본 내용은 데이콘 스터디에서 배운 내용을 토대로 정리한 것입니다.
1. 이상 탐지의 개념
- 이상 값은 '정상'이 아닌 값으로, '정상'에 대한 정의는 적용 분야 및 문제마다 다르게 정의될 수 있다.
- 이상 값은 Anomalies, Outliers, Novelties, Noise, Deviations, Exception와 같이 표현 될 수 있다.
- 이상 값에 대한 정의는 데이터마다, 분야마다 다르게 적용되므로 다양한 방법들이 활용되고 있다.
2. 이상의 종류
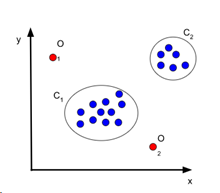
1) 점 이상 (Point Anomaly)
- 데이터 내 하나의 관측 값이 나머지에 이상하다고 판단되는 경우
2) 맥락적 이상 (Contextual Anomaly)
- 시간의 특성을 가지는 Time-Series 분야에서 많이 나타난다.
- 시계열 자료에서는 시간의 연속성이 존재하여 특정 시점이 그 시점 전, 후의 값에 크게 영향을 받는다.
- 시계열 자료에서 비정상적인 시점을 찾는 것을 목표로 하느냐, 비정상적인 변화의 패턴을 찾는 것을 목표로 하느냐에 따라 분류
- 과거 자료의 이상 값에 대한 라벨이 이용 가능한지의 여부에 따라 지도 vs 비지도 학습으로 분류됨
3. 이상 탐지의 다양한 적용 사례
1) Cyber-Intrusion Detecion
- 컴퓨터 시스템 상에 침입을 탐지하는 사례. 주로 시계열 데이터를 다루며 RAM, file system, log file 등 일련의 시계열 데이터에 대해 이상치를 검출하여 침입을 탐지함.
2) Fraud Detection
- 보험, 신용, 금융 관련 데이터에서 불법 행위를 검출하는 사례.
3) Malware Detection
- Malware(악성코드)를 검출해내는 사례. Classification과 Clustering이 주로 사용되며 Malware 데이터를 그대로 이용하기도 하고, 이를 Gray Scale Image로 변환하여 이용하기도 함.
4) Medical Anomaly Detection
- 의료 영상, 뇌파 기록 등의 의학 데이터에 대한 이상 탐지 사례. 주로 신호 데이터와 이미지 데이터를 다루며 X-ray, CT, MRI, PET 등 다양한 장비로부터 취득된 이미지를 다루고 있음.
5) Social Networks Anomaly Detection
- Social Network 상의 이상치들을 검출하는 사례. 주로 Text 데이터를 다루며 Text를 통해 스팸 메일, 비 매너 이용자, 허위 정보 유포자 등을 검출함.
6) Log Anomaly Detection
- 시스템이 기록한 log를 보고 실패 원인을 추적하는 사례. 주로 text 데이터를 다루며 Pattern Matching 기반의 단순한 기법을 사용하여 해결할 수 있지만 Failure Message가 새로운 것이 계속 추가, 제외가 되는 경우에 딥러닝 기반 방법론을 사용하는 것이 효과적임.
7) IoT Big-Data Anomaly Detection
- 사물 인터넷에 주로 사용되는 장치, 센서들로부터 생성된 데이터에 대해 이상치를 탐지하는 사례. 주로 시계열 데이터를 다루며 여러 장치들이 복합적으로 구성되어 있음.
4. 이상 탐지 기법
1) 학습 시 비정상 sample의 사용여부 및 label 유무에 따른 분류
a. Supervised Anomaly Detection
- 주어진 학습 데이터 셋에 정상 sample과 비정상 sample의 Data와 Label이 모두 존재하는 경우
b. Semi-supervised (One-Class) Anomaly Detection
- Class-Imbalance가 매우 심한 경우 정상 sample만 이용해서 모델을 학습
- 이 방식을 One-Class Classification(혹은 Semi-supervised Learning)이라고 부른다.
