 많이 있습니다. 아래 사이트를 가시면 해당 함수에 대한 추가적인 설명이 있습니다.
(4) 클래스, 모듈, 패키지
클래스(Class)
클래스는 비슷한 역할을 하는 함수들의 집합이라고 볼 수 있습니다. 예를 들어, RPG 게임을 할 때 직업을 선택하게 되는데, 각 직업에 따라서 쓸 수 있는 스킬들이 다릅니다. 전사이면 칼의 공격력을 높이거나 방패의 방어력을 높이는 등의 스킬이 있고, 마법사이면 파이어볼, 아이스 볼 등 직업의 특성을 나타내는 스킬들이 있습니다. 비슷한 특성을 가지는 스킬(함수)들을 모아 놓은 '직업'과 유사한 개념이 클래스입니다. 이번 강의에서는 간단한 개념만 한 번 이해하신다고 생각해 주세요! 👍
모듈(Module)
모듈은 함수, 변수, 클래스를 모아 놓은 파일을 말합니다. 즉, 코드의 저장소라고 볼 수 있습니다. 모듈은 앞으로 우리가 자주 사용하게 될 중요한 기능 중 하나입니다. 이미 만들어져 있는 모듈을 가져와 쓸 수도 있고 아니면 우리가 직접 모듈을 만들어서 사용할 수도 있습니다.
모듈을 사용하는 방법을 알아보겠습니다. 우선 아래와 같이 mycalculator.py 모듈을 만들어 봅시다. 해당 모듈은 사칙연산을 수행하는 코드로 구성되어 있습니다.
# mycalculator.py
test = "you can use this module."
def add(a, b):
return a + b
def mul(a, b):
return a * b
def sub(a, b):
return a - b
def div(a, b):
return a / b
class all_calc():
def __init__(self, a, b):
self.a = a
self.b = b
def add(self):
return self.a + self.b
def mul(self):
return self.a * self.b
def sub(self):
return self.a - self.b
def div(self):
return self.a / self.b원래라면 위의 코드를 mycalculator.py 라는 파일로 저장하여 import 하기만 하면 됩니다. 그렇기에 아래 코드는 일반적인 상황에서는 절대 돌리실 필요가 없으나, LMS 진행을 위해서 돌려주시길 바랍니다. 위의 코드를 텍스트로 가져와 파일로 저장해 주는 방식입니다.
code = '# mycalculator.py\ntest = "you can use this module."\n\ndef add(a, b):\n return a + b\n \ndef mul(a, b):\n return a * b\n\ndef sub(a, b):\n return a - b\n\ndef div(a, b):\n return a / b\n\n\nclass all_calc():\n\n def __init__(self, a, b):\n self.a = a\n self.b = b\n\n def add(self):\n return self.a + self.b\n \n def mul(self):\n return self.a * self.b\n\n def sub(self):\n return self.a - self.b\n\n def div(self):\n return self.a / self.b'
f = open("mycalculator.py", "w")
f.write(code)
f.close()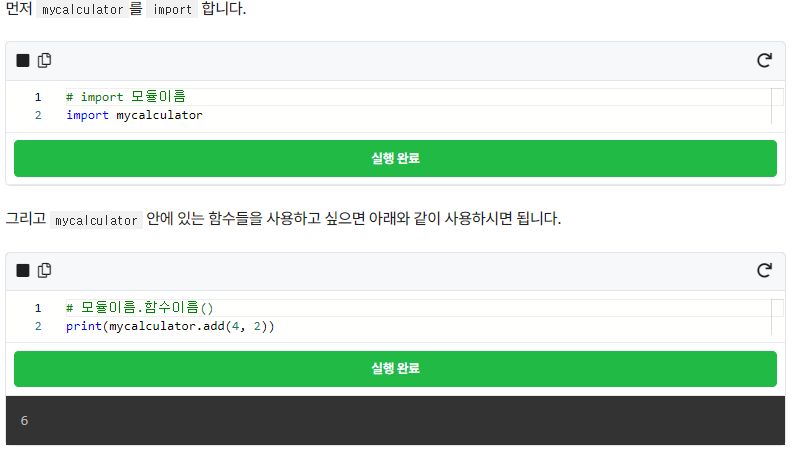
add() 함수의 내부를 짤 필요 없이 모듈만 import 하면 언제 어디서든 쉽게 사용할 수 있습니다.
