
book_데이터를부탁해
- 어떤 데이터든 (머신러닝, 마케팅, 빅데이터..)
알아야 할 기초개념들이 넘쳐나는 책 - 사실, 통계 / 수학 개초오랩에게는 이 마저도 어려웠으나
올바른 바다에서 허우적대는 기분
제가 읽은 데이터 관련 책 중에,
진짜 쓸모있는 개념들이 많은 느낌이었습니다.
대신 수학자들의 관계를 막 설명해주는데,
역사 헤이러여서인지... tmi..로 느껴진 부분들이 있었습니다.
읽으면서 하...이건 귀찮아도 적어야겠다..
또 모르면 대학 다시 다녀야해....하는 개념들 위주로 정리했습니다.
.
.
(주의)
연장 2회까지 하면서 늑장부리며 읽다가 도서관한테 뺏겨서
중간 까지의 내용임
가설
_ #1. 무엇을 분석할지 대상과 가설을 정하는 것
가설은 크게 두 가지 종류가 있다.
맞는 것 보다 틀린 것 증명이 쉽기에, 귀무가설을 많이 씀
-
대립가설 : 가설이 맞다는 것을 증명하기
→ 이를 거짓으로 오판할 경우가 '제 1종 오류'
-
귀무가설 : 가설의 반대 상황이 틀렸다는 것을 증명함 → 내 가설이 논리적으로 맞음
→ 이를 반대로 오판할 경우가 '제 2종 오류'
.
유의수준
_ #2. 참과 거짓을 구분할 기준을 정하는 것
유의수준을 정하고, 유의수준이 미만인 가설들은 모두 기각시킴
이를 줄이는 게 더 신뢰도 높은 가설
- eg) 5% 로 유의수준을 정했을 때, 6% 확률로 참인 가설은 무의미하다고 판단
→ 95% 의 유의확률을 가지는 가설이 탄생
.
t-검정
_ #3. 분석 내용이 기준에 부합하는 지 판단하기
두 집단 간 평균의 차이가 있는지를 비교, 검증하는 과정
?왜 평균의 차이를 구하는가?
판단의 데이터는 '표본' 이 될 수 밖에 없는데,
이 표본이 충분히 전체를 대표할 수 있을지를 증명하기 위해서
표본의 평균이 전체 수준에서 몇 번이나 차이가 나는지를 확률로 정하는 과정임
→ 데이터 양이 적기 때문에, 만약 충분한 데이터라면 z-검정을 쓰자 (Z 분포로, 집단 간 차이점만 밝혀내도 됨)
?데이터 많고 적음의 기준은 뭔데?
보통 t-검정은 항상 염두에 두고 하기.
데이터가 많다고 못하는 게 아니기 때문에
확률
- 확률은 무작위로 선택된 값을 열거해 헤아릴 수 있음을 의미한다.
- 이산확률변수 : 각 변수가 값을 가지는 걸 별개의 사건으로 봄
- 연속확률변수 : 각 변수는 변화하면서 연속적으로 발생하는 사건의 연장으로 봄
- 이에 속하는 분포 : 균등분포, 정규분포, 지수분포
- 가설검정의 종류
- 정규분포 : z-분포
- t 분포 : t-검정
- 2개 집단 분석
- f 분포 : 분산분석
- 3개 이상의 집단 분석
.
분산분석
_3개 이상의 집단을 분석할 때, 여러 독립조건과 종속조건을 가질 때 쓰는 분석법
-
분산분석의 핵심 원리
(3가지 제어환경이 중요함)
- 무작위적으로 대상 선정을 함(조건을 100% 통제할 수 없음)
- 결과를 판단하는 환경 역시 100% 통제할 수 없음
- 여러가지 요인이 옇양을 주기 때문에, 반복 수행으로 결과를 비교해야 함
-
→ 이에 따른 '오차' 를 비교하는 게 중요함
→ 오차보다 더 큰 영향을 주는 게 무엇인지 찾아내기
.
- 분산분석에서 필요한 가정
- 독립변수의 조건은 모두 독립적이어야 함
- 독립변수의 영향을 받는 종속변수의 값은 정규분포를 만족해야 함(하나의 정규성을 가짐)
- 이게 아니라면, 데이터가 부족하기 때문일 수 있음
- 종속변수의 분산은 조건마다 같아야 함 (등분산성)
- eg) 어떤 환경에서 자란 토마토가 맛있을까 의 검증에서, 토마토 맛 평가는 똑같이 5개씩 먹어봐야 함
요지피셜
나올때마다 헷갈리는 독립변수와 종속변수
.
