
k-NN 을 가지고 classification 하는 방법에 대해서 먼저 생각해 보도록 하겠습니다.
다음처럼 빨간 data와 파란 data가 있습니다.
그때, 여기 보이는 바와 같이 이 주어진 data가 빨간색일지, 파란색일지 우리가 예측해야되는 classification 문제입니다.
가장 좋은 방법은 새로 들어온 data의 주변을 살펴보는 겁니다.
예를 들면은 다음처럼 이 주변 data에서 가장 가까운 하나를 살펴본다면
이 data에 대해서 가장 가까운 하나는 빨간색입니다.
그러니까 새로운 data도 빨간색 아닐까? 하고 말할 수 있습니다.
만약 제일 가까운 3개를 보면 파란 것 2개, 빨간 것 하나가 들어가 있습니다. majority voting을 한다면 파란색, 그러면 얘가 파란색이겠구나라고 말을 할수 있습니다.
다시 5개를 본다면 파란색 3개, 빨간색 2개가 들어가서 쟤는 파란색이라고 말을 하는게 좋겠다 라고 할 수 있습니다.
이것이 k-NN 기법입니다.주변에 몇 개를 볼것인지는 사전에 정해야 됩니다.
그래서 k-NN 라는 게 사전에 k개의 근접, 최근접 이웃을 보고 결정을 하겠다 라는 뜻이 됩니다.
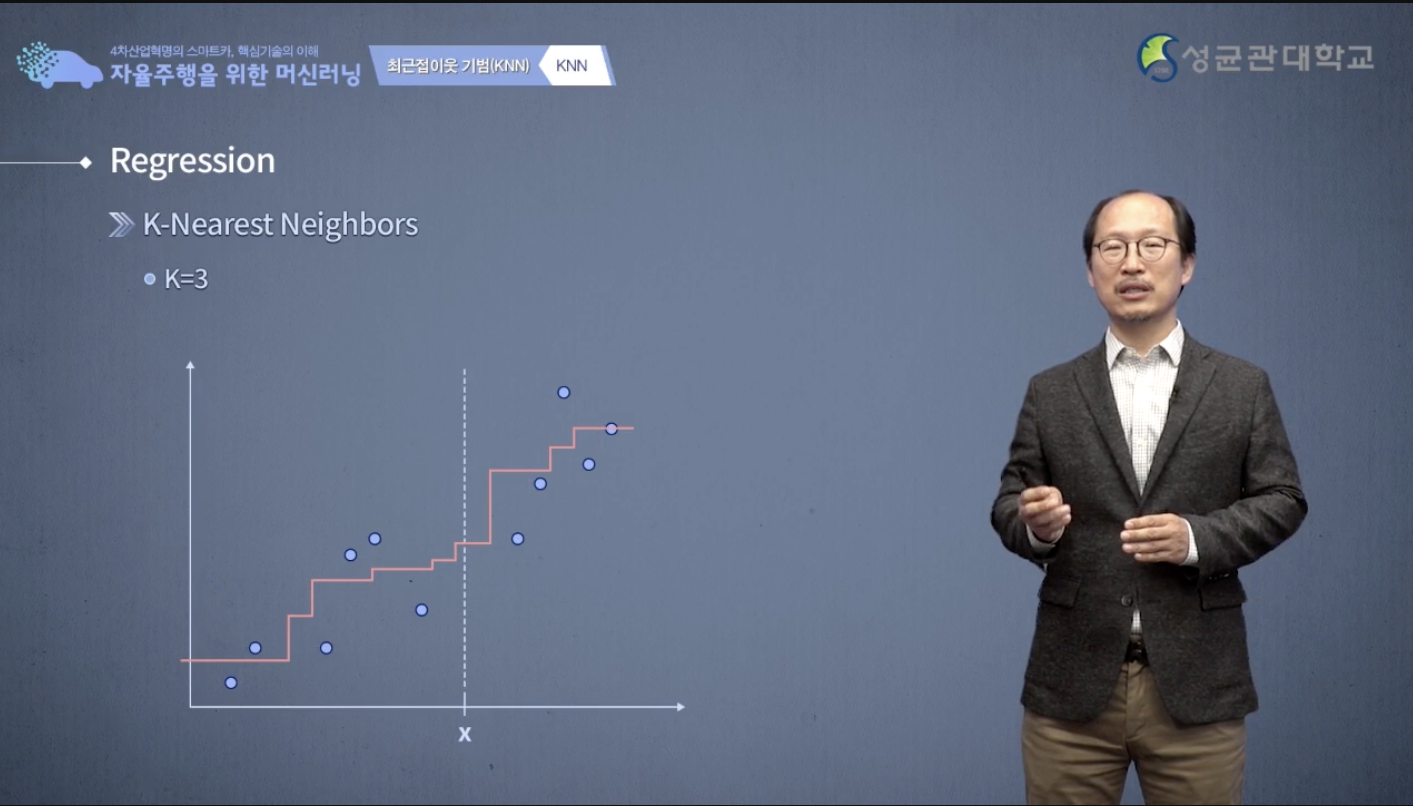
k-NN을 이용해서 regression 을 해결할 수도 있습니다.
