EDF
Processor가 absolute deadline이 제일 작은 task에게 priority 우선권을 부여하는 알고리즘입니다.
만 보장된다면 schedulable함 역시 보장됩니다!
EDF는 모든 알고리즘에 대해 optimal한데요.
조건이 좀 붙습니다.
- Preemptive
- No context switch overhead
- Uniprocessor
이것만 만족하면 됩니다.
Why is EDF optimal?
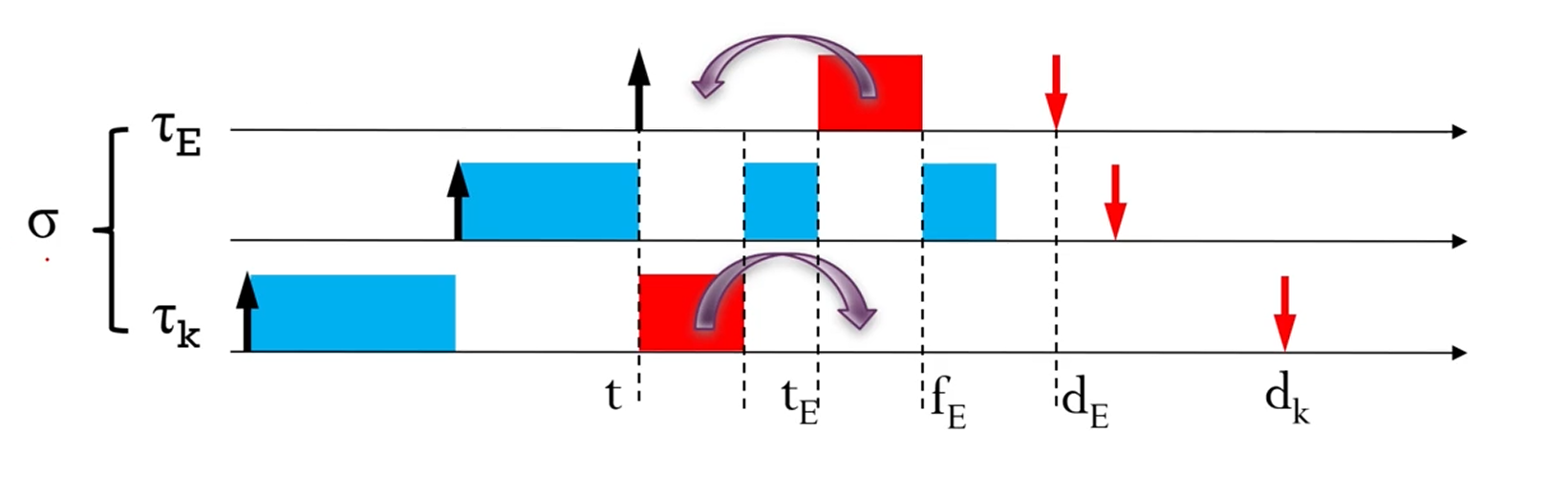
지금의 경우에는 가 earliest deadline task를 갖고 있죠.
이때, 가 다른 job보다 늦게 execute되었다고 칩시다.
지금같은 edf violation이 일어났다면,
간단히 저 빨간 덩어리 두개의 위치를 swap해주기만 하면 되겠죠.
계속 swap하고 swap해서 edf가 될때까지 가면 돼요.
EDF Feasibility Condition when T = D
이것도Liu랑 Layland인데요.
이 두 분께서 임을 밝혔습니다.
U > 1.0이 경우엔 아무도 feasible task set을 만들 수 없기에,
T=D condition에서는 EDF가 optimal함을 밝혔죠.
EDF Feasibility condition proof
이라면 는 schedulable하다.
EDF의 Feasibility condition이죠?
이거 증명해봅시다.
증명을 위해서는,
인데 가 unschedulable한 상황을 가정합니다.
그렇게 가정햇더니, 가 1.0보다 크더라.
이런 느낌의 귀류법으로 증명을 하면 됩니다.
