" 1. channel reassembly technique"
: outlier channel들의 large activation magnitude를 channel들에 걸쳐서 redistribution
- channel disassembly
outlier channel들을 여러 sub-channle들로 disassemble. channel들에 걸쳐 더 uniform한 activation range를 갖게함. - channel assembly
similar한 channel들을 assemble해서 original channel count를 유지한다. - adaptive disassembly channels for each layer
각 channel의 disassemble할 개수를 apdative하게 결정함
"
tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model.
After training, these low-rank parameters can be fused into the frozen weights w/o affecting inference.
Motivation
4-bit weight and/or activation quantization,
existing PTQ methods 성능 하락 큼.
LLM의 unique한 패턴인 특정 activiation channel들이 large magnitude를 갖는다.
- 이로 인해 normal qunatization value들이 부정밀하게 Q됨.
- 보통 hardware efficiency를 위해 layer-wise, token-wise activation Q를 사용하는데, 이 문제가 더 커짐.
최근 연구는 mathematically equivalent transformation을 사용해서,
activation outlier들을 smoothing해서 activations의 magnitude를 weight로 transition한다.
smoothQuant, outlier suppression, outlier suppression+, OmniQuant
하지만, Figure 1과 같이, 다른 outlier보다 50배 이상 큰 activation outlier들의 경우, 이전 연구로는 제한된 alleviation만 가능하다.
Methods
-
Channel disassembly
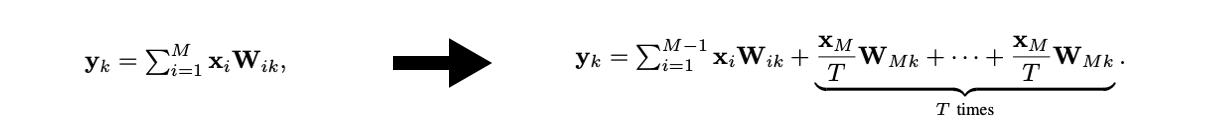
-
Channel assembly
-
channel disassembly로 인해, input channel 개수가 개에서 개로 증가함.
LLM의 꽤 많은 channel이 주어졌을 때, 몇 개의 unimportant channels를 omit하거나,
유사한 input channel들을 merge해서,
input channel 개수를 개로 유지할 수 있다. -
이를 위해서, straightforward한 method는 channel pruning을 사용해서, unimportant channel들을 direct하게 제거하는 것이다.
LLM-Pruner(2023)
A simple and effective pruning approach for large language models(2023)
하지만, 이 방법은 특히 가 클 때, 꽤 큰 information loss를 가져온다.
- 유사한 token들을 combine하는 최근 연구에 motivated받아,
개의 유사한 input channel들을 merging하는 channel assembly를 제안한다.
Token Merging: Your ViT but faster(2023)
Token Merging for Fast Stable Diffusion(2023)