새로운 data x가 들어왔을 때 이 x는 어떤 출력을 낼까요?
마찬가지로 k-NN기법을 이용해서 해결 할 수 있습니다.
먼저 x에 대해서 최근접, 이웃을 찾아냅니다.
x축 상에서 x와 제일 가까운 것을 하나 고르면, 바로 왼쪽에 있는 것입니다.
바로 왼쪽에 있는 것이 제일 가까우니까 x는 그것과 같은 y값을 출력을 하겠지 라고 예측하는 겁니다.
따라서 그렇게 우리가 예측값을 만들어 낸다면은 다음과 같은 graph를 만들어 낼 수 있습니다.
k-NN값 주변 data를 조금 더 보면 k 3개를 보면 3개의 평균입니다.
3개의 나와 제일 가까운 3개의 y값의 평균을 살펴보면은 다음처럼, 이런 곡선이 나오게 됩니다.
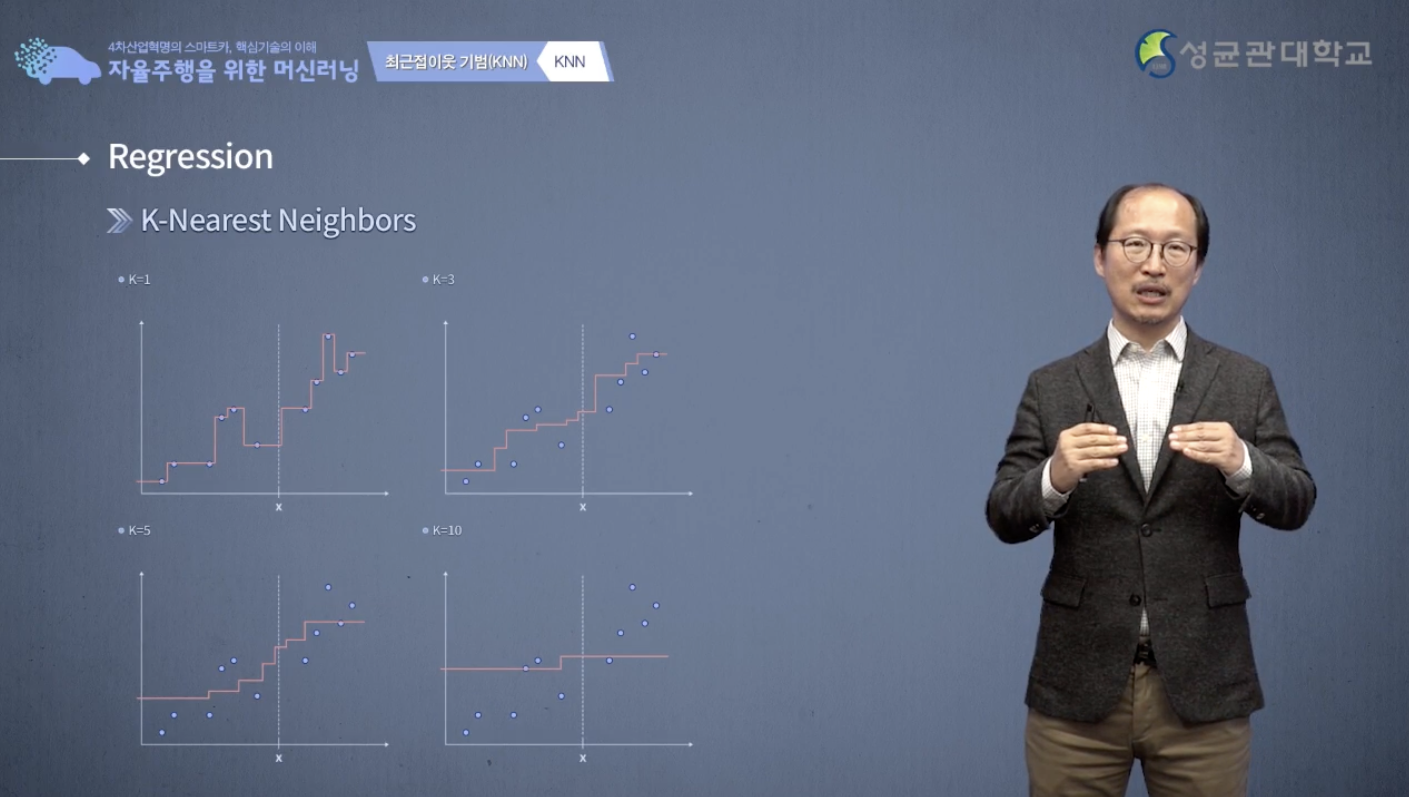
k값이 늘어나면 늘어 날 수록 점점 이 예측의 모양이 점점 단순화 됩니다.
예측의 모양이 복잡해 지면은 언뜻 생각하기에는 예측을 더 잘할 수 있을 것이지만 노이즈에 민감하게 됩니다.
또 너무 단순하면은 예측 성능이 떨어집니다.
k-NN에서는 그거를 k값을 조절 함으로서 찾아 낼 수 있다 라는 사실을 기억하시기 바랍니다.

자 다음에는 k-NN의 변형들에 대해서 살펴보도록 하겠습니다.
우린 지금까지, 예를 들면 k=5라고 봤을 때 나한테 가장 가까운 이웃 5개를 보고, 5개에 대해서 majority 빨간색이 많으면 빨간색 검은색이 많으면 검은색이라고 하였습니다.