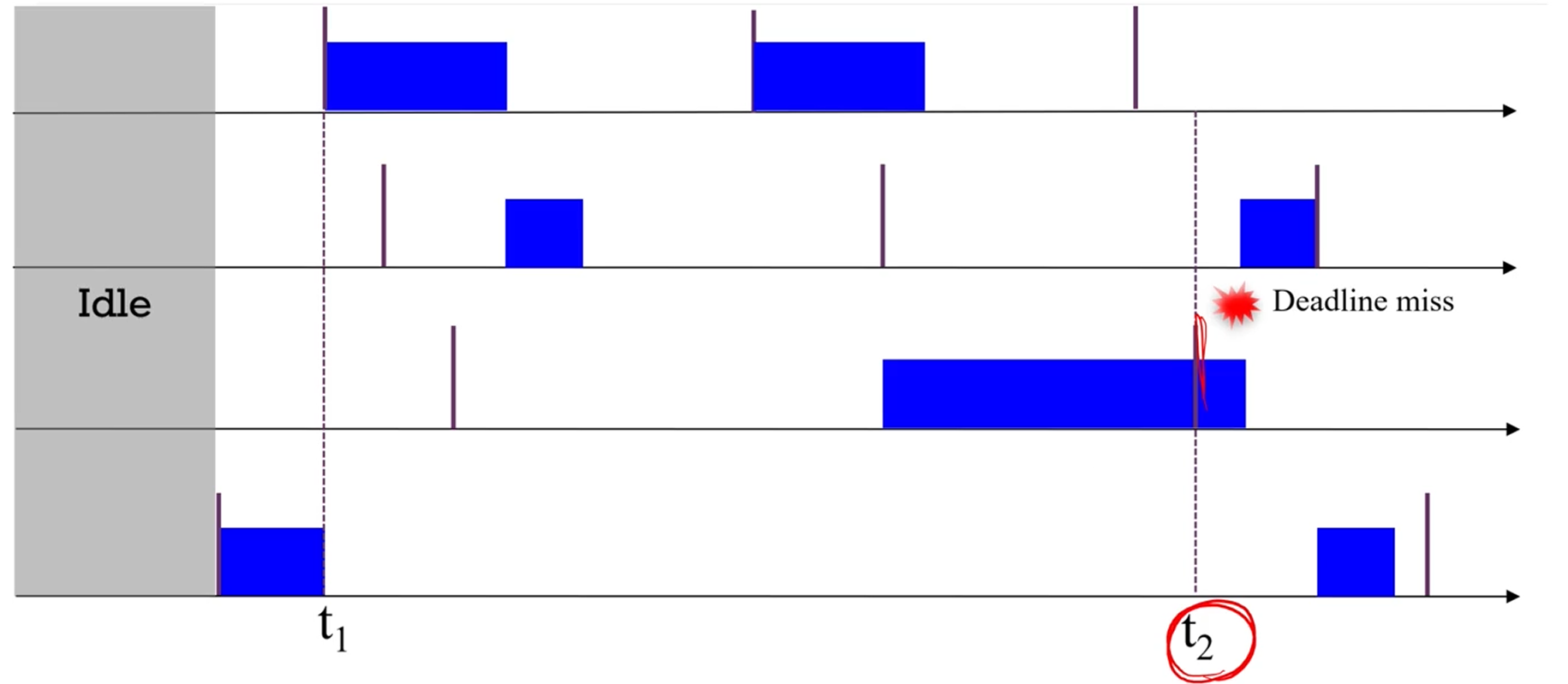
처음으로 deadline miss가 감지된 시간대를 라고 합시다.
그리고, 보다 deadline이 작은 애들만 실행이 되어 온
가장 긴 continuous utilization interval을 로 잡습니다.
즉, 범위에서는 모든 job이 보다 deadline이 작습니다.
그 에서의 총 demand를 라고 합시다.
멍청하게는 그냥 보이는 파란색 다 더하면 되고,
수학적으로는
가 되구요.
이 값은
보다는 작거나 같겠죠?
여기서, deadline miss가 일어났다는 가정을 했으니,
이 성립합니다.
