
이번 프로젝트에서 기업의 요구사항을 만족하기 위해서는 DB가 필요하다. 요구사항은 다음과 같다.
- 사내 서버에 나뉘어 저장된 파일과 폴더를 클라우드 환경으로 이전
- 키워드 검색으로 파일을 찾을 수 있는 검색 서비스 제공
핵심은 저장과 검색이다.
데이터 저장
기업에서 제공하는 DATA는 .dwg파일과 .pdf이다. 파일들의 크기를 확인해보니 1KB 부터 10MB까지 다양했고 평균은 1~3MB였다. 파일의 크기가 너무 커지게 되면 query시간이 늘어나고 결과적으로 서비스의 속도가 느려진다. 때문에 별도의 스토리지 서버가 필요했다.
파일 자체는 스토리지 서버에 저장하고 DB에는 무엇을 저장할까?
DB에 들어가는 데이터
지금 시점에서 DB에 들어가는 DATA는 다음과 같다. dwg도면파일만 다루겠다.
- 제목
- 생성 날짜
- 수정 날짜
- 파일 내 전체 텍스트
- 검색용 키워드
여기서 5번이 문제다. 지하철, 공항, 신도시 등 다양한 도면 파일이 존재하는데 주제가 다르기에 추출되는 키워드가 전부 다를 뿐더러 키워드의 양에도 많은 차이가 있다. 이런 이유로 칼럼의 추가, 제거가 빈번히 발생해 테이블을 확정하는 것이 굉장히 어렵다. 이는 데이터가 추가될수록 더 어려워질 것이라 예상했다.
또한 검색 기능이 필요한데 RDBMS중 유일하게 Full-text-search를 지원하는 MySQL은 한글 검색을 지원하지 않았다.
때문에 No-SQL을 선택하게 되었다.
데이터는 보관 기한이 정해져 있기 때문에 회사의 규모가 커지지 않는 한 데이터 양은 일정하게 유지된다. 때문에 확장성은 일단 서비스가 돌아가게 만든 후 고민하는 것으로 결정했다.
No-sql DBMS 선택
이제 어떤 No-sql DBMS를 선택할지에 대한 고민을 시작했다. 솔직히 가장 많이 쓰는 MongoDB를 선택하고 싶은 마음이 굴뚝같았다. 하지만 프로젝트의 이름부터가 엔지니어링 데이터 검색 시스템이기에 검색 기능을 생각해야 했다.
후보는 MongoDB와 Elasticsearch다. "reverse-index, full-text-search를 둘다 지원하니까 쓰기 쉬운 MongoDB로 가자"라고 생각하다가 멘토님께서 의견을 주셨다.
기업이 어느정도의 검색 기능을 생가하는가에 따라 다르다.
현재 기업은 구글 검색처럼 사용하는 것을 생각하고 있다. 사내에서 사용하기 때문에 딥러닝 기반의 검색엔진의 퀄리티는 아니지만 제안 도구 정도는 필요하고 공백이나 오타에 의해 검색이 되지 않는다면 FTP에서 탐색기를 사용하는 것과 차이가 없다고 생각해서 Elasticsearch의 필요성을 생각하게 되었다.
결정적으로는 관련도 순으로 정렬을 해야하는데 엘라스틱 서치가 이것을 제공하기에 Elasticsearch를 선택할 수 밖에 없었다.
Elasticsearch
Elasticsearch는 Apache Lucene을 기반으로 구축된 검색 엔진이다.
Apache Lucene은 Java언어로 이루어진 오픈 소스 형태의 정보 검색 라이브러리다. 즉 검색 엔진을 만드는데 사용되는 라이브러리다.
엘라스틱 서치는 클러스터를 기반으로 구성되어 있다.
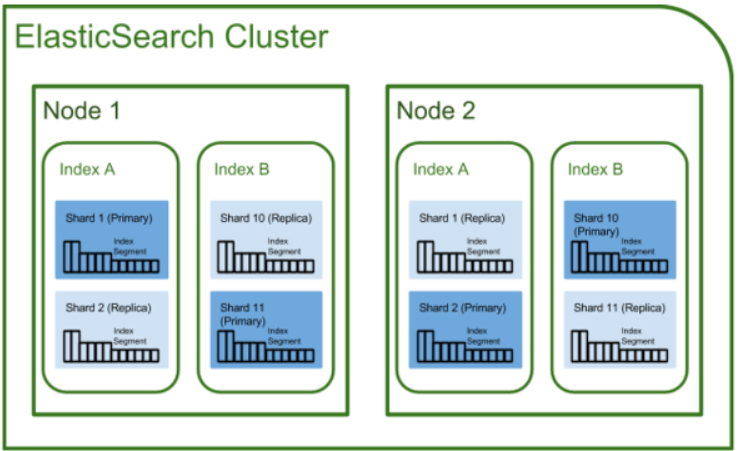
물리적 아키텍처
클러스터
클러스터는 하나 이상의 Elasticsearch 노드들로 구성된 노드의 집합을 의미힌다. Elasticsearch는 고가용성과 빠른 응답을 위해 여러 노드에 데이터를 복제, 샤딩하여 저장하기 때문에 여러 노드를 모아서 클러스터를 구성하는 것이 일반적이다.
