Chapter1. 웹 애플리케이션 아키텍처
1-1. 클라이언트 - 서버 아키텍처
1-2. 클라이언트 - 서버 통신과 APIChapter2. 브라우저의 작동 원리 (보이지 않는 곳)
2-1. URL과 URI
2-2. IP와 포트
2-3. 도메인과 DNS
2-4. 크롬 브라우저 에러 읽기Chapter3. HTTP
3-1. HTTP Messages
3-2. HTTP Requests
3-3. HTTP ResponsesChapter4. 브라우저의 작동 원리 (보이는 곳)
4-1. SPA를 만드는 기술: AJAX
4-2. SSR과 CSR
Chapter1. 웹 애플리케이션 아키텍처
2-Tier 아키텍처, 또는 클라이언트-서버 아키텍처
상품 정보 같은 리소스가 존재하는 곳과 리소스를 사용하는 앱을 분리시킨 것
클라이언트 → 프론트엔드 영역
- 클라이언트는 서버에 요청을 보내고, 응답을 받는다.
- 유저와의 전반적인 상호작용을 담당한다.
- 리소스를 사용하는 곳
- 보통 플랫폼에 따라 구분
서버 → 백엔드 영역
- 서버는 요청에 따라 적절한 응답을 클라이언트로 회신한다.
- 서버는 데이터베이스에 요청을 보내고, 응답을 받는다.
- 리소스를 제공(serve)하는 곳
- 클라이언트와 서버는 요청과 응답을 주고받는 관계.
3-Tier 아키텍처
- 기존 2티어 아키텍처에 데이터베이스(리소스를 저장하는 공간을 별도로 마련한 공간)가 추가된 형태
데이터베이스도 데이터 제공자로서 일하므로 일종의 서버다.
📌 클라이언트 - 서버 통신과 API
클라이언트와 서버 간의 통신은 요청과 응답으로 구성된다.
요청이 있어야만 응답이 온다.
서버통신
프로토콜(통신규약)
- 웹 애플리케이션 아키텍처에서는 클라이언트와 서버가 서로
HTTP라는 프로토콜을 이용해 상호작용 함.
주요 프로토콜
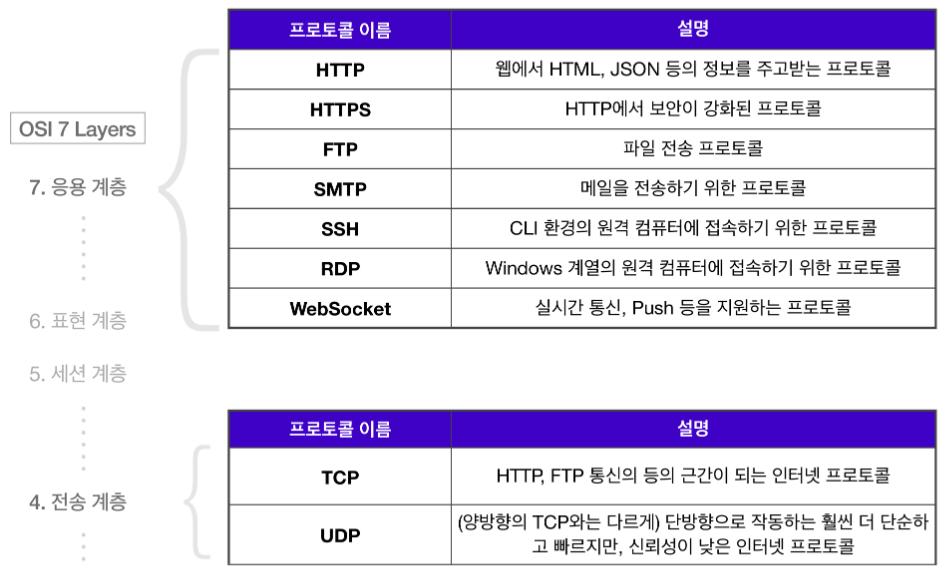
API(Application Programming Interface)
서버는 클라이언트에게 리소스를 잘 활용할 수 있도록 인터페이스(interface)를 제공해 줘야 한다.
- Interface : 의사소통이 가능하도록 만들어진 접점
- 다만 API는 앱이 요청할 수 있고 프로그래밍 가능한 인터페이스
- API는 주문 가능한 메뉴를 안내해주는 메뉴판과 같다. 이 메뉴판으로 클라이언트는 적절한 요청을 할 수 있다.