즉, 저 시간 interval보다 요구되는 demand량이 컸다는 거죠.
근데 방금 구한 식을 집어 넣으면,
가 성립하구요.
정리하면 가 나옵니다.
모순이네요.
귀류법에 의해서, EDF는 U가 1.0 이하면 모든 task set을 schedulable하게 한다.
이게 증명되었습니다.
Is EDF Only Optimal?
No!
Proportional Share Algorithm도 optimal합니다.
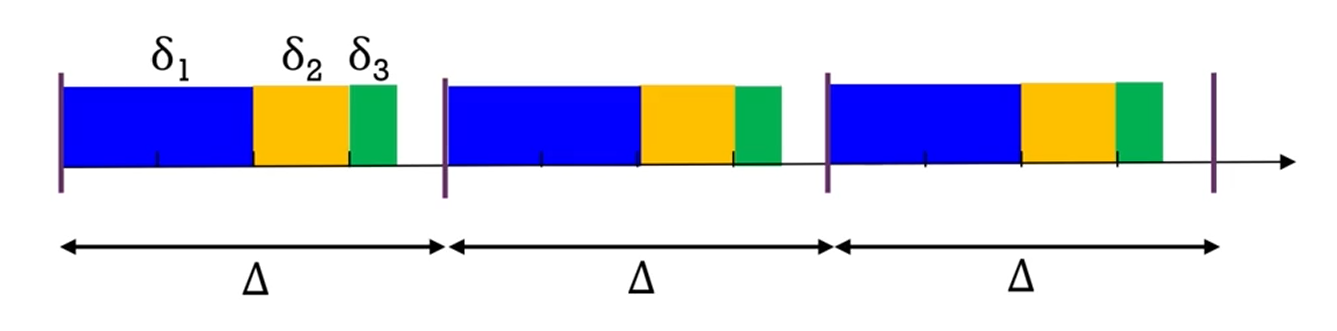
short interval 를 LCM of periods로 잡고,
를 Utilization에 비례하게 제공하는 알고리즘이었죠.
문제점은, 가 매우 작아지면 split이 안된다는 점이었습니다.
하지만, 그래도 '쪼갤 수 있는 단위'까지 가 커버해준다면, Optimal하죠.
그래서, 만약 이론적으로 infinitely small 가 가능하다면,
이 알고리즘은 optimal합니다.
즉, 'quantum이 무한히 작아질 수만 있다면'
인 condition에서 optimal하다는 거죠.
EDF with D <= T
인 경우에도 optimal하긴 한데,
조금 증명 방법이 다릅니다.
'Processor Demand Criterion'이라는게 있는데,
어떻게 길이 L을 잡아도,
computational demand g(0,L)은 L 이하여야 합니다.
앞서 EDF의 인 경우 optimality를 증명할 때 computational demand라는 개념을 썼죠.
다시 등장합니다.
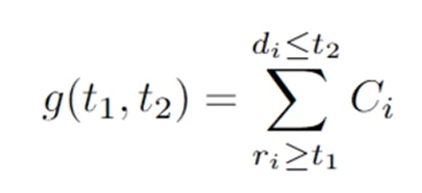
0 ~ L 사이의 computational demand에 대한 공식은 다음과 같습니다.
이 조건을 모든 L에 대해 살펴봐야 한다는건데,
사실 그게 말이 안되거든요
비록 이 step function이라서 같은 deadline point에서만 살펴봐도 되지만,
그래도 많아요. 애초에 L이 엄청 길면 어떻게 해요.
그래서, task가 동시에 시작하며, U < 1.0이라면, (등호 없어야 함)
feasibility check는 까지만 살펴봐도 됩니다.
그 값을 Hyperperiod H라고 합니다.
Summary
이렇게 Analysis technique를 총 3개 살펴봤습니다.
Utilization bound, (RM이나 T=D EDF에서 쓰였습니다)
Response Time Analysis, (Fixed Priority인 경우, RM과 DM에서 쓰였습니다)
Processor Demand Criterion (D <= T EDF에서 쓰였습니다)
이 3가지 technique를 이용해 계산만 해주면,
실제로 무한히 돌려보지 않고도
'아, task set이 schedulable하구나.'를 체크할 수 있게 돼요.
