1. Anaconda 설치
- 다운로드 페이지로 이동하여 다운받아준다.
(pycharm을 사용해도 상관 없습니다.)
2. jdk 설치
-
다운로드 페이지로 이동하여 다운로드를 받아준다. jdk8 or jdk 11을 받아주세요!!
-
다운을 받은 후 설치를 할 때 경로를 자기가 알기 쉬운 경로로 해주세요(환경 변수 편하게 지정하기 위해서)
C:\jdk <- 저는 여기로 했습니다.
3. spark 설치
-
다운로드 페이지로 이동.

저는 이 상태 그대로 다운 받았습니다.
하둡 버전을 잘 기억해 주세요 -
압축을 풀어주세요
-
압축을 풀어주고 폴더 안으로 들어가 안에 있는 파일을 통채로 복사해주세요.
-
아까처럼 쉬운 경로에 폴더를 하나 만들고 붙여넣기를 해주세요
C:\spark <- 저는 여기로 했습니다.
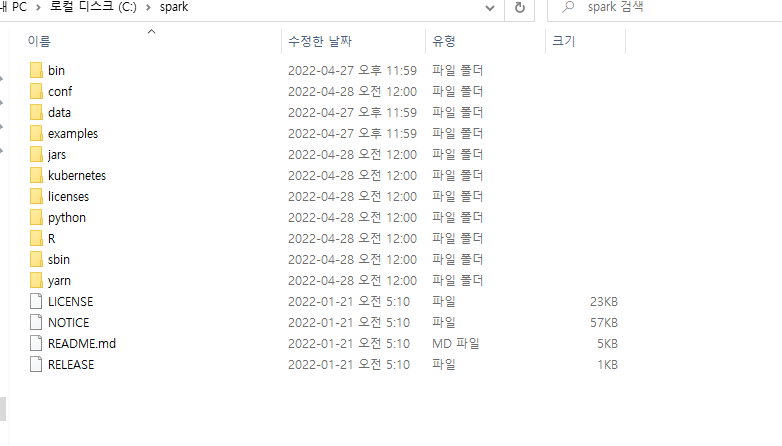
-
설치 폴더로 이동한 후 conf 폴더로 이동해 주세요.
log4j.properties.template 파일의 이름에서 template를 지워주세요

-
properties.template파일을 wordpad로 열어주세요
rootCategory=INFO를 rootCategory=ERROR로 바꿔주세요
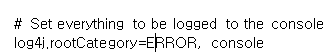
이렇게 하면 작업을 실행할 때 출력하는 모든 logs span의 클러터를 없앨 수 있습니다.
4. winutils 설치
하둡을 설치하지 않아도 spark를 사용할 수 있게 해주는 프로그램(?) 입니다.
-
이곳으로 이동해서 아까의 하둡 버전에 맞는 winutils를 다운로드 해주세요
-
아까처럼 쉬운 경로에 winutils라는 이름의 폴더를 하나 만들어 줍니다.

-
winutils 폴더 안에 bin 폴더를 만들어 주세요.
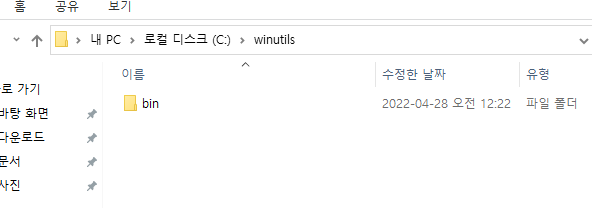
-
bin 폴더 안에 아까 다운받은 winutils 파일을 넣어 주세요.
-
cmd를 켜주고 winutils\bin 폴더로 이동해줍니다.
- mkdir c:\tmp\hive 입력
- winutils.exe chmod 777 \tmp\hive 입력 (스파크를 실행할 때 오류 없이 실행되도록 파일 사용 권한을 줌)
5. 환경 변수 설정
사용자 변수 or 시스템 변수에 추가해주면 된다.
1. 새로 만들기 클릭