모듈 이름이 mycalculator로 좀 긴 것 같습니다. 짧게 바꾸고 싶은데 어떻게 해야 할까요? as 구문을 사용하시면 모듈의 별명을 정할 수 있습니다. mycalculator 모듈을 mc라고 별명을 붙여보겠습니다.
import mycalculator as mc
# 모듈이름.함수이름()
print(mc.add(4, 2))6mycalculator가 mc라는 별명을 얻은 이후엔 mycalculator.add(4, 2) 대신 mc.add(4,2)만 적으면 실행됩니다.
패키지
파이썬 프로그래밍에 있어서 여러분들의 능력을 무한정으로 넓혀줄 수 있는 특급 비기를 알려드리겠습니다.
그것은 바로 패키지 입니다! 패키지(라이브러리)는 전 세계의 파이썬 사용자들이 만든 유용한 프로그램을 모아 놓은 보물 주머니 같은 것입니다. 패키지의 다른 말인 라이브러리는 말 그대로 도서관인데 실제 도서관과 비슷한 역할을 합니다. 도서관에는 수많은 책이 있고 거기서 원하는 책을 찾아야 합니다. 그러나 원하는 책을 찾기만 하면 내가 갖고 있는 문제나 궁금증을 해결할 수 있겠죠?
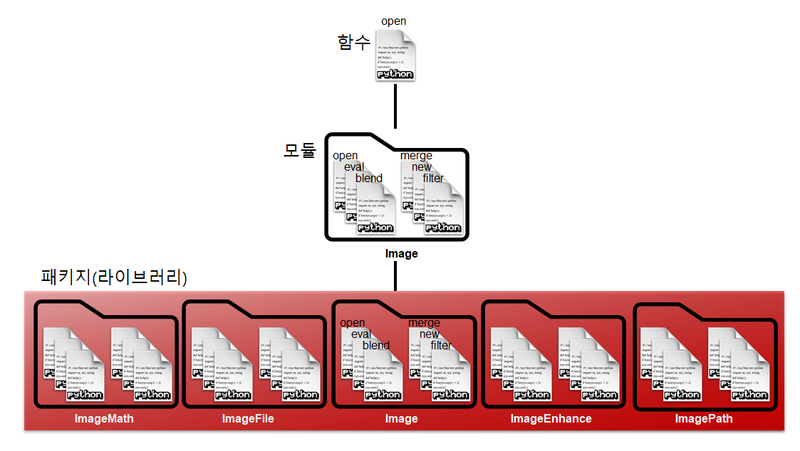
파이썬에서 패키지는 여러 모듈을 하나로 모아둔 폴더라고 할 수 있습니다. 아래 그림을 보시면 종이처럼 보이는 부분이 함수이고, 그 함수 여러 개가 모여서 모듈을 만들고, 모듈이 여러 개 모여 패키지를 이룹니다.
패키지에 대해 알아보았으니 다른 사람들이 만들어 놓은 보물 같은 패키지를 쓰기 전에 먼저 설치하는 방법을 알아보겠습니다.
패키지 설치 방법
거의 모든 패키지는 pip 명령어를 통해서 설치할 수 있습니다. 직접 만들거나 아니면 공개되지 않은 패키지의 경우는 pip을 이용해서 설치하지 못하고 직접 설치를 해야 합니다. 하지만 여러분들이 쓰시게 될 대부분의 패키지는 pip을 이용해서 설치가 가능합니다.
패키지를 설치 명령어는 아래와 같습니다.