Complexity Issues
Utilization based analysis는 의 complexity를 가집니다.
n개의 task에 대해 utilization의 합을 구해야 하니까요.
Response-time Analysis의 경우,
Pseudo-Polynomial complexity를 가집니다.
가 매개변수로 쓰였죠.
Processor Demand Criterion도 같습니다. pseudo-polynomial complexity를 가집니다.
RM vs EDF
- Context Switches
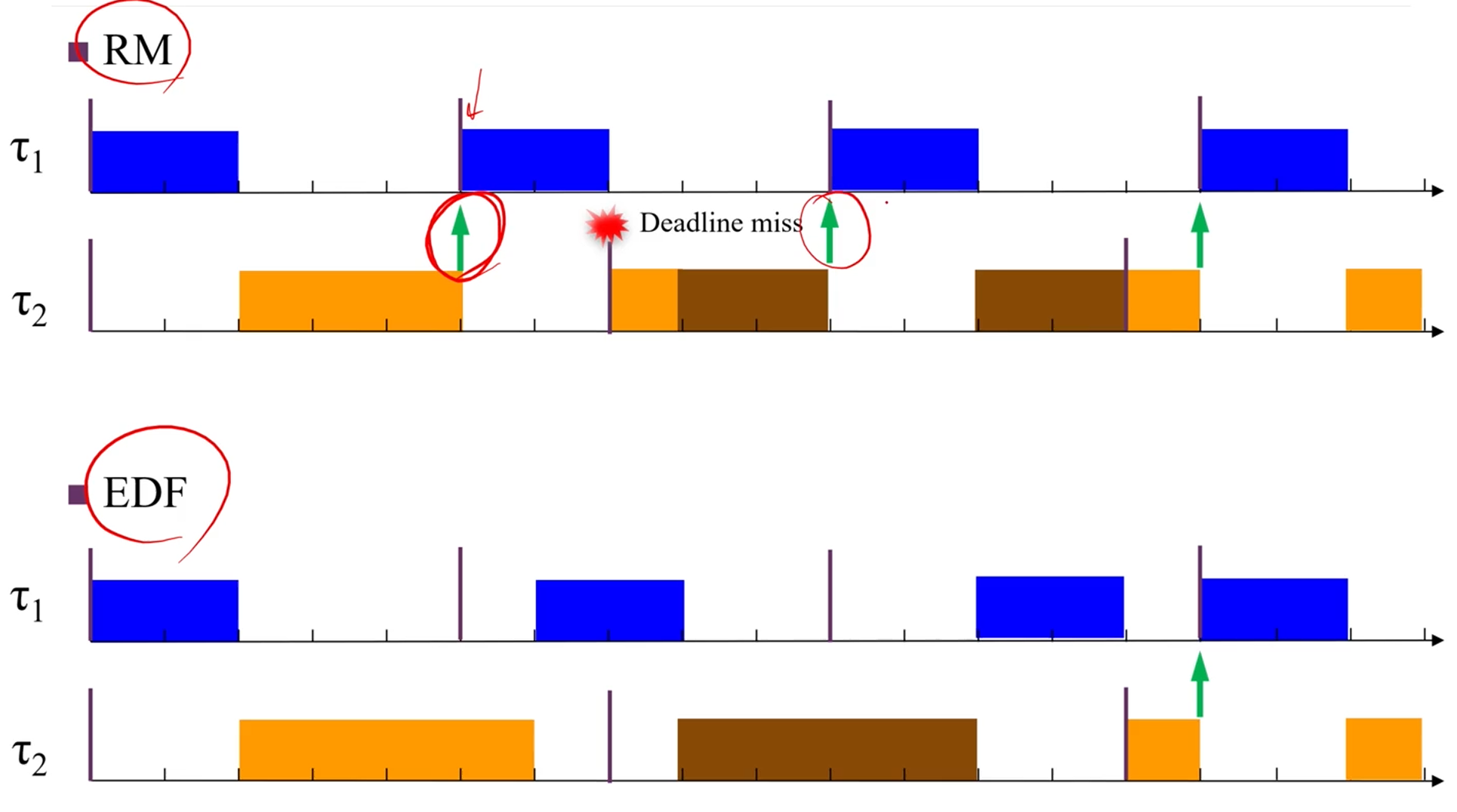
RM에서 task 1은 죽을때까지 high-priority입니다.
