코로나 데이터 시각화해서 사이트 만들기
이번에 시작하는 프로젝트는 코로나 데이터를 시각화하는 프로젝트이다. 예전부터 데이터 사이언스쪽에 관심있었는데 니코가 잘 정리해서 강의로 만들었다. css / python 챌린지를 깨면 공짜로 들을 수 있는 강의인데 사실 이 강의들으려고 챌린지 했을 정도이다.
결과물을 먼저 봤는데 상당히 세련됐다. react로 만든것 같은데 plotly라는 라이브러리로 매우 쉽게 구현가능하다. 굉장히 설렌다. 우선 데이터를 시각화하기 전에 필요한 라이브러리와 프레임워크 그리고 데이터를 다운받자. 참고로 이번 프로젝트에서는 html/css/javascript를 사용하지 않고 오로지 dash/plotly/pandas 만을 가지고 코로나 웹사이트를 만들 수 있다.
데이터 다운받기
우선 내가 참고할 데이터를 불러와야한다.
위의 링크를 들어가보면 존스홉킨스에서 전세계, 미국 코로나 데이터 시각화 자료를 볼 수 있다. 게다가 데이터를 csv 형태로 다운 받을 수 있다. 밑에 downlodable - github을 클릭해서 들어가면된다.
전세계 확진자 현황
여기서 전세계국가의 확진자,사망자,회복자,격리해제자를 날짜별로 모아놓았다. 세가지 csv 파일을 다운받자
일간보고
여기는 2월부터 오늘까지 확진,사망,격리해제된 사람들의 총합을 날짜별로 업데이트해서 올려놓았다. 오늘 날짜의 csv 를 다운받자. 그리고 4개의 csv파일을 data폴더에 저장하자.
pandas/ dash/ plotly/ jupyter notebook 다운받기
pandas는 csv파일에 담긴 데이터를 획기적으로 쉬운 방법으로 가공할 수 있는 파이썬 라이브러리다
pip install pandas 터미널에 입력해서 pandas를 다운받자.
dash는 flask를 기반한 프레임워크인데 그래픽 라이브러리로 유명한 plotly와 같이 쓰인다.
pip install dash==1.18.1 pip install plotly 를 입력해서 dash와 plotly를 다운받자.
그리고 이번엔 jupyter notebook을 다운받을 건데, 이 노트북은 로컬서버에서 열리는 소프트웨어인데 데이터 사이언스에서 많이 사용하며 데이터를 가공하고 난 뒤의 결과를 바로바로 확인할 수 있다.
pip install jupyter 를 입력하고 jupyter notebook을 입력하면 열린다. 근데 나는 경로를 알 수 없다는 오류가 떠서 anaconda 사이트에서 anaconda를 받고 그 안에 들어있는 jupyter notebook을 따로 설치했다.
pandas로 데이터 가공하기.
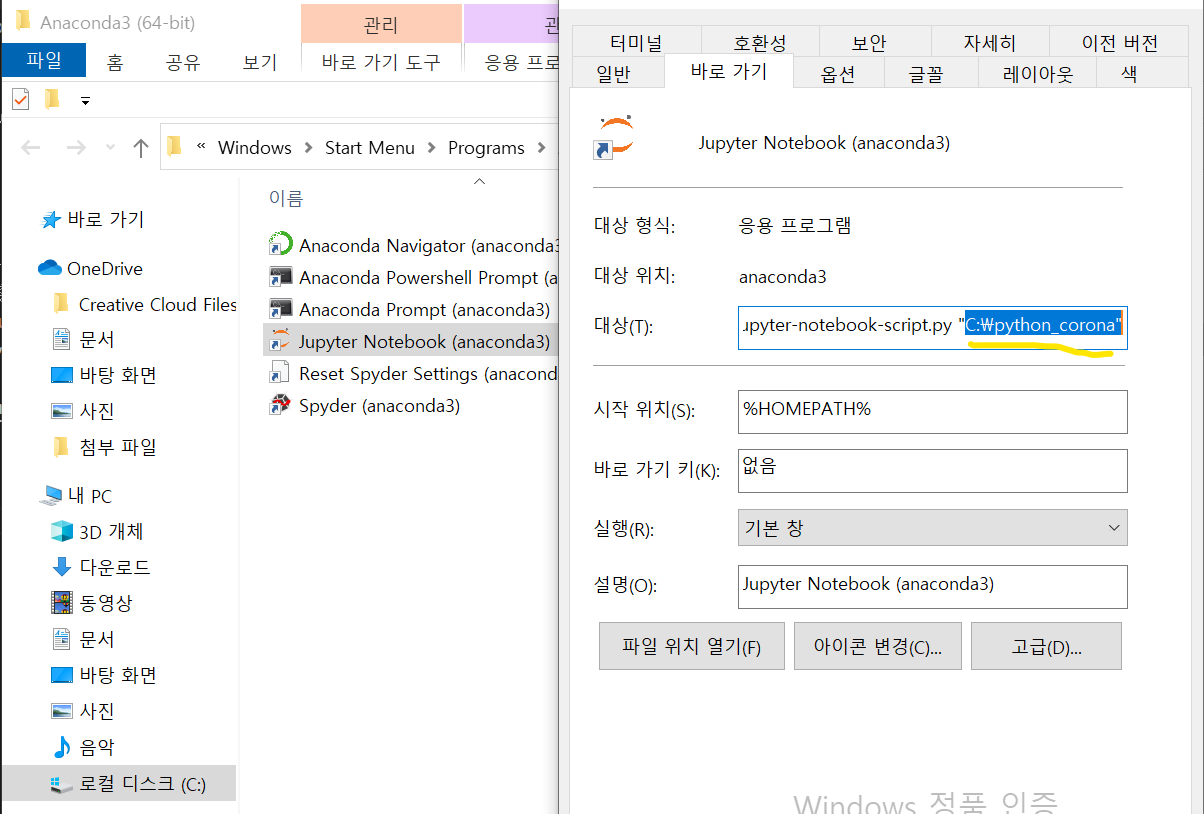
그럼 세팅은 완료했다. 이제 jupyter를 키고 간단하게 다운받은 데이터를 정리해보자. 로컬서버가 열리면서 jupyter notebook을 볼 수 있는데 이때 프로젝트를 실행하려는 폴더가 아닌 다른 폴더가 열린다면 간단하게 시작경로를 수정할 수 있다. notebook의 오른쪽 마우스를 클릭해서 속성을 누른뒤에
대상 맨뒤에 기존 경로를 지우고 원하는 폴더의 경로를 입력하면 된다.