# pip install 패키지이름
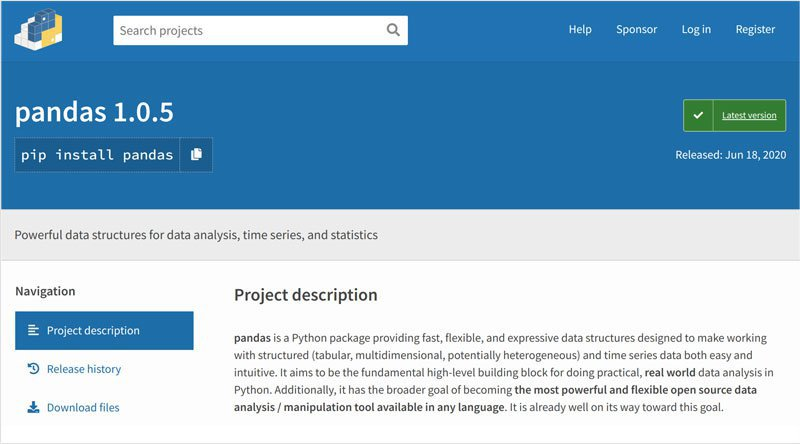
$ pip install pandas설치한 패키지는 pandas라는 패키지입니다.
어떤 패키지가 있는지 찾으려면 pypi.org 사이트를 참고하세요. 남들이 올려놓은 패키지 목록들을 보고 다운로드가 가능합니다.
PyPI · The Python Package Index
아래는 pypi에서 pandas를 검색해 나온 결과입니다. 사진 좌측 상단에서 볼 수 있듯이 pip install pandas 을 바로 복사하여 사용할 수 있습니다.
6-5. 프로그래밍 패러다임과 함수형 프로그래밍
패러다임(Paradigm)은 어떤 한 시대의 사람들의 견해나 사고를 근본적으로 규정하고 있는 테두리를 말하며, 인식의 체계 또는 사물에 대한 이론적인 틀이나 체계를 의미하는 개념입니다. 과거에 우주를 받아들이는 방법 중에 천동설과 지동설이 있었다는 것을 한 번쯤은 들어보신 적이 있으실 것입니다.
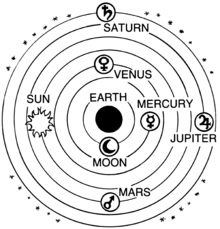
위 사진과 같이 천동설은 지구가 중심에 있고 태양을 비롯한 태양계를 이루는 천체들이 지구를 돌고 있다고 믿는 패러다임입니다. 지동설은 반대로 태양이 중심에 있고 지구가 그 주위를 돌고 있다고 믿는 패러다임입니다. 둘의 사고방식은 완전 다르기 때문에 각 학설마다 우주에 관해 설명하는 방법이 달라집니다. 물론 지금은 우주에 사람이 갈 정도로 발전이 되어 지동설이 맞다는 것을 알고 있지만 과거에는 우주를 설명하는 관점이 서로 달랐습니다.
프로그래밍 패러다임은 위에서 설명한 천동설, 지동설처럼 프로그래머에게 프로그래밍의 관점을 갖게 해 주고, 결정하는 역할을 합니다. 프로그래밍 언어들은 각자 언어 저마다의 프로그래밍 패러다임을 갖고 있습니다. 어떤 언어(Smalltalk, HASKELL)들은 하나의 패러다임만을 지원하기도 하고, 또 어떤 언어(Python, Lisp, Java)들은 여러 개의 패러다임을 지원하기도 합니다.
우리는 데이터 사이언스를 공부하는 입장이기 때문에 여기에 적합한 패러다임을 여러분에게 소개하려고 합니다. 바로 함수형 프로그래밍입니다. 함수형 프로그래밍에 대한 소개와 특징에 관해서 이야기를 해드릴 텐데 입문 수준의 내용이기 때문에 "이런 패러다임이 있구나" 라고만 기억하시면 됩니다. 물론 이 내용을 마음속에 담아놓고 코딩을 할 때 이 기준에 따라서 개발을 하면, 정말 실력 있는 개발자로 발돋움하실 수 있게 되실 것입니다.
