Never Give Up: LEARNING DIRECTED EXPLORATION STRATEGIES 논문 요약
DeepMind의 Adrià Puigdomènech Badia, Pablo Sprechmann 등이 ICLR 2020에 발표하였다.
이 논문에서 저자들은 directed exploratory policy들을 학습함으로써 hard exploration game들을 해결하기 위한 강화 학습 agent를 제안한다. 저자들은 새로운 curiosity-driven exploration 방법을 제안함으로써 이 문제를 해결하고자 한다.
이 논문의 핵심 아이디어는 동일한 network에서 독립적인 exploration & exploitation policy들을 jointly learn 하는 것이다. 저자들은, UVFA (Universal Value Function Approximators) framework를 사용하여 parametrise 되고 다양한 정도의 exploratory behavior를 가진 policy들을 jointly learn 하는 것을 제안한다.
이 논문의 기여는 다음과 같다.
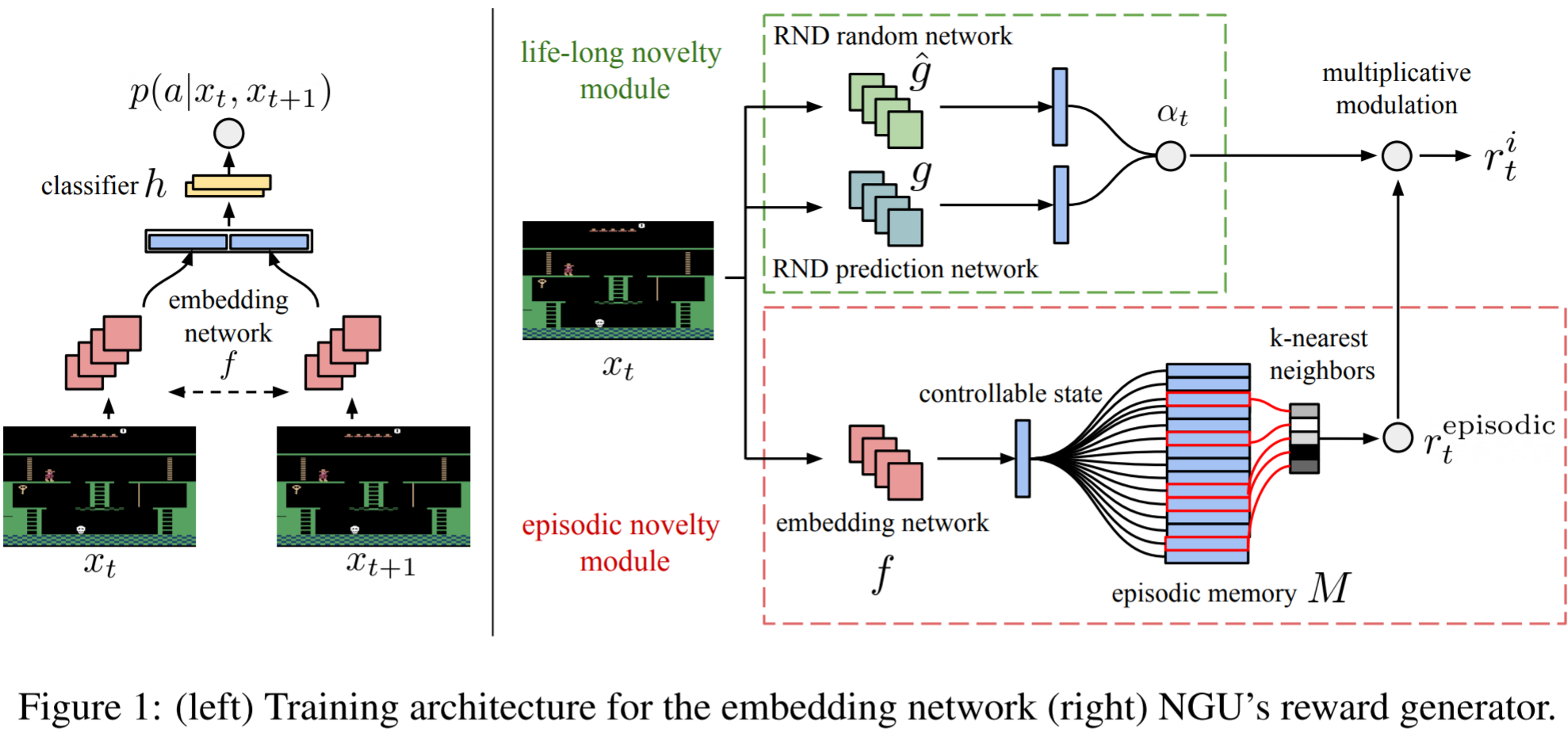
1. Agent의 학습 과정동안 exploration을 유지할 수 있는 (never give up 하기 위한) exploratory strategies를 학습하기 위해 life-long novelty와 episodic novelty를 합친 exploration bonus를 정의함.