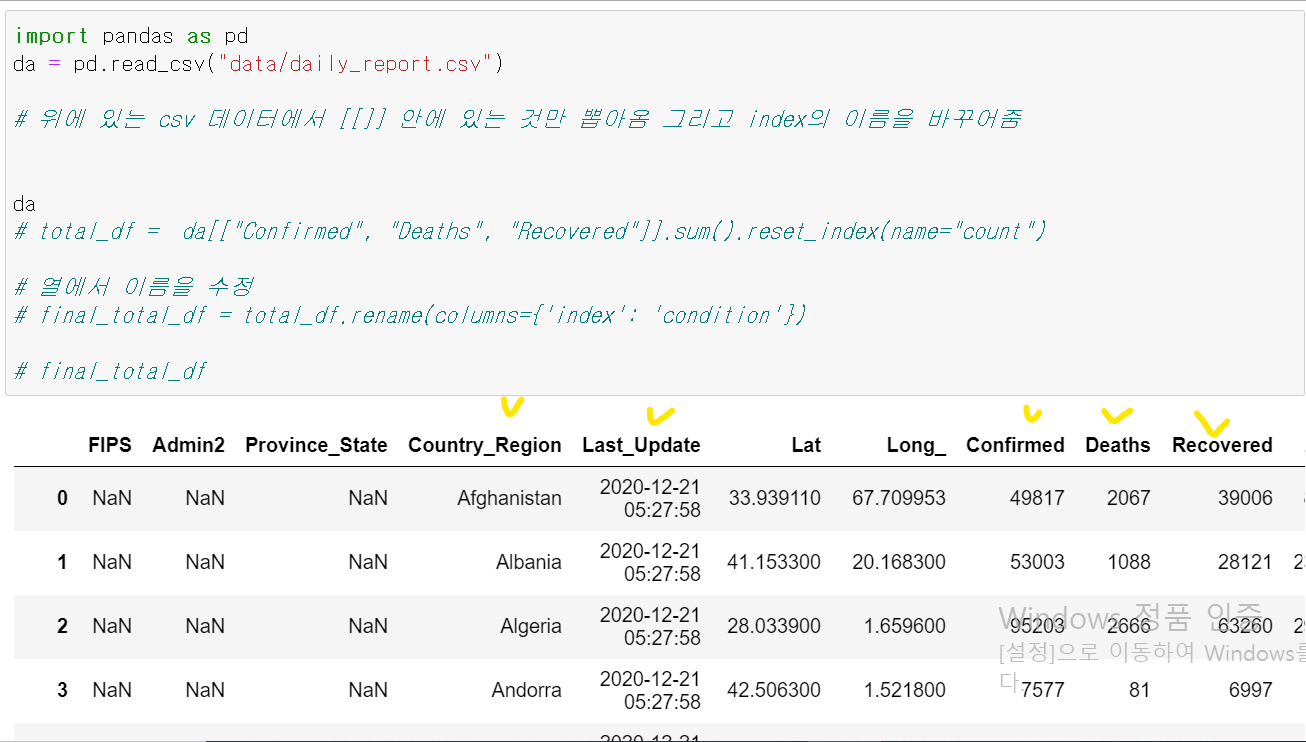
그리고 notebook으로 다시 돌아와서 new를 클릭하여 새로운 파일을 연다음에 거기서 데이터를 가공하고자 한다. 그럼 오늘하루동안 파악된 전세계의 모든 국가의 확진자,사망자,격리해제를 파악하고 그 숫자를 다 더해서 오늘 전세계 코로나 데이터를 보고자 한다.
아래와 같이 입력해보자.
# 1. 데이터의 합을 뽑아내기
import pandas as pd
da = pd.read_csv("data/daily_report.csv")
# 위에 있는 csv 데이터에서 [[]] 안에 있는 것만 뽑아옴 그리고 index의 이름을 바꾸어줌. 오늘 하루 발생한 데이터를 전부 합하고 table 형태로 만든다.
total_df = da[["Confirmed", "Deaths", "Recovered"]].sum().reset_index(name="count")
# 열에서 이름을 수정
final_total_df = total_df.rename(columns={'index': 'condition'})
# 유치원생도 할 수 있을 정도로 간단함. python으로 할라고 했으면 3줄의 코드로는 절대 불가능
그리고 ctrl+enter를 누르면 바로 결과를 확인 할 수 있다.
이런 결과를 얻으려면 적어도 10줄이상은 있어야 할 것인데 pandas 라이브러리를 사용하니깐 고작 4,5줄로 데이터를 가공할 수 있다.