- 즉, 서버는 API를 구축해놓아야 클라이언트가 이를 활용할 수 있다.
- 보통 인터넷에 있는 데이터를 요청할 때에는 HTTP 프로토콜을 사용하고, 주소(URL, URI)를 통해 접근할 수 있게 된다.
HTTP API 요청 메서드
- GET : READ(조회)
- POST : CREATE(추가)
- PUT : UPDATE(갱신)
- PATCH : UPDATE(갱신)
- DELETE : DELETE(삭제)
- OPTIONS : -
Chapter2. 브라우저의 작동 원리 (보이지 않는 곳)
URL(Uniform Resource Locator)
네트워크 상에서 웹 페이지, 이미지, 동영상 등의 파일이 위치한 정보
- scheme : 통신 방식(프로토콜)을 결정함
- hosts :웹 서버의 이름이나 도메인, IP를 사용하며 주소를 나타냄
- url-path : 웹 서버에서 지정한 루트 디렉토리부터 시작하여 웹 페이지, 이미지, 동영상 등이 위치한 경로와 파일명을 나타냄
URI(Uniform Resource Identifier)
URL의 기본 요소인 scheme, hosts, url-path에 더해 query, bookmark를 포함한다.
- query : 웹 서버에 보내는 추가적인 질문
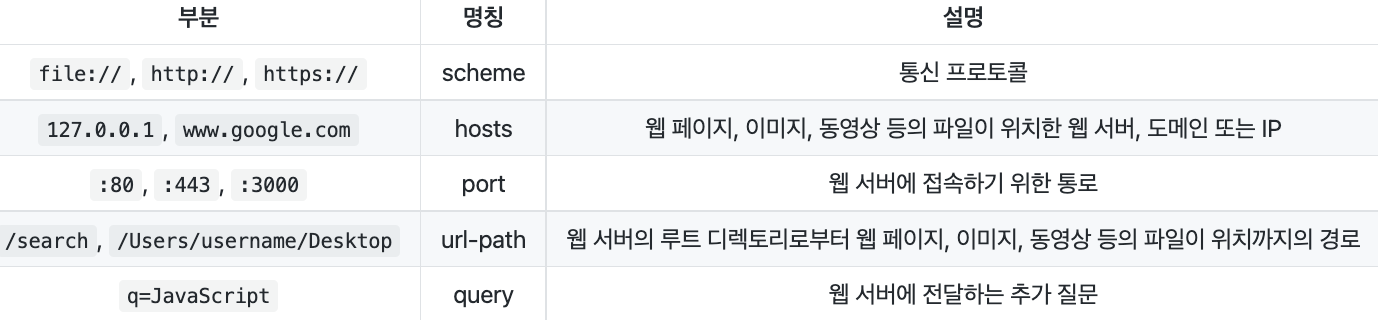
- 127.0.0.1 : 로컬 PC
- port :서버로 진입할 수 있는 통로
- URI는 URL을 포함하는 상위개념이다.
IP(Internet Protocol) 주소
인터넷상에서 사용하는 주소체계
네트워크 상에서 특정 PC를 나타내는 주소
localhost,127.0.0.1: 현재 사용 중인 로컬 PC를 지칭0.0.0.0,255.255.255.255: broadcast address, 로컬 네트워크에 접속된 모든 장치와 소통하는 주소. 서버에서 접근 가능 IP 주소를 broadcast address 로 지정하면, 모든 기기에서 서버에 접근 가능
PORT
IP주소에 진입할 수 있는 정해진 통로
- 이미 사용 중인 포트는 중복해서 사용할 수 없다
- 포트 번호는 0~ 65535 까지 사용할 수 있다
- 그중에서 0 ~ 1024번 까지의 포트 번호는 주요 통신을 위한 규약에 따라 이미 정해져 있음
- 22 : SSH
- 80 : HTTP
- 443: HTTPS
- 그중에서 0 ~ 1024번 까지의 포트 번호는 주요 통신을 위한 규약에 따라 이미 정해져 있음
Domain name
- 도메인 이름을 이용하면, 한눈에 파악하기 힘든 IP 주소를 보다 간단하게 나타낼 수 있다
- 터미널에서 도메인 이름을 통해 IP 주소를 확인하는 명령어
nslookup - 모든 IP 주소가 도메인 이름을 가지는 것은 아님
DNS(Domain Name System)
DNS는 호스트의 도메인 이름을 IP 주소로 변환하거나 반대의 경우를 수행할 수 있도록 개발된 데이터베이스 시스템
www.naver.com과 같은 도메인을 컴퓨터가 이해할 수 있는 IP 주소125.209.222.142로 변환하여 요청이 원하는 곳에 도달할 수 있도록 도와주는 시스템
-
브라우저의 검색창에 도메인 이름을 입력하여 해당 사이트로 이동하기 위해서는 해당 도메인 이름과 매칭된 IP 주소를 확인하는 작업이 반드시 필요한데,
-
네트워크에는 이것을 위한 서버인 DNS가 있음.