절차 지향 프로그래밍과 객체 지향 프로그래밍
절차 지향 프로그래밍
일이 진행되는 순서대로 프로그래밍하는 방법입니다.
- 장점 : 코드가 순차적으로 작성되어 있어 순서대로 읽기만 하면 이해가 가능합니다.
- 단점 : 순차적으로 작성되어 있기 때문에 위에서 하나가 잘못되면 아래도 연쇄적으로 문제가 생겨서 유지 보수가 어렵습니다. 일반적으로 코드 길이가 길어서 코드를 분석하기 어렵습니다.
객체 지향 프로그래밍
객체지향 프로그래밍은 개발자가 프로그램을 상호작용하는 객체들의 집합으로 볼 수 있게 합니다. 객체를 먼저 작성하고 함수를 작성합니다. 이렇게 작성된 객체는 객체 간의 상호작용이 있습니다.
- 장점 : 코드를 재사용하기 쉽습니다. 코드 분석이 쉬우며 아키텍처를 바꾸기 쉽습니다.
- 단점 : 객체 간의 상호작용이 있기 때문에 설계에서 많은 시간이 소요되며 설계를 잘못하면 전체적으로 바꿔야 할 수도 있습니다.
파이썬은 객체지향 프로그래밍(OOP, Object Oriented Programming) 패러다임을 기본적으로 지원하고 있습니다.
함수형 프로그래밍
함수형 프로그래밍은 데이터 사이언티스트에게 적합한 프로그래밍 패러다임입니다. 함수형 프로그래밍은 효율성, 버그 없는 코드, 병렬 프로그래밍과 같은 장점을 제공합니다.
함수형 프로그래밍은 함수로 문제를 분해합니다. 이 함수들은 입력을 받아서 출력을 만들어 내기만 하며, 주어진 입력이 함수를 통과하고 값이 생성되면 이 출력값은 함수 외부의 다른 변수나 함수에 의해 변하지 않습니다.
함수형 프로그래밍이 데이터 사이언티스트에게 적합한 프로그래밍 패러다임인 이유는, 함수형 프로그래밍이 기본적으로 가지고 있는 특징 때문입니다. 아래 특징들을 확인하기 전에 한 가지 예를 들어보겠습니다. 함수형 프로그래밍은 병렬 프로그래밍 측면에서 장점이 있다고 말한 것을 기억하실 것입니다.
AI 연구가 갑자기 붐처럼 일어나게 된 이유가 무엇 때문이었는지 기억하시나요? 알고리즘의 고도화, 알파고 등 이유는 많지만 GPU를 이용한 병렬 처리가 굉장히 큰 역할을 했습니다. 병렬 처리는 어려운 프로그래밍 방법의 하나로 유명합니다. 기본적으로 병렬 처리를 코딩하기도 어려울뿐더러 제약 조건 또한 많기 때문입니다. 제약 조건 중에 하나만 얘기하자면, 하나의 데이터에 동시에 여러 함수가 접근한다고 가정을 했을 때 이들 함수 중에 하나라도 기존 데이터를 수정하는 함수가 있으면, 기존 데이터로 출력을 예상할 수가 없게 됩니다. 만약, 반대로 순차 처리를 한다면 여러 개의 함수가 순서대로 처리되기 때문에 기존 데이터를 바꾼 함수 이후로의 데이터 출력은 예측이 가능한 것이죠.