지금은 x1과 x 2가 있는데 x1과 x2의 최근접 이웃 5개가 똑같다 라고 가정을 하고 k-NN으로 답을 한다면 x1과 x 2가 똑같이 빨간색이다고 답을 해야 될 것 같습니다.
그런데 그림을 보면 정확히 분류했다 하기 어렵습니다.
regression 도 마찬가지입니다.
regression도 x1과 x2의 최근접 이웃이 다음처럼 빨간 것 3개 검정 것 2개라고 했을 때 x1은 빨간 쪽에 가깝고 x2는 검정 쪽에 가까우니까 최근접 이웃이 가깝다고 x1과 x 2가 같은 y를 갖는다는 것은 좀 무리스럽습니다.

이를 해결하기 위해 거리에 기반한 weight의 summation으로 판단을 합니다.
빨간 것까지의 거리를 고려하고 까만 것까지 거리를 고려해서 그 거리를 weight로 변환을 한 다음에 당연히 가까우면 weight가 높아지고 멀면 그 weight가 떨어집니다.
그래서 그 거리를 weight로 변환을 해서 weight summation을 해서 까만 것까지의 weight summation과 빨간 것의 weight summation을 해서 weight가 큰 쪽으로 결정을 하자라는 것입니다.
regression도 마찬가지로 단순 평균이 아니라, 그런 weight를 고려한 weighted average를 구하자라고 우리가 할 수가 있겠습니다.

