First return, then explore (Go-Explore) 논문 요약
소개
이 논문의 초기 버전은 Go-Explore: a New Approach for Hard-Exploration Problems으로, 2019년 1월 30일에 나왔다. 차기 버전인 First return, then explore는 nature에 2021년 2월 24일 publish 되었다. 이 포스트에서 설명은 First return, then explore를 기준으로 설명하겠다.
강화 학습 알고리즘은 자주, simple and intuitive rewards가 sparse and deceptive feedback을 제공할 때 어려움을 겪는다. 이러한 문제를 피하기 위해 environment를 철저하게 exploring 할 것이 요구된다. 이 논문에서는 효과적인 exploration에 대한 주요한 장애물이, 이전에 도달한 states에 도달하는 방법을 잊어버리고(detachment), 어떤 state로부터 탐색하기 전에 그 state로 돌아가는 데 실패하는 것(derailment)이라고 가정한다.
- detachment: 이전에 방문했던 states에 도달하는 방법을 잊어버리는 것.
- derailment: 어떤 state로부터 탐색하기 전에 해당 state로 먼저 return 하는 데 실패하는 것.
Detachment를 피하기 위해, Go-Explore는 environment에서 방문한 서로 다른 states의 archive를 만들어서 states가 잊혀지지 않도록 보장한다.
이전 RL 알고리즘들은 exploring으로부터 returning을 분리하지 않았다. 대신 보통 일정 비율만큼 random actions를 추가하거나, stochastic policy로부터 sampling 하면서 episode에 걸쳐 exploration을 섞었다. 반면에, Go-Explore는 exploring을 하기 전에 먼저 returning을 하면서, return policy에서 exploration을 최소화함으로써 derailment를 피한 다음, 순수한 exploratory policy로 전환한다.
Cell
실제로, non-trivial environments는 저장하기에 너무 많은 states를 가지고 있다. 이러한 이슈를 해결하기 위해 비슷한 states를 cells로 grouping 한다. 그리고 states는 오직 그 archive에 아직 존재하지 않는 cell에 있을 때 novel 한 것으로 생각한다. 만약 한 state가 이미 알려진 cell에 mapping 되지만 더 나은 trajectory와 연관된다면 그 state와 이와 연관된 trajectory는 현재 그 cell과 연관된 state와 trajectory를 대체한다.
Overview of Go-Explore
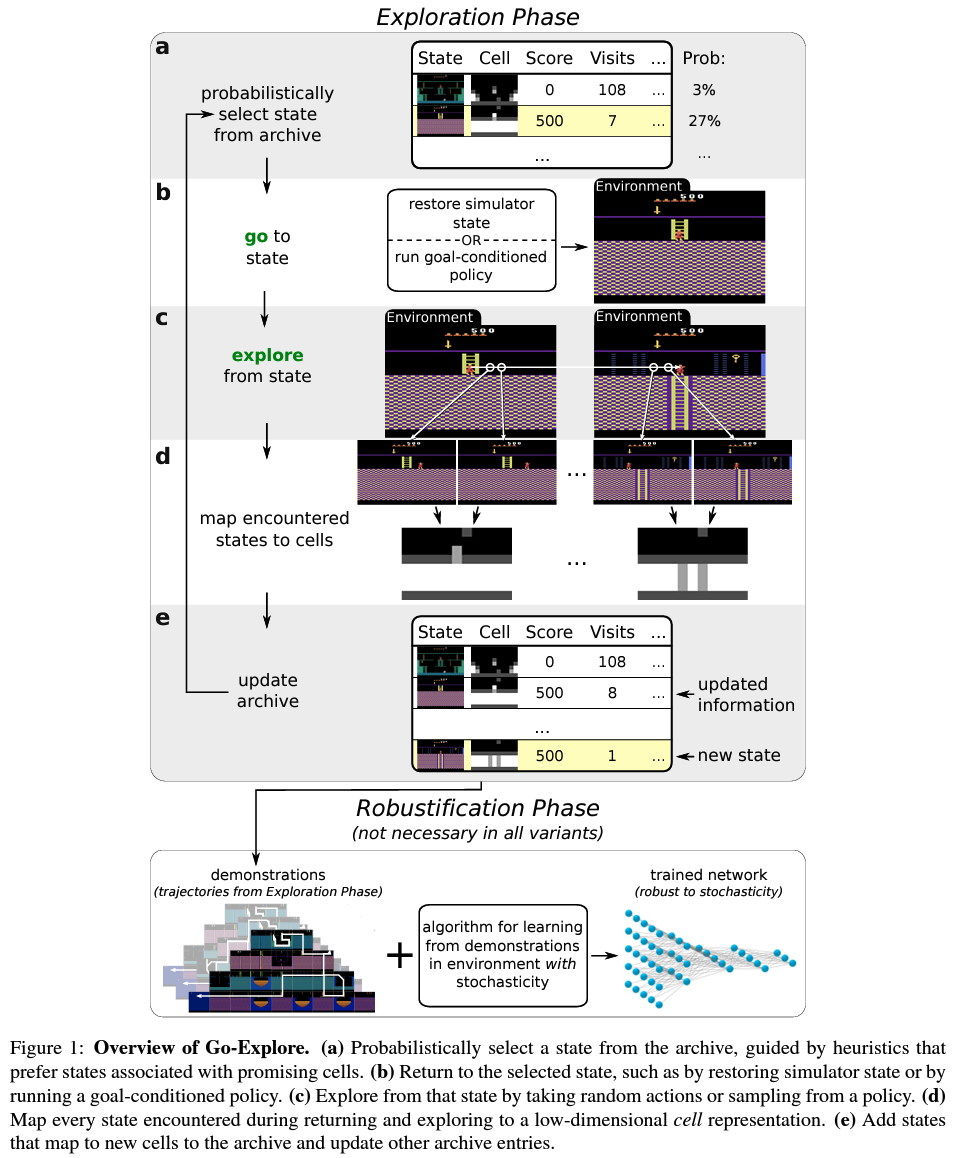
Exploration phase
a. Archive에서, 돌아 갈 state를 확률적으로 선택한다.
b. 해당 state로 돌아간다.
c. 해당 state로부터 탐색한다.
d. 방문한 states를 cells로 map 한다.
e. Archive를 update 한다.