2. 가중치를 공유하는 conditional architecture을 사용하여 exploration과 exploitation을 분리하는, policy들을 학습함.
3. 제안된 방법이, 확장 가능하고, hard exploration task들에 대해 state-of-the-art와 비슷하거나 더 나은 성능을 보인다는 실험적인 증거.
Intrinsic Reward
, where is a chosen maximum reward scaling.
Embedding network
Embedding network 는 현재 observation을 그것의 controllable state에 해당하는 p차원의 벡터로 매핑한다.
많은 보행자와 차량이 있는 분주한 도시에서 길을 찾는 것과 같이 agent의 action과 관계 없이 많은 변화를 가진 environment를 생각해보자. Agent는 어떤 action도 취하지 않고, 많고 다양한 state를 방문할 수 있다. 이것은 어떤 의미있는 형태의 exploration을 수행하도록 하지 않는다. 이러한 의미 없는 exploration을 피하기 위해, 두 연속된 observation이 주어졌을 때, 한 observation에서 다음 observation으로 가기 위해 agent가 선택한 action을 예측하도록 Siamese network f를 학습한다.
더 형식적으로 나타내면, 두 연속된 observation , 과 agent가 취한 action 로 이루어진 triplet 이 주어졌을 때, 우리는 conditional likelihood를 다음과 같이 parameterise 한다.
, where is a one hidden layer MLP followed by a softmax.
와 의 파라미터들은 maximum likelihood를 통해 train 된다.
Per-episode novelty
Episodic memory 은 controllable state들을 온라인 방식으로 저장하는 동적 크기의 slot-based memory이다. 시각 에, 이 memory는 현재 episode에서 방문한 모든 observation의 controllable state들을 가지고 있다.
state-action 횟수를 보너스 reward로 바꾸는 이론적으로 정당화된 exploration 방법에 영감을 받아, intrinsic reward를 다음과 같이 정의한다.
여기서 은 abstract state 에 대한 방문 횟수다.
은 의 원소에 대해 kernel 함수 에 의해 주어진 similarity들의 합으로 근사화 된다. 실제로는, pseudo-count들을 memory 에서 -nearest neighbors를 사용해 계산하고, 로 표현한다. 함수 는 다음과 같이 계산한다.
여기서 은 작은 상수 (이 논문의 모든 실험에서 으로 고정), 는 Euclidean distance이고 은 -th nearest neighbor들의 Euclidean distance의 제곱의 running average이다. 서로 다른 task는 학습된 embedding 사이에 일반적인 거리가 다를 수 있기 때문에, 이 running average는 kernel을 task에 더 robust하도록 만드는 데 사용된다.
Life-long novelty
이 논문에서는 long-term novelty estimator로 Random Network Distillation을 사용했다. RND modulator 는 다음과 같의 정의된다.
랜덤하고 훈련되지 않은 convolutional network 와, predictor network 가 있다고 하자.
