
해당 글은 <Do it! BERT와 GPT로 배우는 자연어 처리> 책을 읽고 정리한 글입니다.
1-1 딥러닝 기반 자연어 처리 모델
기계가 사람 말을 알아듣는 것처럼 보이게 하려면 어떤 요소들이 필요할까?
모델 model : 입력을 받아 어떤 처리를 수행하는 함수 function
모델은 어떤 입력을 받아서 해당 입력이 특정 범주일 확률을 반환하는 확률 함수이다.
따라서 자연어 처리 모델이란 자연어를 입력받아 해당 입력이 특정 범주일 확률을 반환하는 확률 함수이다.
그렇다면 요즘 가장 인기 있는 모델의 종류는 무엇일까?
바로 딥러닝이다. 기존의 다른 구조보다 성능이 월등히 좋기 때문이다.
딥러닝 가운데서도 BERT와 GPT등이 특히 주목을 받고 있으며 이들을 딥러닝 기반 자연어 처리 모델 이라 한다.
딥러닝 기반 자연어 처리 모델의 출력 역시 확률이다.
하지만 사람은 자연어 형태의 출력을 선호하므로, 우리는 이해하기 쉽도록 후처리(post processing)를 해서 자연어 형태로 바꿔 주는 것이다.
사람의 말을 잘 알아듣는 것처럼 보이는 인공지능도 결국은 이 일련의 계산 과정으로 나온 결과가 그럴싸하기 때문인 것이다.
딥러닝 자연어 처리 모델을 만들려면 무엇이 필요한가?
가장 처음으로 데이터를 준비해야 한다.
그 다음 모델이 데이터의 패턴을 스스로 익히게 해야 한다.
이러한 과정을 학습이라고 한다.
즉, 학습이란 출력이 정답에 가까워지도록 모델을 업데이트하는 과정을 말한다.
1-2 트랜스퍼 러닝
트랜스퍼 러닝(transfer learning) 이란 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법이다.
트랜스퍼 러닝을 적용하면 기존보다 모델의 학습 속도가 빨라지고 새로운 태스크를 더 잘 수행하는 경향이 있다.
BERT, GPT등도 트랜스퍼 러닝이 적용됐다.
업스트림(upstream) 태스크 는 주로 다음 단어 맞히기, 빈칸 채우기 등 대규모 말뭉치의 문맥을 이해하는 과제 (태스크1), 다운스트림(downstream)태스크는 문서 분류, 개체명 인식 등 우리가 풀고자 하는 자연어 처리의 구체적인 문제(태스크2)들로 나뉠 수 있다.
여기서 업스트림 태스크를 학습하는 과정을 프리트레인(pretrain)이라고 부른다.
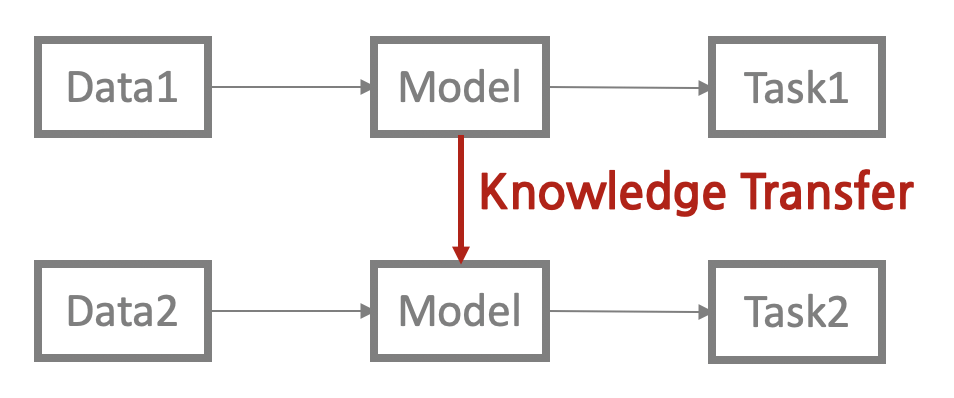
업스트림(upstream) 태스크
대표적인 업스트림 태스크 가운데 하나가 다음 단어 맞히기, GPT 계열 모델이다.
모델이 대규모 말뭉치를 가지고 맞혀야 할 다음 단어를 예측하는 과정을 반복 수행하면 이전 문맥을 고려했을 때 어떤 단어가 그 다음에 오는 것이 자연스러운지 알 수 있게 된다.
이것이 언어 모델(language model)이다.
또 다른 업스트림 태스크는 빈칸 채우기이며, BERT 계열 모델이 이 태스크로 프리 트레인을 수행한다.
이처럼 빈칸 채우기로 업스트림 태스크를 수행한 모델을 마스크 언어 모델 (masked language model) 이라고 한다.
사람이 만든 정답 데이터로 모델을 학습하는 방법을 지도 학습 (supervised learning) 이라고 한다.
뉴스, 웹 문서, 백과사전 등 글만 있으면 수작업 없이도 다량의 학습 데이터를 아주 싼값에 만들어 낼 수 있게 되면서 업스트림 태스크를 수행한 모델의 성능이 매우 향상되었다. 이처럼 데이터 내에서 정답을 만들고 이를 바탕으로 모델을 학습하는 방법을 자기지도 학습(self-supervised learning)이라고 한다.
다운스트림 태스크
업스트림 태스크로 프리트레인한 근본 이유는 다운스트림 태스크를 잘 하기 위해서이다.
해당 책에서 소개하는 다운스트림 태스크의 본질은 분류(classification) 이다.
파인튜닝?
파인튜닝(fine-tuning) 은 프리트레인을 마친 모델을 다운스트림 태스크에 맞게 업데이트하는 기법이며 책에서 주로 다룰 다운스트림 태스크 학습 방식이다.
파인튜닝 이외에도 여러가지 학습 방식이 있다.
- 프롬프트 튜닝
- 인컨텍스트 러닝 (제로샷 러닝, 원샷 러닝, 퓨샷 러닝)