weight를 구하는 방법에는 여러가지가 있습니다.
나부터 이웃까지의 거리의 역의 비율로 거리가 멀어지면 weight가 떨어지는 그런 함수를 이용해서 weight 함수를 사용할 수 있습니다.
다음처럼 단순히 1/거리 인 weight 함수를 쓸 수가 있고 아니면 거리의 제곱에다가 exponential을 씌운 것을 사용할 수 있습니다.
아니면 거리에 -를 붙여서 그것을 exponential 함수에 넣어서 거리 함수로 사용 할 수 도 있습니다.
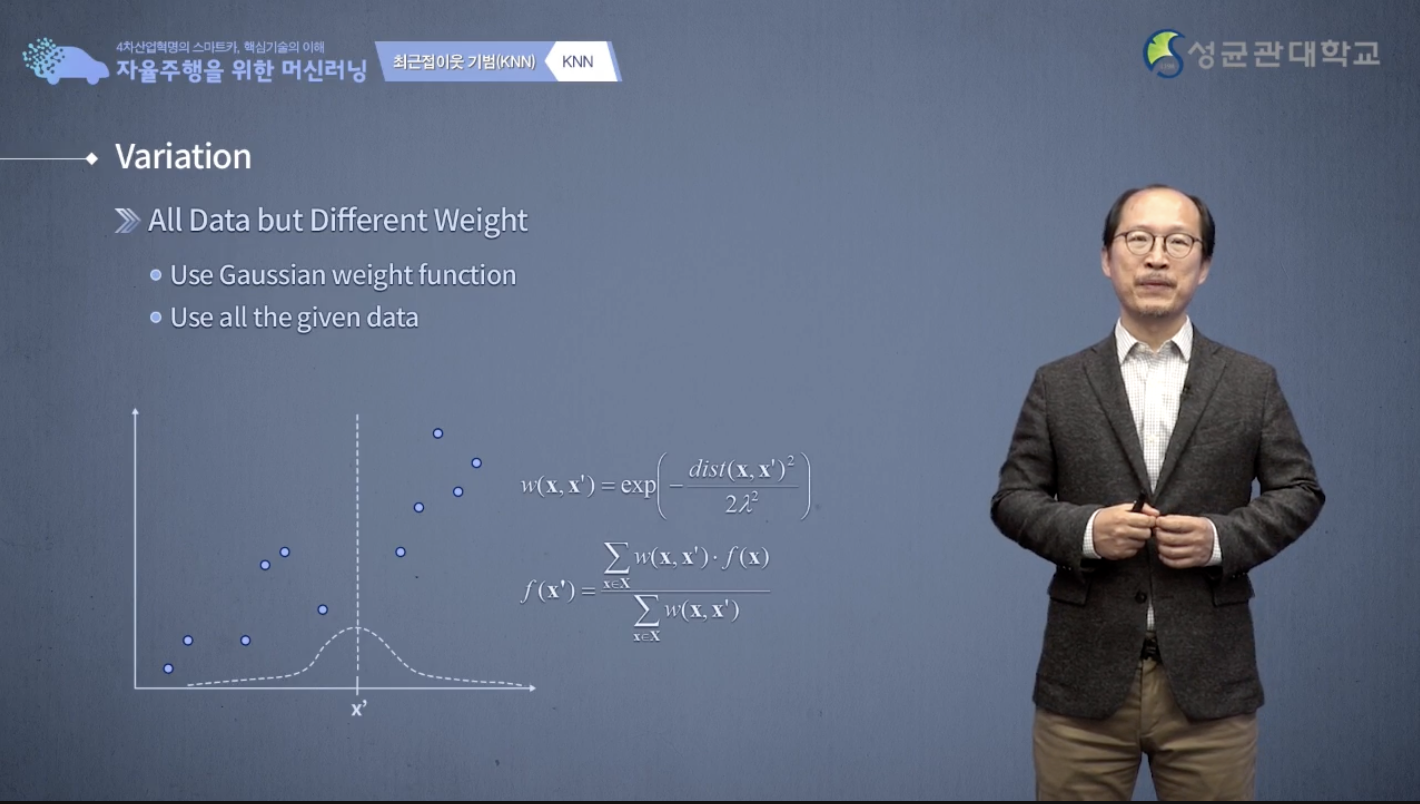
그 다음 variation은 왜 우리가 제일 가까운 애를 선택을 하죠?