Robustification Phase
Go-Explore는 exploration phase 동안 계속해서 states 중 한 곳으로 restore한다. 그것은 highest-scoring trajectory (sequence of actions)를 복원한다는 건데, 그러한 trajectory는 environment의 stochasticity나 unexpected outcomes에 robust 하지 않다 (예를 들어, 로봇이 미끄러지거나 중요한 turn을 miss하는 경우 entire trajectory를 쓸모없이 만들어버린다).
이러한 문제를 해결하기 위해 Go-Explore는 Exploration phase가 끝난 후 모은 trajectories를 Learning from Demonstrations (LFD)을 이용해 robust policy를 학습한다.
Atari game에서 robustification phase는 backward algorithm의 수정된 버전으로 구성된다. 이는 Montezuma's Revenge의 가장 높은 성능을 내는 LFD 알고리즘이다.
실험
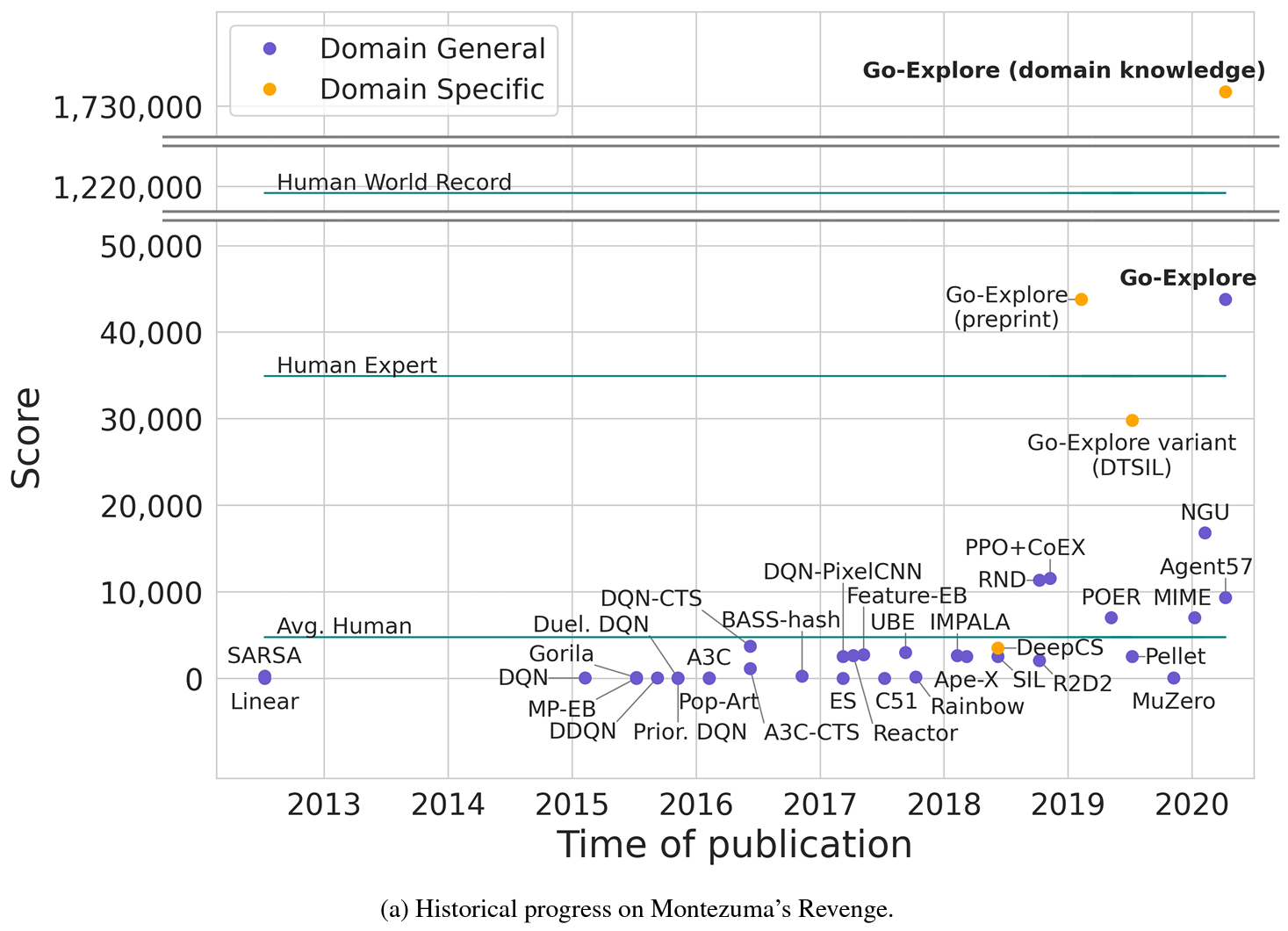
아래는 Atari game 중 hard-exploration game에 해당하는 Montezuma's Revenge의 score이다. Go-Explore는 돋보이는 성능을 보여준다.
A Hard-exploration robotics environment