-
sub-domain.domain.TLD- 탑 레벨 도메인(TLD):
.com,.kr,.net등 오른쪽에 위치하는 도메인- 국가코드 도메인(kr,us 등)은 co, ac와 같은 2단계 도메인과 함께 사용되기도 함
- sub-domain:
www, m등 왼쪽에 위치하는 도메인- 웹 사이트의 특정 부분을 나눠서 보여줘야 하는 경우 사용함
- 탑 레벨 도메인(TLD):
-
도메인 서버(존) : 도메인을 관리
- Root 네임 서버 : 각 최상위 도메인 네임 서버들의 주소를 알고 있으며, 최상위 도메인 네임 서버는 권한 있는 네임 서버의 주소를 알고 있음
- TLD를 관리하는 네임 서버
- 권한 있는 네임 서버 :
example.com등의 도메인 IP 주소 및 도메인 정보를 관리하는 권한을 가진 서버
- 도메인 네임 서버는 하나의 서버로 구성되지 않으며, 안정성을 위해 최소한 두 개 이상의 서버가 하나의 도메인 네임을 담당함.
-
Zone File
- 도메인 네임 서버는 응답을 보내기 위해 한 개 이상의 존 파일을 가지고 있다.
- 이름과 레코드 클래스, TTL, 레코드 타입, 레코드 데이터로 구성된 레코드들로 구성
- 네임 서버들은 이러한 존 파일들을 바탕으로 요청에 해당되는 레코드를 리턴
리졸버는 이 레코드를 살펴보고 리턴해야 할 IP 혹은 다음에 쿼리를 진행할 서버의 주소를 확인
- 네임 서버들은 이러한 존 파일들을 바탕으로 요청에 해당되는 레코드를 리턴
크롬 브라우저 에러읽기
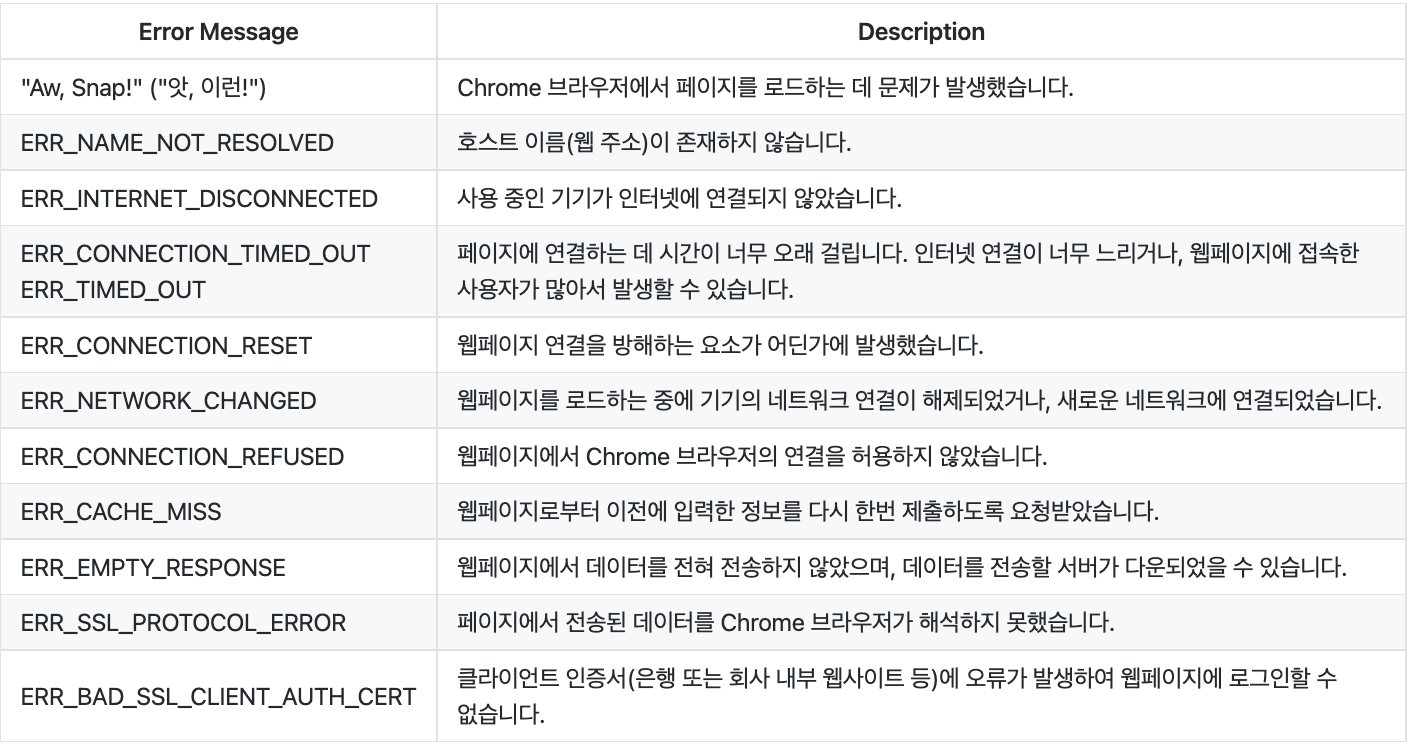
Chapter3. HTTP(HyperText Transfer Protocol)
