
들어가기에 앞서
- 해당 포스팅은 "파이썬 생활미락형 프로젝트 - 김효실"님의 책을 보고 작성되었음을 알립니다.
1.1 크롤링
[목표!]
- 원하는 사진들을 웹 브라우저 내에서 일일이 직접 다운로드 받은 기억이 있다면 이번 프로젝트에서는 open api를 사용해
크롤링이라는 방법을 사용해 다운 받아보자!
크롤링이란?
- 간단하게 크롤링은 웹페이지를 그대로 긁어와 거기서 데이터를 추출하는 방식을 의미합니다.
- 검색 엔진들은 검색했을 때 더 많고 다양한 정보를 제공해주기 위해서 자동화된 크롤링 기법을 사용하는데 이때 스파이더, 봇, 지능 에이전트 등을 사용해 자동으로 정보를 모아주는데 이 부분에 대해서 더 자세히 알고 싶다면 HTTP 관련 서적을 읽어보는 것을 추천합니다!
1.2 사전 준비하기
- 카카오 개발자 사이트에 가입한다.(https://developers.kakao.com/)
- 애플리케이션을 만들어 앱 키를 발급 받는다.
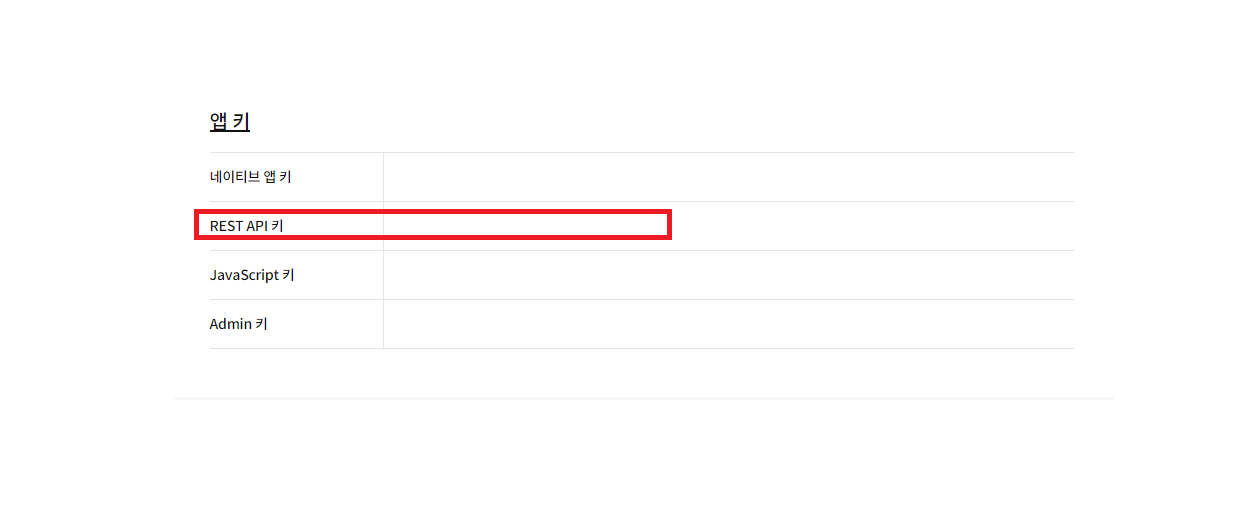
- 앱 키를 발급 받은 뒤 우리가 봐야 하는 앱 키는
REST API키입니다.
1.3 사전 지식 쌓기
파일 읽고 쓰기
# 파일 쓰기
data = "hello~!"
#(파일이름, 쓰기모드)
with open("test.txt", "w") as fp:
fp.write(data)
#파일 읽기
#(파일이름, 읽기모드)
with open("test.txt", "r") as fp:
print("=========[ 파일 읽기 결과 ]===========")
print(fp.read())
- 파일을 쓰면 test.txt 형식의 텍스트 파일이 있고 그 파일에 내용엔 hello~!가 적혀 있습니다.
- 파일을 읽으면 해당 IDLE Shell 창에 해당 print문이 출력됩니다.
웹에 있는 이미지 파일 저장하기
여기서 의문점을 가져봅시다. 우리는 해당 이미지가 있는 url을 치면 해당 이미지가 보이게 되는데 어떻게 이런 일이 가능할까요?
👉 브라우저 앱은 URL을 서버에게 요청하고 서버에선 요청 받은 정보를 다시 클라이어트인 웹 브라우저에게 응답해준 뒤, 전달받은 정보(html형태)를 해석해 사용자에게 보여주는 역할을 합니다.