EDF에선 priority가 변하죠.
그래서 그런지, RM이 Preemption (Context switch)가 더 많네요.
EDF 승!
- Schedulability Analysis
RM은 Utilization based analysis와 response time analysis를 썼고,
EDF는 Utilization based analysis와 demand based analysis를 썼습니다.
+ RM의 강점 하나.
RM은 Harmonic task set의 경우 RM에 의해 schedule이 가능한데요,
이어야 합니다.
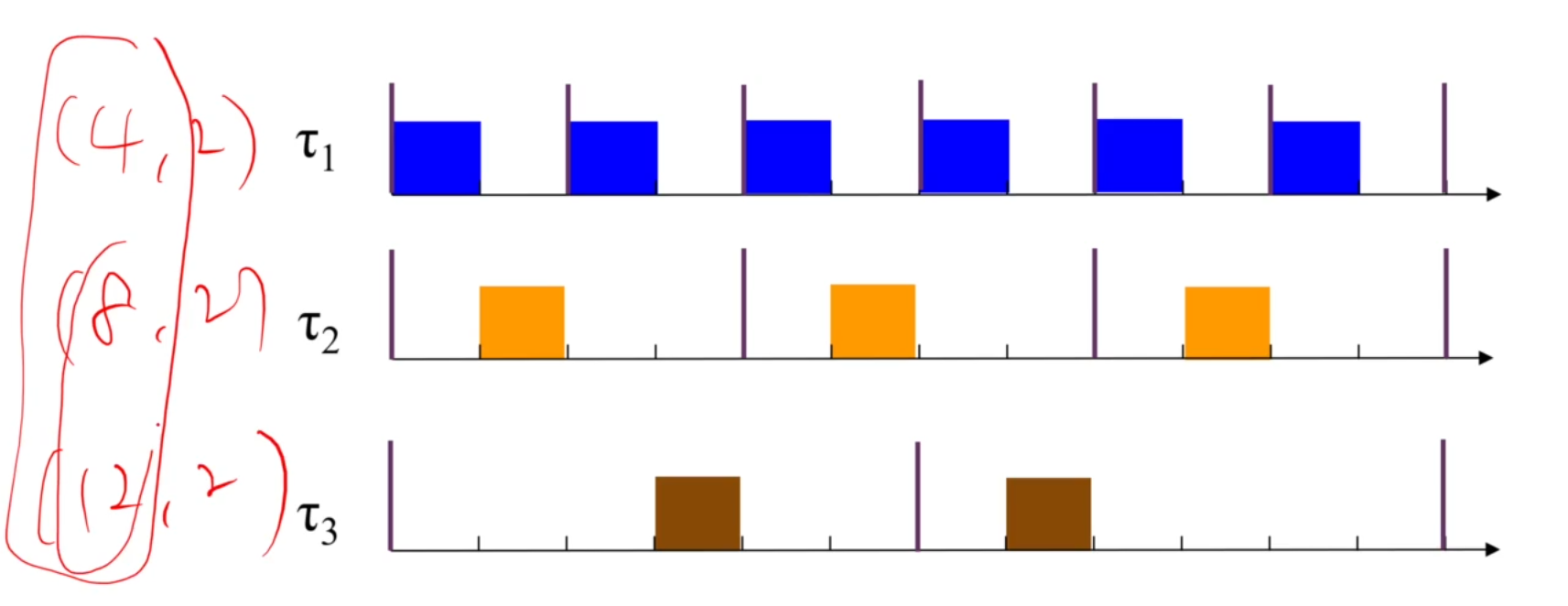
지금의 경우는 Non-harmonic한데요.
upper bound입니다. C가 조금만 커져도 unschedulable해져요.