HTML과 같은 문서를 전송하기 위한 프로토콜
HTTP는 웹 브라우저와 웹 서버의 소통을 위해 디자인되었다.
전통적인 클라이언트-서버 모델에서 클라이언트가 HTTP Messages 양식에 맞춰 요청을 보내면, 서버도 HTTP Messages 양식에 맞춰 응답한다.
📌 HTTP Messages
클라이언트와 서버 사이에서 데이터가 교환되는 방식
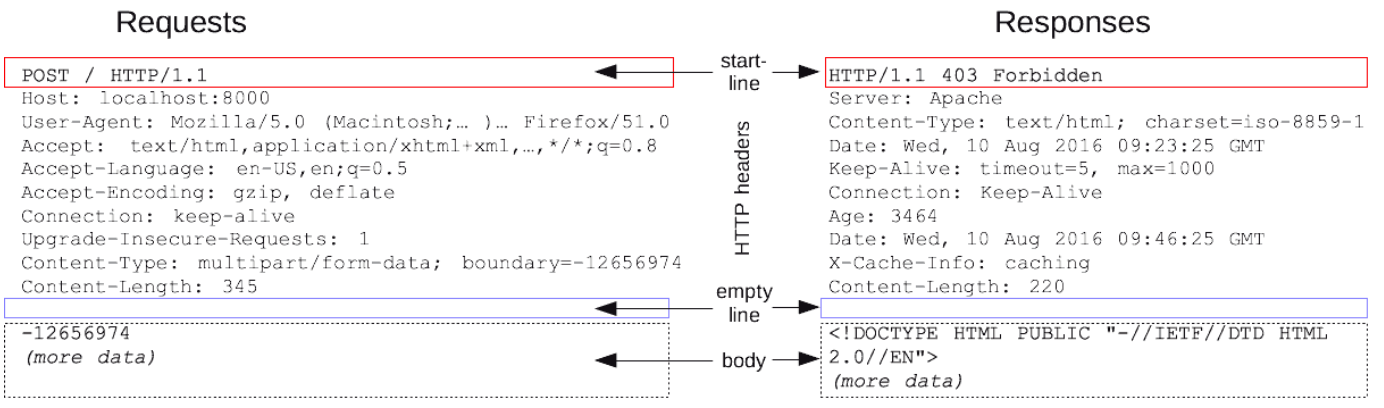
- 요청(Requests)과 2. 응답(Responses)은 비슷한 구조를 가짐.
Stateless 무상태성
- 클라이언트에서 발생한 모든 상태를 HTTP 통신이 추적하지 않는다.
- HTTP는 통신 규약일 뿐이므로, 상태를 저장하지 않는다.
📌 HTTP Requests
클라이언트가 서버에게 보내는 메시지
Start line에는 세 가지 요소가 있다.
1. Start line
1) HTTP method : 수행할 작업(GET, PUT, POST 등)이나 방식(HEAD or OPTIONS)을 설명
2) 요청 대상(일반적으로 URL이나 URI) 또는 프로토콜, 포트, 도메인의 절대 경로는 요청 컨텍스트에 작성
- origin 형식 :
'?'와 쿼리 문자열이 붙는 절대 경로로 GET, POST, HEAD, OPTIONS 등의 method와 함께 사용한다.POST / HTTP 1.1GET /background.png HTTP/1.0HEAD /test.html?query=alibaba HTTP/1.1OPTIONS /anypage.html HTTP/1.0
- absolute 형식 : 완전한 URL 형식으로, 프록시에 연결하는 경우 대부분 GET method와 함께 사용한다.