훈련할 동안 관찰된 모든 observation에 대하여 를 최소화하도록 의 파라미터 를 학습한다.
Modulator 는 논문 Exploration by random network distillation에서 정의한 것처럼 다음과 같이 정의한다.
, where and are running standard deviation and mean for .
이렇게 정의하면 익숙하지 않은 observation에 대해서는 가 크고, 익숙한 observation일수록 가 작다.
Never-Give-Up Agent
Architecture
Never-give-up agent는 R2D2를 basis로 사용하여 recurrent state, experience replay, off-policy value learning, distributed training을 합친다.
시점의 reward 를 다음과 같이 정의할 수 있다.
, where and are respectively the extrinsic and intrinsic rewards, and is a positive scalar weighting the relevance of the latter.
저자들은 Universal value function approximator (UVFA) 를 형태의 a family of augmented rewards에 대한 optimal value function을 동시에 근사하기 위해 사용한다. 여기에서 개의 값을 사용하고, 과 (: maximum value)가 되도록 한다. 이렇게 하면 exploratory behaviour를 꺼서 에 대해 greedy하게 acting할 수 있다.
RL loss functions
Training loss로 transformed Retrace double Q-learning loss를 사용한다.
와 (discount factor)를 쌍으로 묶는다. , 가 되게 한다. 이렇게 하면 exploitative policy 가 가장 큰 discount factor 와 쌍이 되고, 가장 탐색적인 policy 이 가장 작은 discount factor 와 쌍이 된다.
Intrinsic reward가 dense하고 값의 범위가 작기 때문에 탐색적인 policy를 위해 작은 discount factor를 쓸 수 있다. 반면에, discount되지 않은 return을 최적화하는 것에 가능한 가깝게 하기 위해 exploitative policy에 대해 가능한 가장 큰 discount factor를 선호한다.
Distributed training