노드
여기서 노드란 Elasticsearch가 실행중인 하나의 프로세스 혹은 인스턴스를 말한다. 3종류의 노드가 있다.
- Elasticsearch master node: 인덱스 생성, 삭제를 포함한 모든 클러스터 전체의 작업을 담당한다.
- Elasticsearch data node: 데이터와 역인덱스를 저장한다. node의 기본 설정이다.
- Elasticsearch client node: 들어오는 요청들을 다양한 클러스터 노드로 라우팅 해주는 로드밸런서의 역할을 한다.
샤드
각 Index에 저장할 수 있는 문서 수는 제한이 없다. 하지만 인덱스가 호스팅 서버의 스토리지 제한을 초과하면 오류가 발생한다. 이것을 해결하기 위해 Index는 Shard라고 하는 작은 조각으로 분할된다. 이 때문에 검색 요청이 들어왔을 때 shard에는 검색중인 문서가 존재한다.
Shard는 작고 확장가능한 인덱싱 단위이다. 이 각각은 클러스터의 모든 위치에서 호스팅할 수 있는 독립적인 Lucene 인덱스로 작동한다.
인덱스를 한 개의 샤드로 구성할 수 있지만 인덱스 크기가 커질 경우 여러 서버에 나누어 보관하기 위해 보통 여러개의 샤드로 구성한다.
레플리카
Elasticsearch에서 Replica는 shard의 복사본이다. 주로 백업을 목적으로 사용되기에 원본이 들어있는 노드에는 배치되지 않고 각각 다른 위치에 저장된다.
Replica는 분산 환경에서 데이터의 신뢰성을 높이기 위해 사용한다. 더 많은 복제본을 만들수록 데이터 유실로부터 안전하지만 저장을 위한 리소스가 더 많이 발생한다.
논리적 아키텍처

위에서 엘라스틱 서치를 Apache Lucene기반으로 구축된 검색엔진이라 했다. 그러나 공식 docs에서는 다음과 같이 써있다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/documents-indices.html
Elasticsearch is a distributed document store.
클러스터에 여러개의 노드가 있다면 저장된 document는 클러스터 전체에 분산되고 모든 node에서 접근 가능하다.
일라스틱 서치는 빠른 full text search를 지원하기 위해 inverted index라고 하는 자료구조를 사용한다. 이 인덱스들은 모든 document에 나타나는 특정한 단어들을 나열하고 이 단어가 위치한 문서들을 식별한다.
Mapping
하나의 Document를 구성하기 위해 필요한 Field와 그들의 속성 등을 정의하고 indexing되는 방법을 정의하는 프로세스로 RDBMS의 Schema에 대응된다. 이 때문에 Document내 새로운 Field를 자동으로 검색해 Index에 추가할 수 있다. 이를 Dynamic Mapping이라 한다.
Index
공식docs의 표현을 빌리면 index는 최적의 document집합이다. 왜 최적이지..?
Document
Document는 Index내에 저장된 JSON 객체다. 실제로 검색 할 데이터 즉, 실제 데이터를 저장하는 단위를 의미한다. 여러 Field의 집합이며 RDBMS의 row와 대응된다.
Field
필드는 key-value 쌍으로 구성된 Elasticsearch에서 가장 작은 데이터 단위다.
Elasticsearch는 모든 Field의 Data를 indexing하고 indexing된 field는 각각 최적의 자료구조를 갖는다. 만약 indexing된 field가 text field라면 inverted indices(mapping 정보를 저장하는 logical data storage)에 저장된다. 만약 해당 field가 숫자 혹은 geo(위도, 경도를 표현)라면 BKD tree에 저장된다.
이렇게 field별로 자료 구조를 사용하는 것은 Elasticsearch의 속도를 빠르게 한다.
작동 순서
- cluster에 search 요청을 보낸다.
- 해당 요청이 cluster에 특정 node를 지난다.
-> cluser 내 모든 node는 어떤 node에 어떤 index와 shard가 있는지 알고 있다. 때문에 요청이 통과할 node를 적절하게 선택할 수 있다. - 로드 밸런서에 의해 한 shard가 선택된다.
-> index 내의 모든 shard에 해당 요청이 routing되어 있다. - 각각의 shard가 관련성 상위 10(기본값)개를 아까 선택한 node로 보낸다.
- 해당 node가 결과 값을 사용자에게 리턴한다.