그냥 주어진 data를 다 사용하면 되지 않을까요라는 방법이에요.
그러니까 k-NN 기법의 약간 극단적인 방법이라고 볼 수 있죠.
3개든 2개든 5개든 고르는게 아니고 모든 data를 다 사용합니다.
그러니까 모든 data는 다 사용을 하되, 각 data의 weight는 다 다른 것, 예를 들면 이 같은 경우에 weight를 gaussian 함수처럼 weight 함수로 정의를 하고 그 weight에 대해서 밑에 보이는 수식값처럼 weighted average를 하면 이것에 대한 예측을 할 수 가 있습니다.
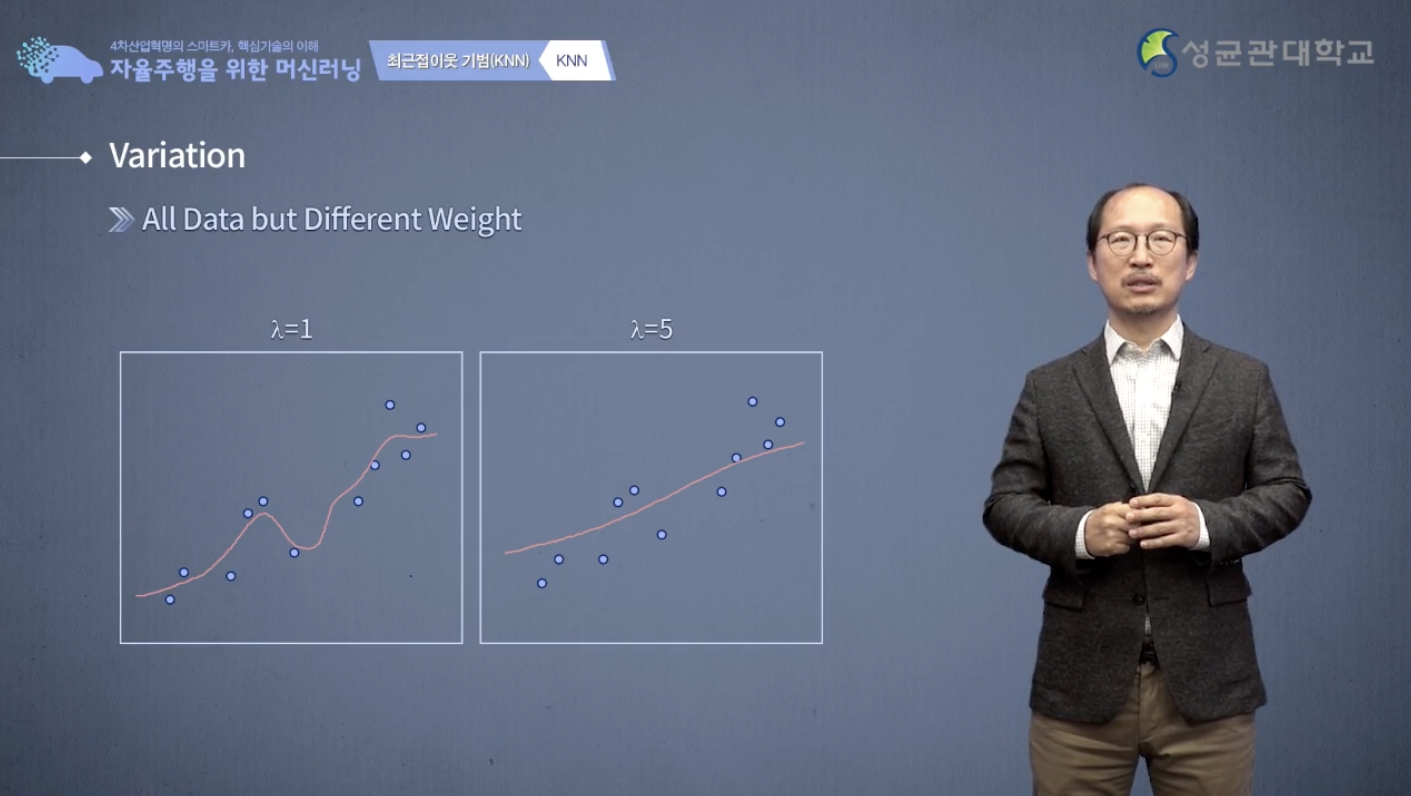
그래서 이렇게 해서 우리가 예측을 하면 다음과 같은 예측 곡선, 빨간 것이 예측 곡선을 만들어 낼 수가 있습니다.