GET http://developer.mozilla.org/enUS/docs/Web/HTTP/Messages HTTP/1.1
- authority 형식 : 도메인 이름과 포트 번호로 이루어진 URL의 일부분. HTTP 터널을 구축하는 경우,
CONNECT와 함께 사용할 수 있다.CONNECT developer.mozilla.org:80 HTTP/1.1
- asterisk 형식 :
OPTIONS와 함께 별표(*) 하나로 서버 전체를 표현.OPTIONS * HTTP/1.1
2. Headers
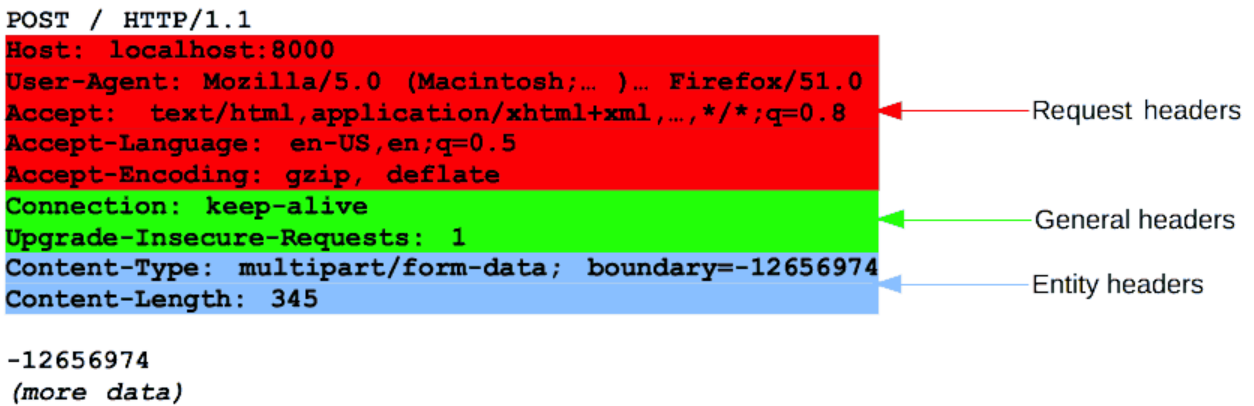
- General headers : 메시지 전체에 적용되는 헤더로, body를 통해 전송되는 데이터와는 관련이 없는 헤더
- Request headers : fetch를 통해 가져올 리소스나 클라이언트 자체에 대한 자세한 정보를 포함하는 헤더. User-Agent, Accept-Type, Accept-Language와 같은 헤더는 요청을 보다 구체화한다. Referer처럼 컨텍스트를 제공하거나 If-None과 같이 조건에 따라 제약을 추가할 수 있다.
- Representation headers : Entity headers로 불렀으며, body에 담긴 리소스의 정보(콘텐츠 길이, MIME 타입 등)를 포함하는 헤더
3. Body
-
요청의 본문은 HTTP messages 구조의 마지막에 위치한다.
-
모든 요청에 body가 필요한 건 아니다.
-
POST나 PUT과 같은 일부 요청은 데이터를 업데이트하기 위해 사용한다.
-
GET, HEAD, DELETE, OPTIONS처럼 서버에 리소스를 요청하는 경우에는 본문이 필요 X
- Single-resource bodies(단일-리소스 본문) : 헤더 두 개(Content-Type과 Content-Length)로 정의된 단일 파일
- Multiple-resource bodies(다중-리소스 본문) : 여러 파트로 구성된 본문에서는 각 파트마다 다른 정보를 지닌다. 보통 HTML form과 관련있음
📌 HTTP Responses
서버가 클라이언트에게 보내는 메시지
1. Start line (응답의 첫 줄)
HTTP/1.1 404 Not Found- 현재 프로토콜의 버전(HTTP/1.1)
- 상태 코드 - 요청의 결과 (ex. 200, 302, 404 등)
- 상태 텍스트 - 상태 코드에 대한 설명을 포함한다.
2. Headers
요청 헤더와 동일한 구조를 가지고 있다.