해당 여러 데이터(리소스)가 있는 url을 요청한 뒤, 우리가 필요한 이미지 파일만을 저장하기 위해서는?
👉 우리가 웹에 있는 이미지를 파일로 저장하기 위해서는 브라우저 앱처럼 서버에게 요청하고, 전달받은 정보 중 이미지 정보만을 저장하면 됩니다. (다른 정보들을 다 저장할 필요가 없습니다.)
url 요청으로 이미지 저장하는 코드
# 외부 모듈 호출
import requests
# 이미지가 있는 url 주소
url = "https://t1.daumcdn.net/cfile/tistory/99F5FB475E0C84F214"
# 해당 url로 서버에게 요청
img_response = requests.get(url)
# 요청 성공 시
# http status code 200 - 성공 / 300 - 리다이렉트 / 400 - 실패(대부분 클라이언트 과실) / 500 - 서버 과실
if img_response.status_code == 200:
print("===========[ 이미지 저장 ]============")
with open("test.jpg", "wb") as fp:
fp.write(img_response.content)코드 실행 결과
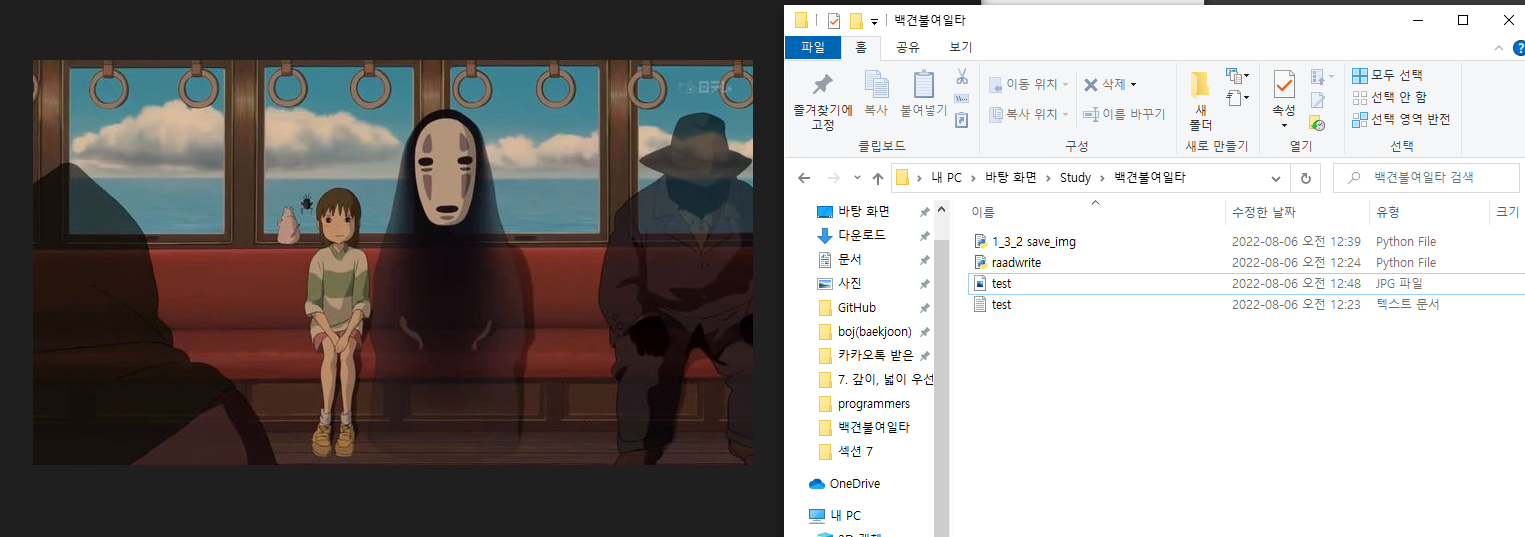
- 완벽하게 이미지만 가져와 파일로 저장 성공!
어떻게 이런 일이 가능할까?
👉print(img_response.content)를 해보게 되면 바이너리 형태로 jpeg로 표현했고 이를 이미지 파일로 저장하면 비로소 이미지가 보이게 되는 것입니다.
Open API와 Open Source의 차이점?
open API는 open source와는 달리 자신의 프로그램 소스를 공개하진 않습니다.
다만 open API를 제공하는 측에서 가지고 있는 자원에 대한 제어권을 open 한다는 것입니다.
📌출처: https://creator1022.tistory.com/66
기존 IDLE Python으로 requests가 호출되지 않을 때 해결법
- https://shaeod.tistory.com/929 - 전체적인 방법
- https://webdir.tistory.com/549 - App data 숨김 폴더 해제 방법

즐겁고 괴로운 개발😎