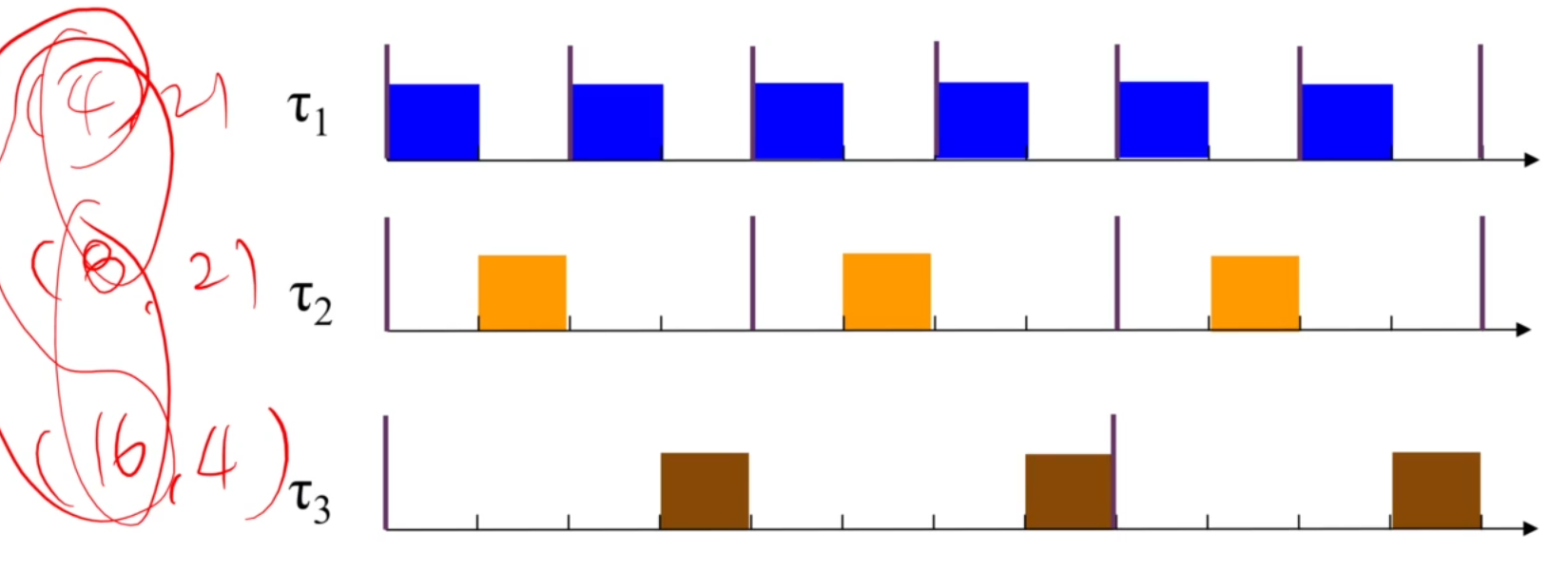
조화롭죠. RM으로 schedulable하면 U <= 1.0 이기에 무조건 schedulable하고 upper bound가 1.0이 됩니다
- Overload
Permanent Overload ( U > 1.0 )의 경우,
뭐 schedulability는 볼것도 없죠. 불가능합니다. (RM)
높은 priority의 task는 잘 실행되어도,
낮은 priority의 task는 completely blocked 됩니다.