- One-Class SVM이 대표적인 방법론이며, 이것을 확장해 Deep Learning을 기반으로 One-Class Classification 방법론을 사용하는 Deep SVDD가 잘 알려져 있음.
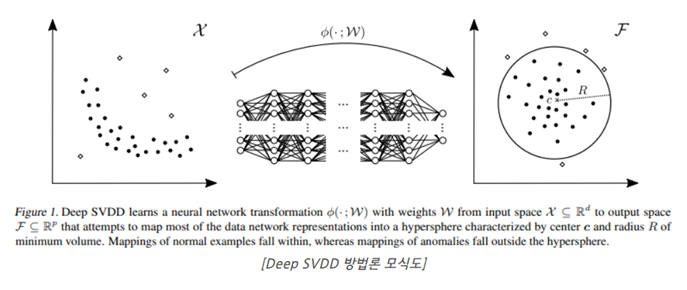
c. Unsupervised Anomaly Detection
- One-Class(Semi-supervised) Anomaly Detection 방식은 정상 sample이 필요.
- 정상 sample 인지 알기 위해서는 반드시 정상 sample에 대한 Label이 필요.
- 대부분의 데이터가 정상 sample이라는 가정을 하여 Label 취득 없이 학습을 시키는 방법.
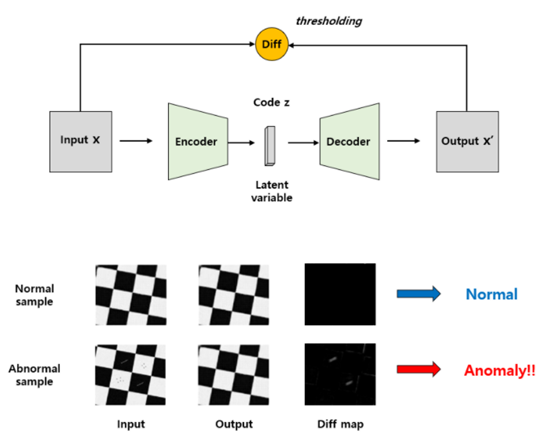
- 대표적으로 Autoencoder 기반의 방법론이 주로 사용되고 있음.
c-1. Autoencoder Based Unsupervised Anomaly Detection
본 스터디에서 중점적으로 학습하는 방법론.
- 입력 샘플을 인코더를 통해 저차원으로 압축.
- 압축된 샘플을 디코더를 통과시켜 다시 원래의 차원으로 복원.
- 입력 샘플과 복원 샘플의 복원 오차(reconstruction error)를 산출.
- 복원 오차는 이상 점수(anomaly score)가 되어 threshold와 비교를 통해 이상 여부를 결정. threshold보다 클 경우 이상, threshold보다 작을 경우 정상
2) 비정상 sample 정의에 따른 분류 (Supervised Anomaly Detection)
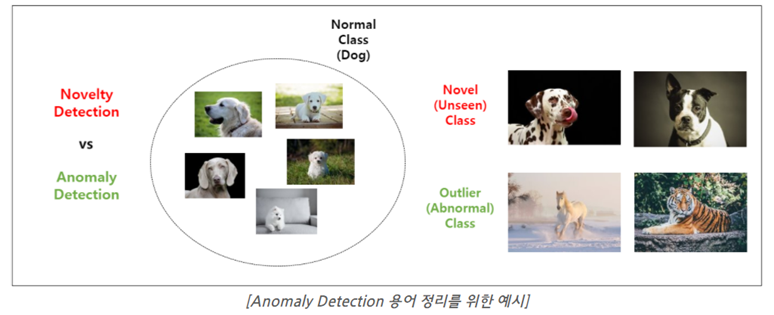
a. Novelty Detection
- 현재 보유 중인 데이터 셋에 이전에 없던 형태의 새로운 데이터가 등장하는 경우.
b. Outlier Detection
- 현재 보유 중인 데이터와 전혀 관련 없는 sample이 등장하는 경우.

To be a changer who can overturn world