릿지와 라쏘는 선형회귀 모델의 과적합 방지를 위해 사용한다. 두 모델은 규제를 가하는 방법이 조금 다른데, 뭐 맥락은 같다. 바로 계수의 크기를 줄이는 것이다. 일반적으로 릿지를 조금 더 선호한다고 함.
릿지와 라쏘 모델을 사용할 때, 규제의 양을 임의로 조절할 수 있다. 모델 객체를 만들 때 alpha 매개변수로 규제의 강도를 조절한다. alpha값이 크면 규제 강도가 세지므로 계수 값을 더 줄이고 조금 더 과소적합되도록 유도한다. alpha값이 작으면 계수를 줄이는 역할이 줄어들고 선형회귀 모델과 유사해지므로 과대적합될 가능성이 크다.
사람이 직접 정해야 하는 매개변수
alpha 값은 릿지 모델이 학습하는 값이 아니라 사전에 사람이 지정해야 하는 값이다. 이렇게 머신러닝 모델이 학습할 수 없고 사람이 알려줘야하는 파라미터를 하이퍼파라미터 라고 부른다.
적절한 alpha 값을 찾는 한가지 방법은 alpha값에 대한 R^2 값의 그래프를 그려보는 것이다. 훈련세트와 테스트세트의 점수가 가장 가까운 지점이 최적의 alpha값이 된다.
아래 코드는 alpha값을 0.001에서 100까지 10배씩 늘려가며 릿지 회귀 모델을 훈련한 다음 훈련세트와 테스트 세트의 점수를 파이썬 리스트에 저장한다.
import matplotlib.pyplot as plt
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
# 릿지 모델을 만든다
ridge = Ridge(alpha=alpha)
ridge.fit(train_scaled, train_target)
# 훈련 점수와 테스트 점수를 저장한다
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()이제 그래프를 그려보자. alpha 값을 0.001부터 10배씩 늘렸기 때문에 이대로 그래프를 그리면 왼쪽이 너무 촘촘해진다. alpha_list 에 있는 6개의 값을 동일한 간격으로 나타내기 위해 로그함수로 바꾸어 지수로 표현하겠다.
즉 0.001은 -3, 0.01은 -2가 되는 식이다.
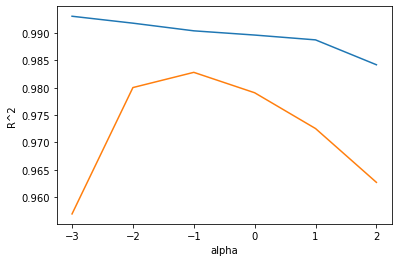
위는 훈련그래프, 아래는 테스트 세트 그래프이다. 이 그래프의 왼쪽을 보면 훈련세트와 테스트 세트 점수의 차이가 아주 크다. 훈련세트에는 잘 맞고 테스트 세트에는 형편없는 과대적합의 전형적인 모습이다. 반대로 오른쪽 부분은 훈련세트와 테스트세트의 점수가 모두 낮아지는 과소적합으로 가는 모습을 보인다.
적절한 alpha값은 두 그래프가 가장 가깝고 테스트 세트의 점수가 가장 높은 -1, 즉 10^-1 즉 0.1이다.
alpha값을 0.1로 하여 최종 모델을 훈련하겠다!!!
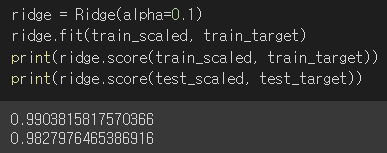
이 모델은 훈련세트와 테스트 세트의 점수가 비슷하게 모두 높고, 과대적합과 과소적합 사이에서 균형을 맞추고 있다!