λ=1과 λ=5 의 경우인데 λ는 gaussian 함수에서 표준편차에 해당되는 것입니다.
그래서 이 표준편차 λ가 작다는 얘기는 이 gaussian 함수의 폭이 작다는 것입니다.
나랑 가까운 애들에 아주 큰 weight를 주겠다 라는 의미가 되고 λ가 커지면은 나 말고 내 주변에 있는 다른 많은 애들도 두루두루 고려해서 예측 겠다라는 뜻이 되겠습니다.
그래서 λ가 작을 때는 예측 곡선이 굉장히 이렇게 복잡하게 나오고 λ이 클 때는 조금 smooth한 그런 거를 나온다라는 것을 우리가 알 수 있습니다.
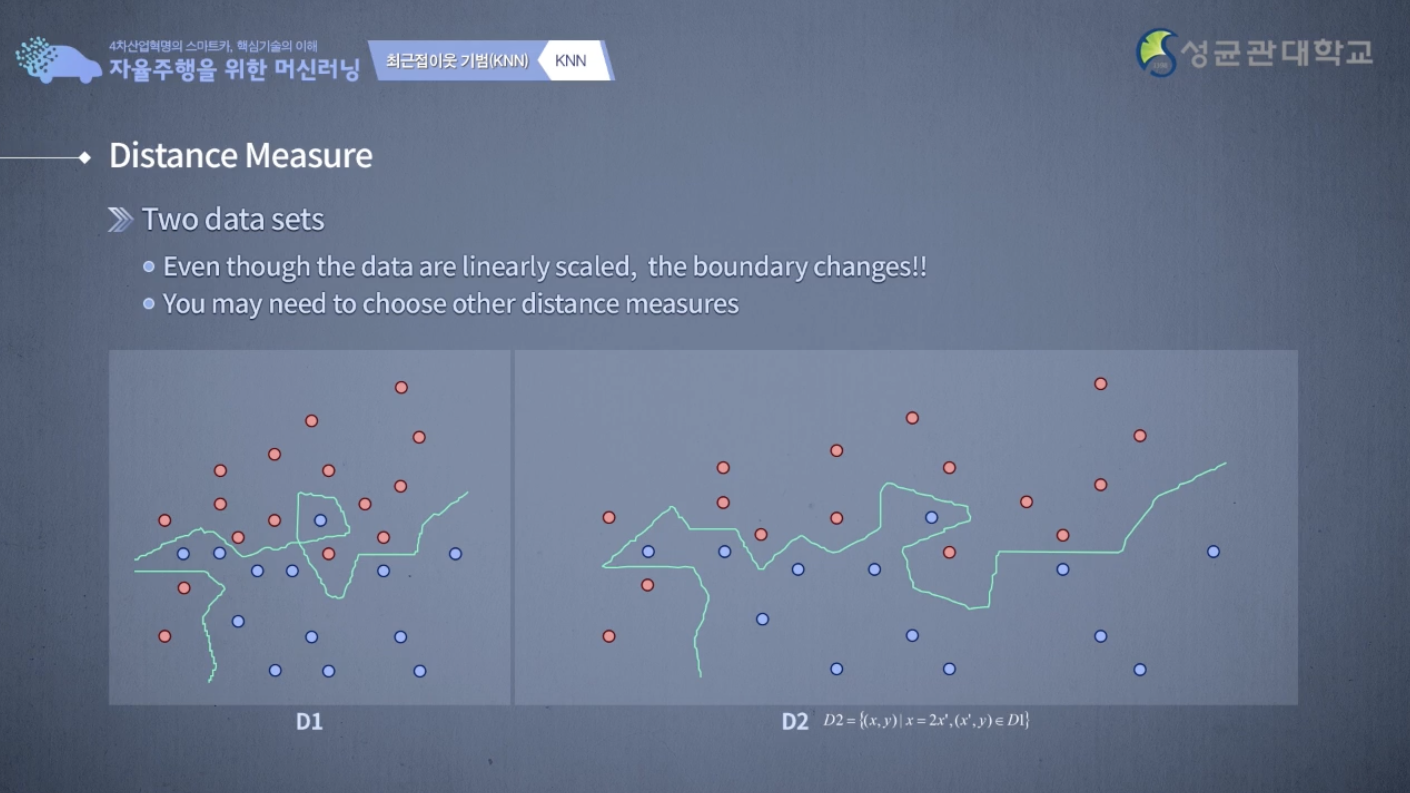
다음은 k-NN에서 사용하면서 여러분이 고려해야 될, 또는 알고 있어야 될 점에 대해서 말 하고자 합니다.
여기 그림에 보시다시피 D1과 D2 data sets이 있는데 다 똑같은데 scale만 x축의 scale 이 2배가 된 상태입니다.
자 이때, 우리가 k-NN을 적용하면 D1과 D2 두 개의 경계면은 다르게 나옵니다.
k-NN은 당연한 얘기인데, scale에 따라 값이 바뀝니다.
상대적으로 똑같은 data일지라도 여러분의 x축을 2배로 늘렸다, 다른 예측 결과가 나옵니다.
y도 x축도 다르게 바꿨다면 다른 예측 결과가 나옵니다.
그래서 어떤 찾고자하는 data에 대해서 x의 scale과 y의 scale 또는 x1의 scale과 x2의 scale이 바뀌면은 분석의 결과도 모두 바뀌게 된다는 사실을 기억하시기 바랍니다.