이 논문에서 제안하는 agent는 R2D2 기반으로 만들었으며 learning과 acting을 decouple한다. Actor들은 experience를 분산된 replay buffer에 저장하고 learner는 prioritized 방식으로 무작위 추출된 배치에 대해 학습한다.
실험
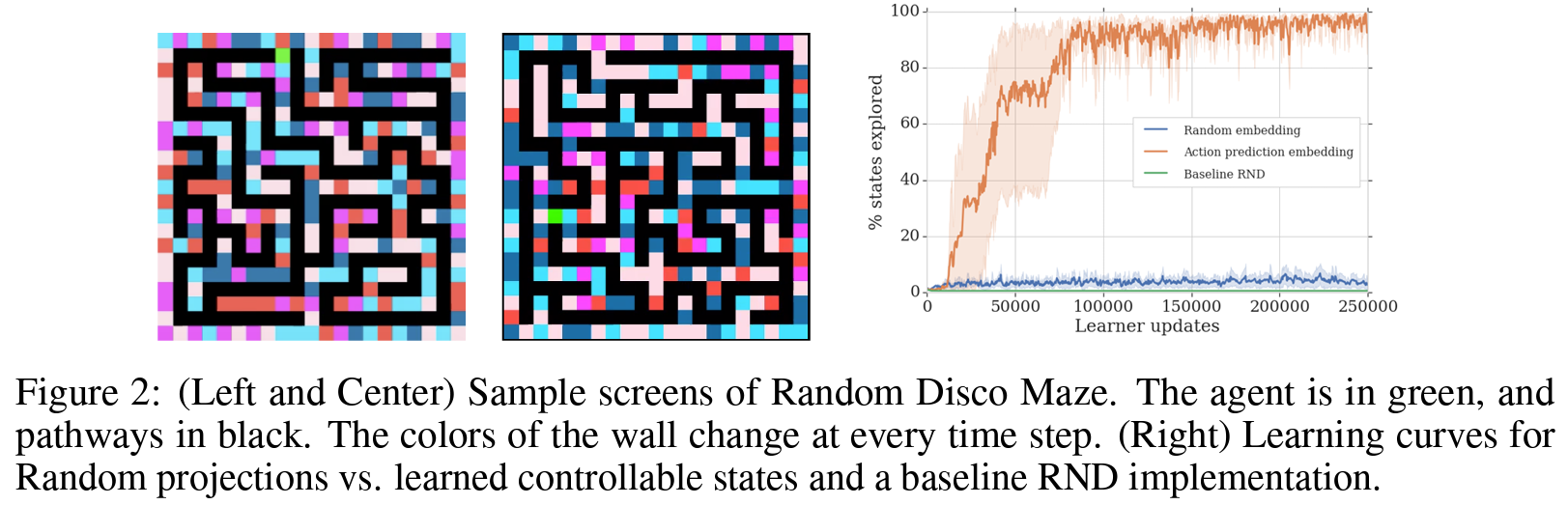
Controlled Setting Analysis
Figure 2는 제안된 모델로 학습된 agent들과, mapping 가 고정된 랜덤 projection인 agent가 방문한 서로 다른 state(미로에서 서로 다른 위치)들의 비율을 보여준다. 제안된 모델은 task-distribution으로부터 추출된 어떤 미로도 탐색할 수 있도록 학습했다. Baseline RND 뿐만 아니라 랜덤 projection을 사용한 모델은 그러한 탐색적 행동을 보여주지 않았다.