-
변수 이름 : HADOOP_HOME 변수 값 : winutils 폴더
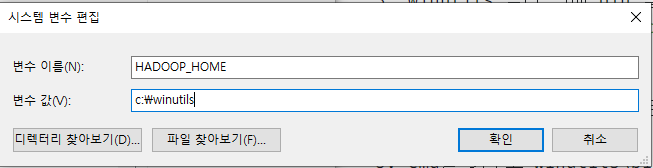
-
새로 만들기 클릭
변수 이름 : JAVA_HOME 변수 값 : jdk폴더
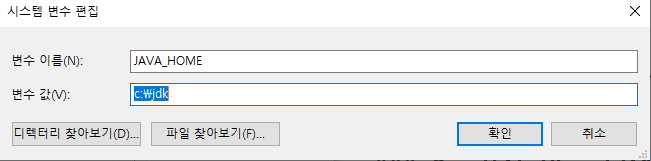
-
새로 만들기 클릭
변수 이름 : SPARK_HOME 변수 값 : spark폴더
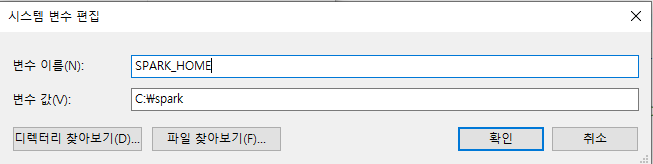
-
만약 spark 3.1 버전 이상이면
새로 만들기 -> 변수 이름 : PYSPARK_PYTHON 변수 값 : python
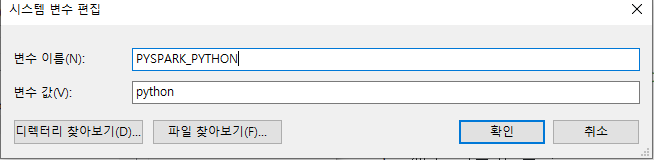
-
path 편집 (저는 시스템 변수에 했습니다. 사용자 변수도 똑같습니다!)
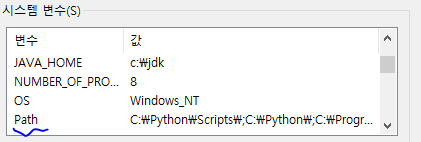
path 더블 클릭 -> 새로 만들기 -> %SPARK_HOME%\bin -> 새로 만들기 -> %JAVA_HOME%\bin -> 확인 -> 확인 -> 확인

6. 설치 확인
-
anaconda prompt 실행(cmd로 하셔도 상관 없습니다!)
-
spark 설치 폴더로 이동해 줍니다.
-
안에 readme.md 파일이 있습니다.
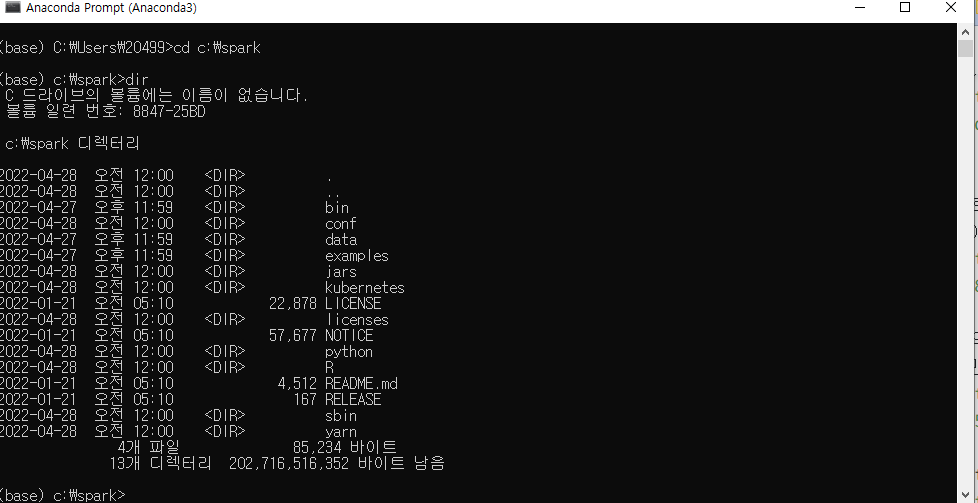
-
pyspark 입력 -> 엔터
로고가 뜨면 성공
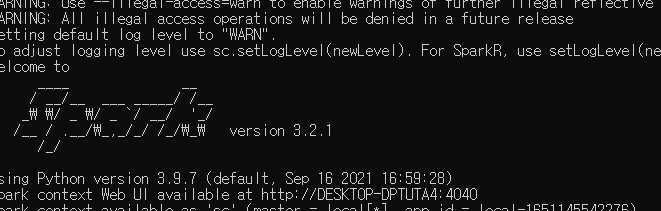
-
이 파일의 줄 수를 세어봅시다!
rdd = sc.textFile("README.md")
rdd.count()
고생하셨습니다!!