1. General headers : 메시지 전체에 적용되는 헤더로, body를 통해 전송되는 데이터와는 관련이 없는 헤더
2. Response headers : 위치 또는 서버 자체에 대한 정보(이름, 버전 등)와 같이 응답에 대한 부가적인 정보를 갖는 헤더로, Vary, Accept-Ranges와 같이 상태 줄에 넣기에는 공간이 부족했던 추가 정보를 제공.
3. Representation headers : Entity headers로 불렀으며, body에 담긴 리소스의 정보(콘텐츠 길이, MIME 타입 등)를 포함하는 헤더
3. Body
모든 응답에 body가 필요한 건 아니다.
- ingle-resource bodies(단일-리소스 본문) :
1) 길이를 알 경우 : 두 개의 헤더(Content-Type, Content-Length)로 정의한다.
2) 길이를 모를 경우 : Transfer-Encoding이chunked로 설정되어 있으며, 파일은 chunk로 나뉘어 인코딩되어 있다. - Multiple-resource bodies(다중-리소스 본문) : 서로 다른 정보를 담고 있는 body.
Chapter4. 브라우저의 작동 원리 (보이는 곳)
📌 AJAX(Asynchronous JavaScript And XMLHttpRequest)
JavaScript, DOM, Fetch, XMLHttpRequest, HTML 등의 다양한 기술을 사용하는 웹 개발 기법
AJAX의 가장 큰 특징은, 웹 페이지에 필요한 부분에 필요한 데이터만 비동기적으로 받아와 브라우저에 렌더링을 하는 것
2가지 핵심기술
1. JavaScript와 DOM
2. Fetch
- 페이지를 이동하지 않아도 서버로부터 필요한 데이터를 받아올 수 있다.
- JavaScript에서 DOM을 사용해 조작할 수 있기 때문에, Fetch를 통해 전체 페이지가 아닌 필요한 데이터만 가져와 DOM에 적용시켜 새로운 페이지로 이동하지 않고 기존 페이지에서 필요한 부분만 변경할 수 있다.
장단점
- 장점
- 서버에서 HTML을 완성하여 보내주지 않아도 웹페이지를 만들 수 있다.
- XHR이 표준화되면서부터 브라우저에 상관없이 AJAX를 사용할 수 있게 되었다
- 필요한 일부분만 렌더링하기 때문에 빠르고 더 많은 상호작용이 가능한 애플리케이션을 만들 수 있다.
- 필요한 데이터를 텍스트 형태(JSON, XML 등)로 보내면 되기 때문에 비교적 데이터의 크기가 작다.
- 단점
- Search Engine Optimization(SEO)에 불리
한 번 받은 HTML을 렌더링 한 후, 서버에서 비동기적으로 필요한 데이터를 가져와 그려내기 때문에 처음 받는 HTML 파일에는 데이터를 채우기 위한 틀만 작성되어 있는 경우가 많다 -> 뼈대만 있고 데이터는 없어서 사이트의 정보를 긁어가기 어려움 - 뒤로가기 버튼 문제
이전 상태를 기억하지 않기 때문에 사용자가 의도한 대로 동작X
- Search Engine Optimization(SEO)에 불리
📌 SSR(Server Side Rendering) vs CSR(Client Side Rendering)
주요 차이점 : 페이지가 렌더링되는 위치
- SSR : 웹 페이지를 브라우저에서 렌더링하는 대신 서버에서 페이지를 렌더링한다.
- CSR : 브라우저(클라이언트)에서 페이지를 렌더링한다. 사용자가 다른 경로를 요청할 때마다 페이지를 새로고침 하지 않고, 동적으로 라우팅을 관리한다.
SSR 사용
- SEO(Search Engine Optimization) 가 우선순위인 경우
- 웹 페이지의 첫 화면 렌더링이 빠르게 필요한 경우
- 웹 페이지가 사용자와 상호작용이 적은 경우
CSR 사용
- SEO 가 우선순위가 아닌 경우
- 사이트에 풍부한 상호 작용이 있는 경우, CSR 은 빠른 라우팅으로 강력한 사용자 경험을 제공한다.
- 웹 애플리케이션을 제작하는 경우, CSR을 빠른 동적 렌더링을 제공할 수 있다.
+)
URI
https://www.google.com/search?q=codestates
- 통신 프로토콜로 https를 사용하고 있기 때문에 port 번호는 443이다.
- 해당 URI는 scheme, hosts, url-path, query로 구성됨
- url-path는 /search이다.
- query는 ?q=codestates이다.
씨 뿌리는 과정......