함수형 프로그래밍의 특징
1. 순수성
함수형 프로그램에서 각 함수는 입력으로부터 동작을 시작해 출력을 만들어 냅니다. 함수형 방식은 내부 상태를 수정하거나 함수의 반환값에서 보이지 않는 다른 변경사항들을 만드는 부작용이 있는 함수를 사용하지 않습니다. 부작용이 전혀 없는 함수를 순수 함수 라고 합니다. 부작용을 피한다는 것은 프로그램이 실행될 때 해당 프로그램이 수정될 수 있는 상황을 엄격히 제한한다는 의미입니다. 그리고 모든 함수의 출력은 입력에만 의존해야 합니다.
어떤 언어는 순수성에 대해 매우 엄격하며, a=3 혹은 c=a+b 와 같은 대입문조차 쓸 수 없지만 모든 문제를 피하는 것이 어렵습니다.
순수성에 대한 코드 예시를 보겠습니다. 아래는 순수성이 없는 코드입니다.
A = 5
def impure_mul(b):
return b * A
print(impure_mul(6))30 위의 함수는 입력으로 들어오는 변수 이외에도 함수 밖에 있는 변수인 A도 함수 내에서 사용하기 때문에 순수성이 없습니다.
이번엔 순수성이 있는 함수를 보겠습니다.
def pure_mul(a, b):
return a * b
print(pure_mul(4, 6))24함수 안에 함수 밖에서 바로 가져오는 함수나 아니면 밖에 있는 변수를 변경시키는 코드가 없습니다. 순수하게 함수 input 2개만을 이용해서 결과를 내보냅니다.
2. 모듈성
함수형 프로그래밍은 문제를 작은 조각으로 분해하도록 강제합니다. 복잡한 변환을 한 함수 안에서 수행하는 거대한 함수보다, 한 가지 작업을 수행하는 작은 함수들로 쪼개어 만드는 것이 코딩하기에 더 쉽습니다. 작은 함수는 가독성도 좋고 오류를 확인하기도 더 쉽습니다. 결과적으로 프로그램은 더욱 모듈화가 됩니다.
3. 디버깅과 테스트 용이성
함수형 프로그래밍으로 개발된 프로그램은 각각의 함수가 작고 명확하게 명시되기 때문에 디버깅을 쉽게 할 수 있습니다. 프로그램이 동작하지 않는다면, 각 함수는 데이터가 올바른지 확인할 수 있는 포인트들이 됩니다. 각 함수의 입력과 출력을 확인하면서 예상되는 것과 다른 출력이 나오면 해당 부분이 문제이기 때문에 디버깅이 쉽습니다.
각 함수는 잠재적으로 단위 테스트의 대상이기 때문에 테스트가 더 쉽습니다. 올바른 입력을 함수에 입력하고 결과가 예상과 일치하는지 확인만 하면 되기 때문이죠.
6-6. 파이써닉하게 코드를 짜보자
파이썬 프로그래머에게 파이썬의 어떤 점이 가장 좋느냐고 묻는다면 아마 뛰어난 가독성이 좋다고 할 것입니다. 실제로 높은 수준의 가독성은 파이썬 언어 디자인의 핵심입니다. 코드 작성은 한 번이지만, 그 코드를 다시 읽거나 고치는 일은 훨씬 더 많기 때문에 코드 가독성은 중요합니다.
파이썬 코드가 쉽게 읽히고 잘 이해되는 이유는 비교적 완벽한 코드 스타일 가이드라인과 “파이썬스러운” 이디엄(코드 작성법) 때문입니다.
파이썬은 pep8이라는 코드 스타일 가이드가 있습니다. 대부분의 개발자가 이 코드 스타일에 따라서 개발을 하고 있습니다. 개발자들이 따르고 있는 스타일이 있다는 것은 많은 도움이 됩니다. 유지 보수 측면에서 빠른 코드 이해로 개발 기간이 줄고 가독성 측면에서도 도움이 됩니다.