k-NN에서 중요한 것은 k값을 얼마로 할까?입니다.
k값 사이에서 적당한 중간 위치 그러면서도 예측 성능이 좋은 위치를 찾기 위한 기법들은 여러가지 try and error를 이용해서 찾을 수도 있겠지만
또 그걸 찾아주는 여러가지 cross-validation 같은 test training and test validation data set이라는 것을 활용해도 찾을 수 있습니다.
그리고 k-NN의 장점은 training의 단계가 필요가 없습니다.
또한 갖고 있는 data 다 활용했기 때문에 information loss가 없습니다.
굉장히 좋은 장점인데, 이는 몇가지 단점을 가지고 있습니다.
일단은 noise sensitive 합니다. 그리고 나랑 제일 가까운 애가 누구야라고 찾는 것은 시간이 굉장히 많이 걸리는 작업입니다.
또 이 data를 다 저장하고 있어야 되니까 memory space도 상당히 커질 수 밖에 없는 문제, 단점이 있습니다.

그래서 시간을 줄이기위해 k-NN를 찾기에 너무 어려우니 그걸 근사적으로 찾아주는 quad-tree나 locallity sensitive hashing 기법을 활용을 합니다.
또는 dimension-reduction 기법을 활용해서 차원이 높은 data를
차원을 작게 줄이면은 processing이 훨씬 더 편해질 수 도 있습니다.
아니면 data 백만 개를 갖고 있다는데 줄여서 만 개만 사용하는 sampling을 하거나 clustering을 해서 data 개수를 줄이는 방법도 있습니다.