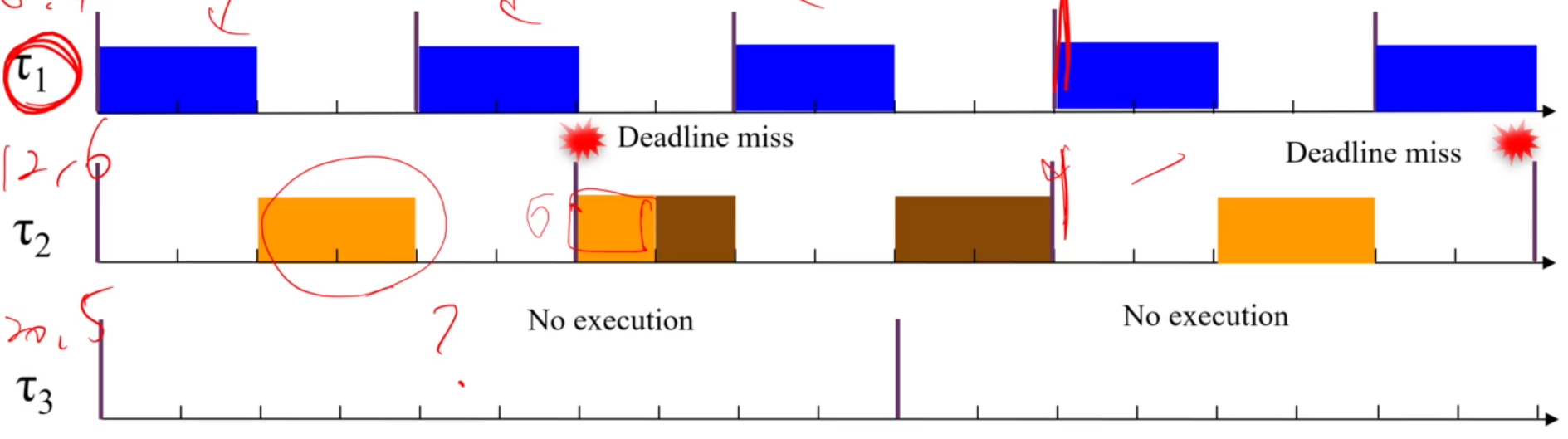
EDF에서는, block되는 task는 없구요,
deadline miss가 다닥다닥 일어나도 느리게라도 실행은 됩니다.
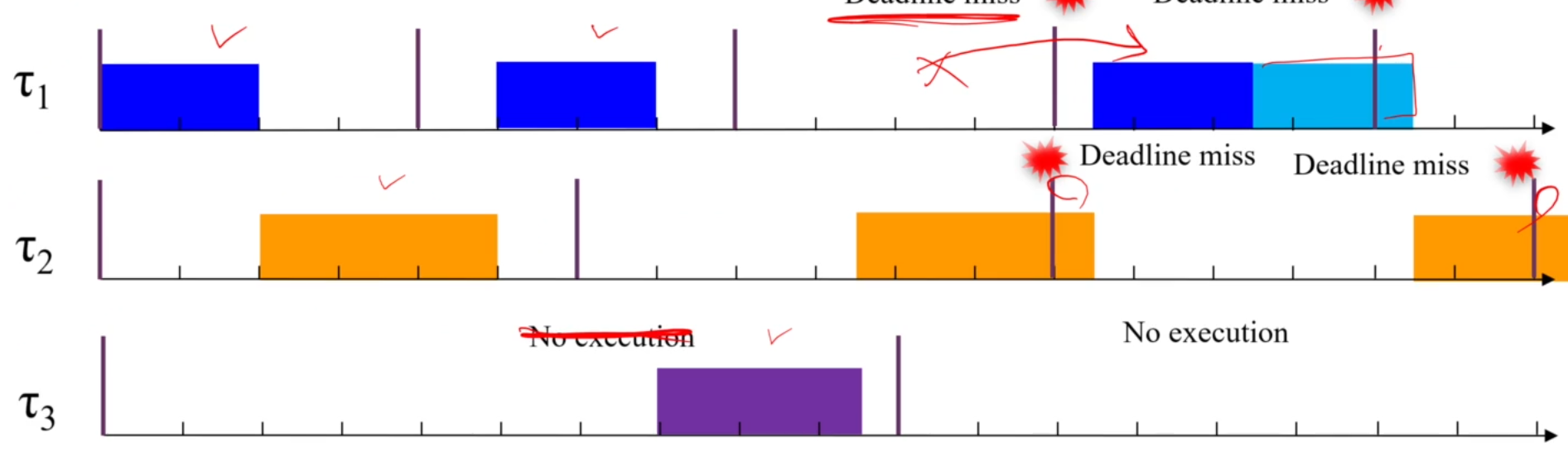
EDF의 permanent overload 상황에서의 특징이 있습니다.
