RNN 언어 모델
예문: "what will the fat cat sit on"
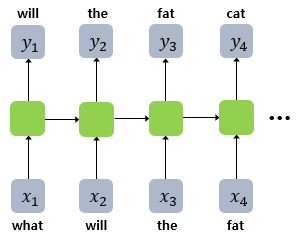
- 네번째 시점의 cat은 앞서 나온 what, will, the, fat이라는 시퀀스로 인해 결정된 단어.
- 사실 위 과정은 훈련이 끝난 모델의 테스트 과정 동안(실제 사용할 때)의 이야기
- 훈련 과정에서는
what will the fat cat sit on라는 훈련 샘플이 있다면,
what will the fat cat sit시퀀스를 모델의 입력으로 넣으면,
will the fat cat sit on를 예측하도록 훈련
교사 강요(teacher forcing)
: 테스트 과정에서 t 시점의 출력이 t+1 시점의 입력으로 사용되는 RNN 모델을 훈련시킬 때 사용하는 훈련 기법
- 훈련할 때 교사 강요를 사용할 경우, 모델이 t 시점에서 예측한 값을 t+1 시점에 입력으로 사용하지 않고, t 시점의 레이블. 즉, 실제 알고있는 정답을 t+1 시점의 입력으로 사용
->훈련 과정에서도 테스트 과정처럼 훈련 시킬 수 있지만, 이는 한 번 잘못 예측 시에 뒤의 예측까지 영향을 미쳐 훈련 시간이 느려지게 되어 비효율적
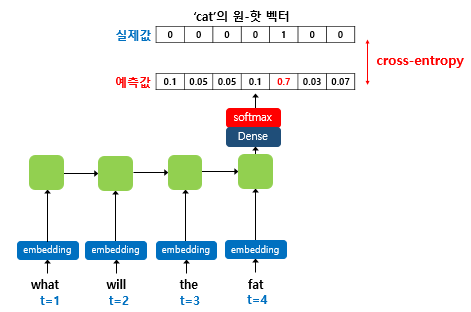
- 훈련 과정 동안 출력층에서는 softmax를 활성화 함수로 사용
- cross-entropy 함수는 모델 예측 값과 실제 레이블과의 오차 계산 위한 손실 함수로 사용
RNNLM 구조
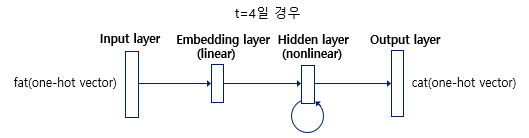
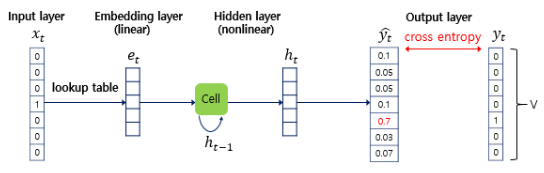
단어 집합의 크기가 V일 때, 임베딩 벡터의 크기를 M으로 설정하면, 각 입력 단어들은 임베딩층에서 V × M 크기의 임베딩 행렬과 곱해짐
이 임베딩 행렬은 역전파 과정에서 다른 가중치들과 함께 학습됨
임베딩층:
은닉층:
출력층:
-> V차원의 벡터는 softmax 함수 지나며 0과 1 사이의 실수 값 가지며 총 합은 1이 되는 상태로 바뀜
->이는 의 j번째 인덱스가 가지는 값은 j번째 단어가 다음 단어일 확률을 나타냄
- 은 실제값 에 가까워져야 함
- 이를 위해 손실 함수를 사용하고, 역전파가 진행되며 가중치 행렬들이 학습되는데, 이 과정에서 임베딩 벡터값들도 학습이 됨
+RNNLM에서 학습 과정에서 학습되는 가중치 행렬은 (룩업 테이블 임베딩 행렬), 4개.
딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/46496