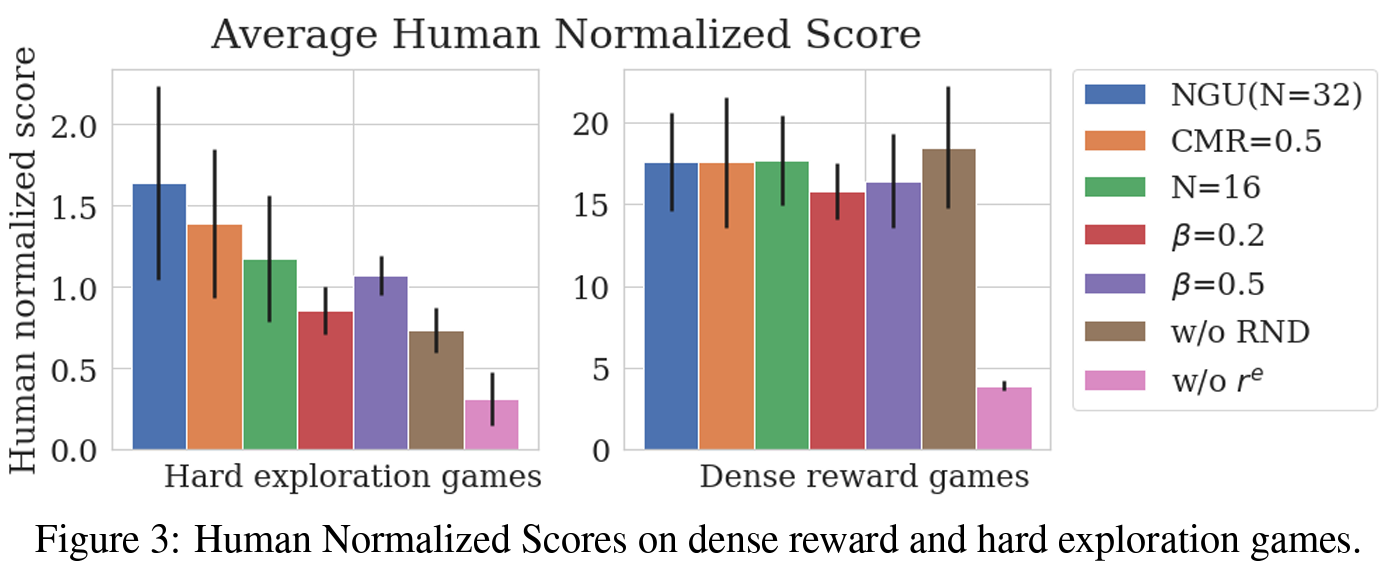
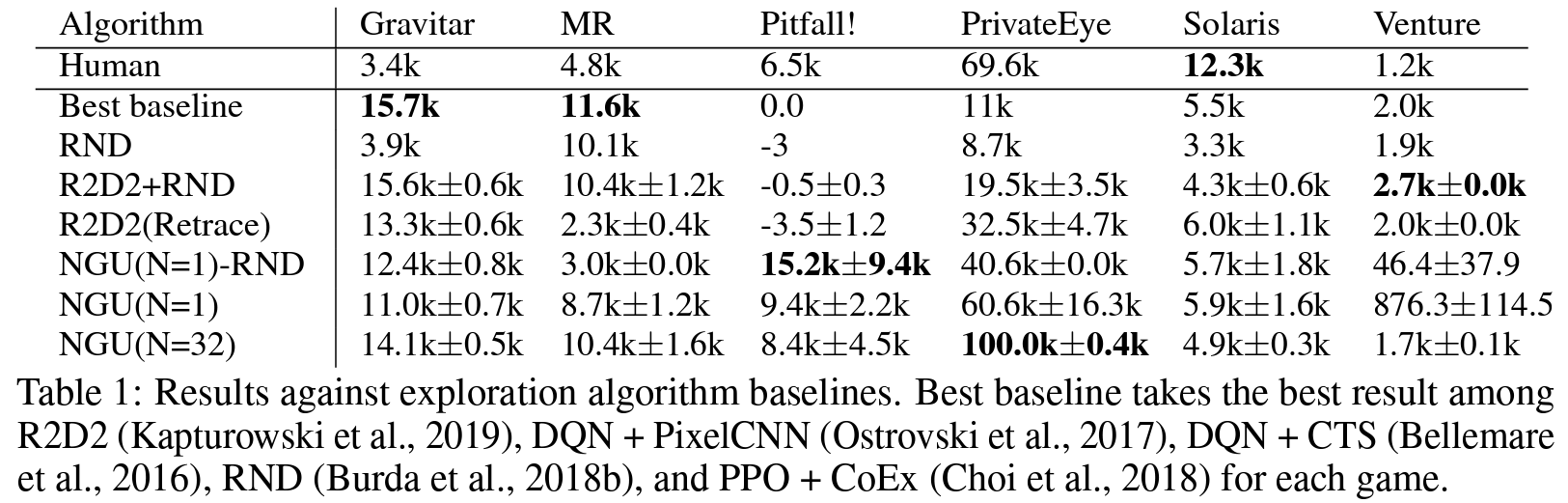
Atari Results
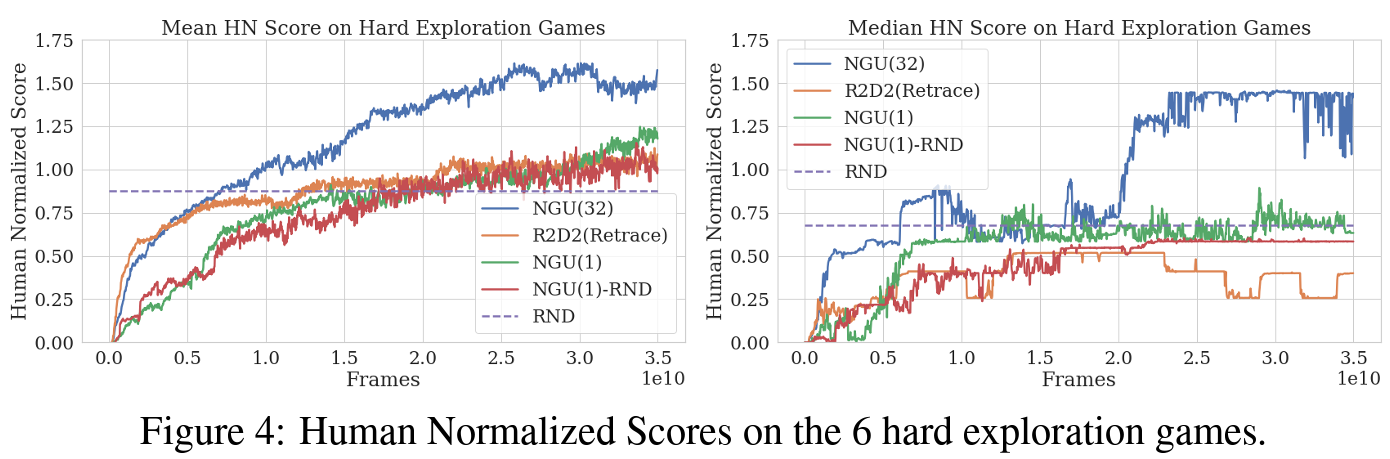
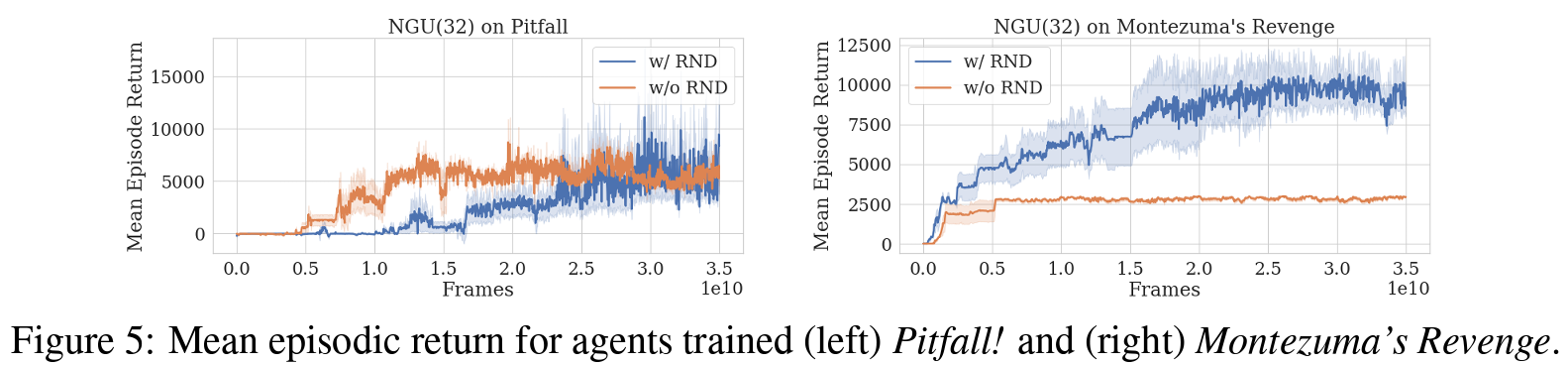
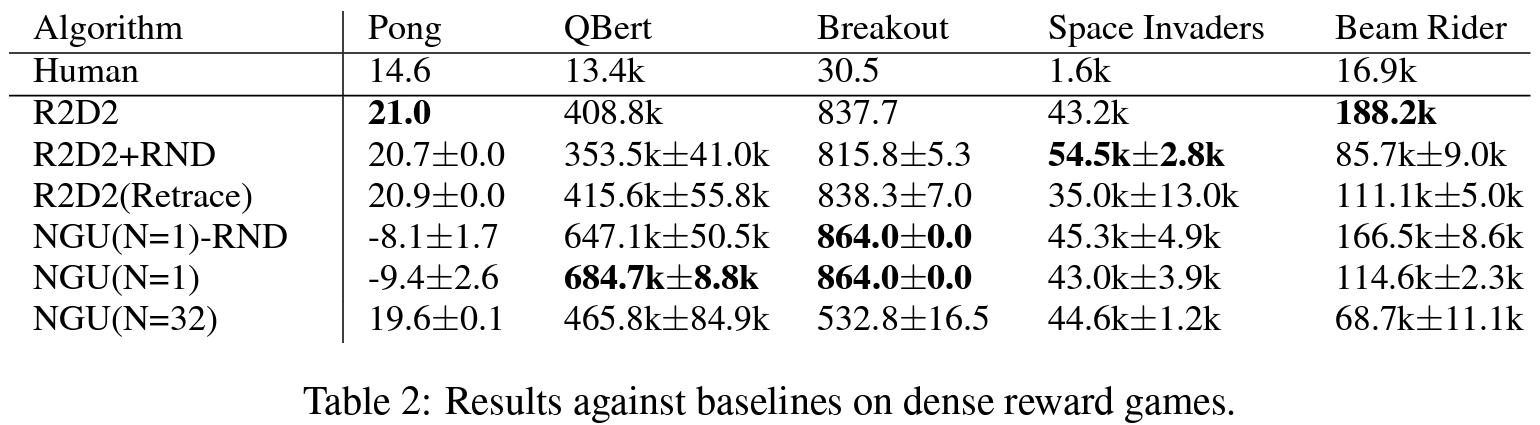
결론
저자들은 sparse하거나 dense한 rewards 시나리오에서 효과적으로 학습할 수 있는 강화 학습 agent를 선보였다. 제안된 agent는 모든 아타리 hard-exploration 게임에서 높은 점수를 달성하면서, 모든 아타리-57 suite에서 매우 높은 평균 점수를 유지했다.
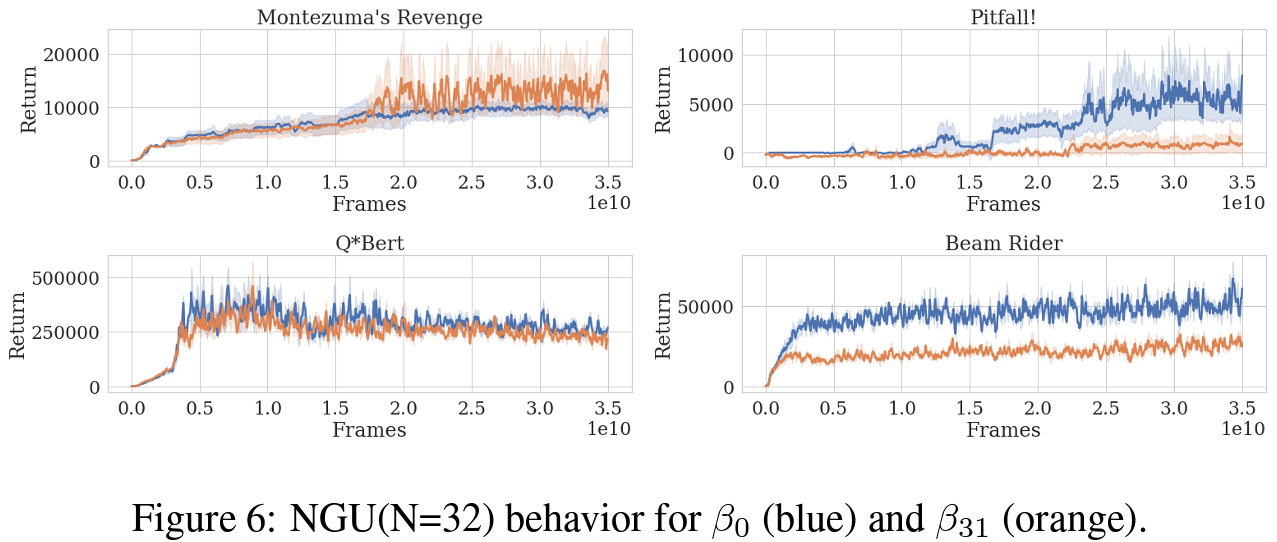
참고