실행되는 task를 거국적으로 쭉 바라보면,
마치 Task의 period가 가 아닌 가 된 효과가 납니다.
U = 1.25고, 면 인것처럼 스케줄이 일어난다는거죠.
가끔 overload가 일어나는 Transient Overload에서는,
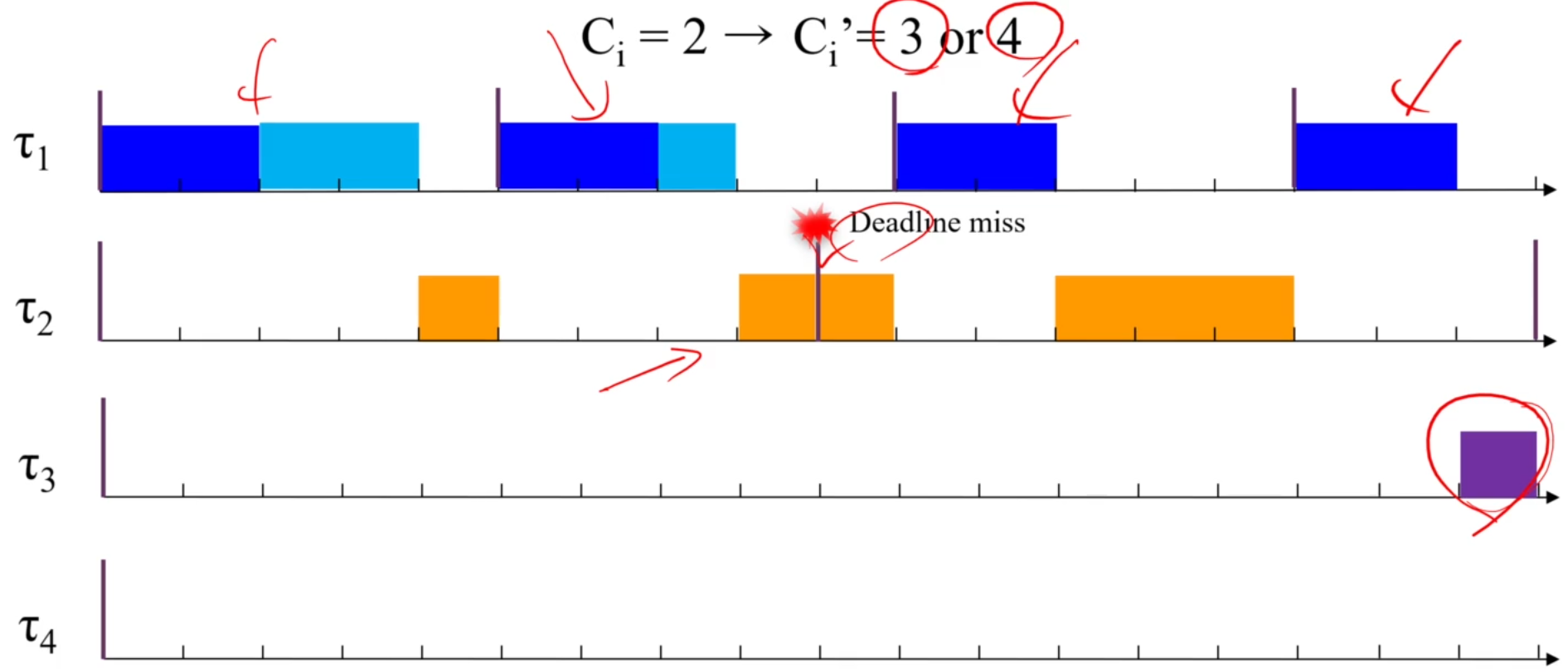
항상 lower priority task만 손해를 보는 구조는 아니게 됩니다!
잘 보면, t3은 잘 되어도 t2에서 deadline miss가 났죠.
뭐,
결론만 압시다.