참고 자료
Whitespace
- 한 줄의 코드 길이가 79자 이하여야 합니다.
y = a + a + a + a # 79자 이하- 함수와 클래스는 다른 코드와 빈 줄 두 개로 구분합니다.
class a():
pass
# 빈 줄
# 빈 줄
class b():
pass
# 빈 줄
# 빈 줄
def c():
pass
# 빈 줄
# 빈 줄- 클래스에서 함수는 빈 줄 하나로 구분합니다.
class a():
def b():
pass
def c():
pass- 변수 할당 앞뒤에 스페이스를 하나만 사용합니다.
y = 1- 리스트 인덱스, 함수 호출에는 스페이스를 사용하지 않습니다.
my_list = [1, 2, 3]
my_list[0] # 리스트 인덱스 호출
my_function(0) # 함수 호출- 쉼표(,), 쌍점(:), 쌍반점(;) 앞에서는 스페이스를 사용하지 않습니다.
my_list = [1, 2, 3]; my_list[0:1]
if len(my_list) == 3: print my_list주석
- 코드의 내용과 일치하지 않는 주석은 피해야 합니다.
- 불필요한 주석은 피해야 합니다.
이름 규칙
- 변수명 앞에
_(밑줄)이 붙으면 함수 등의 내부에서만 사용되는 변수를 일컫습니다.
_my_list = []- 변수명 뒤에
_(밑줄)이 붙으면 라이브러리 혹은 파이썬 기본 키워드와의 충돌을 피하고 싶을 때 사용합니다.
import_ = "not_import"- 소문자 L, 대문자 O, 대문자 I를 가능하면 사용하지 마세요. 특정 폰트에서는 가독성이 굉장히 안 좋습니다.
- 모듈(Module) 명은 짧은 소문자로 구성되며, 필요하다면 밑줄로 나눕니다.
my_module.py- 클래스 명은 파스칼 케이스(PascalCase) 컨벤션으로 작성합니다. 네이밍 컨벤션은 뒤에서 다시 설명하겠습니다.
class MyClass():
pass- 함수명은 소문자로 구성하되 필요하면 밑줄로 나눕니다.
def my_function():
pass- 상수(Constant)는 모듈 단위에서만 정의하고 모든 단어는 대문자이며, 필요하다면 밑줄로 나눕니다.
MY_PI = 3.14 # 상수는 변하지 않는 변수입니다.네이밍 컨벤션(Naming convention)
실무에선 다른 사람들과 같이 코드를 짜야 하는 경우가 많습니다. 사람들마다 변수명을 적는 방식이 다르면 코드가 깔끔해 보이지 않기 때문에 가독성이 안 좋습니다. 가독성이 좋은 코드를 짜는 방법은 통일성을 갖는 것입니다. 통일성을 갖기 위해선 사람들이 공유하는 코딩 스타일 가이드가 필요합니다. 그래서 파이썬에서는 pep8 이라는 코딩 스타일 가이드를 가지고 있습니다. pep8 코딩 스타일 가이드는 위에서 소개했기 때문에 이번엔 이름을 작성할 때 사용하는 네이밍 컨벤션에 대해서 알아보겠습니다.
대표적인 네이밍 컨벤션은 snake_case, PascalCase, camelCase 입니다. 각 네이밍 컨벤션의 기준에 맞춰 코드를 작성하시면 가독성이 높은 코드가 됩니다.
snake_case
- 모든 공백을 "_"로 바꾸고 모든 단어는 소문자입니다.
- 파이썬에서는 함수, 변수 등을 명명할 때 사용합니다.
- ex) this_snake_case
PascalCase
- 모든 단어가 대문자로 시작합니다.
- UpperCamelCase, CapWords라고 불리기도 합니다.
- 파이썬에서는 클래스를 명명할 때 사용합니다.
- ex) ThisPascalCase
camelCase
- 처음은 소문자로 시작하고 이후의 모든 단어의 첫 글자는 대문자로 합니다.
- lowerCamelCase라고 불리기도 합니다.
- 파이썬에서는 거의 사용하지 않습니다 (Java 등에서 사용)
- ex) thisCamelCase