독립변수 : input
종속변수 : 독립변수에 영향을 받는 결과 값, ouput
요지피셜
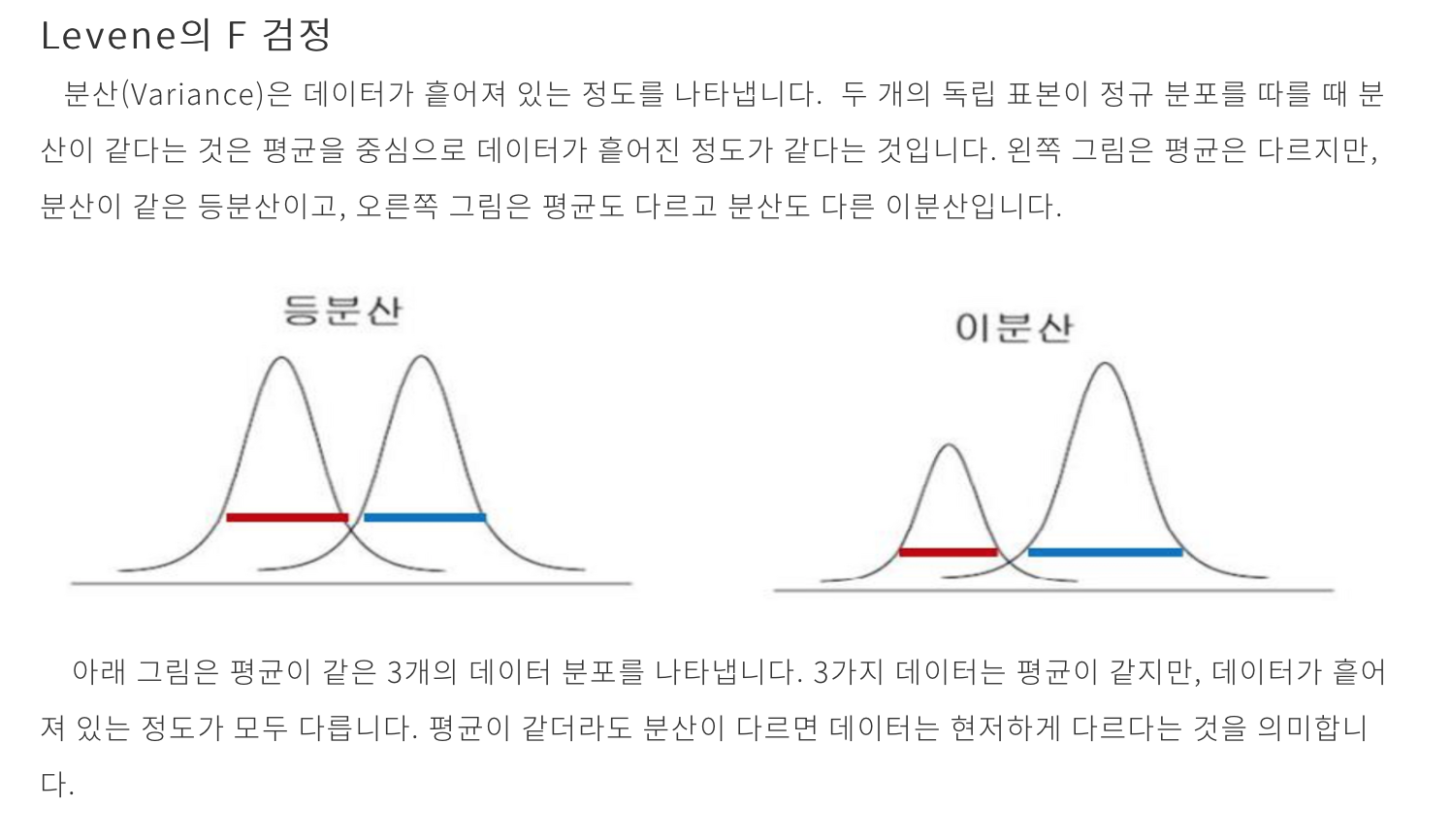
등분산이 뭐지..
= 똑같이 흩어져 있어야 함.
.
eg) 토마토 먹어볼 때 횟수에 따라 분산 찍히는 게 다르기 때문에, 똑같이 균등하게 분포해야 함
출처 : https://brunch.co.kr/@linecard/630
모수와 비모수
-
모수 : 연속적일 수 있음
정규분포를 대표하는 값은 평균과 분산임,
그래서 통계에서는 이 두 가지를 모수라 부름 (대표하는 값)- 모수가 되려면?
- 데이터가 정규분포를 따라야 함
- 데이터가 정규분포 표현할만큼 많아야 함
- 데이터가 모두 같은 환경에 있어야 함
- 모수가 되려면?
.
-
비모수 : 연속적이지 못함
모수가 아닌 값 → 피어슨 상관분석을 하면 안됨-
그럼 왜 모수가 못되는가!
1) 데이터 표본 수가 적어서
→ 근데, 데이터 홍수 시대에 이런 경우는 거의 없다
→ 우선 모수검정 수행하고, 이 결과로 다시 2차 비모수 검정을 하는 것임!2) 데이터가 서로 독립적이여서
→ 이러면 아묻따 비모수로 -
그럼 어떻게 분석하나!
- 평균이 의미가 없기 때문에,
- 서열(순위) 또는 특정 기준 값(eg. 중앙값) 을 기준으로 분석함
-
유의!
- 비모수 상관분석에서는 두 변인을 순위를 기준으로 비교하기 때문에, 변인의 비례적 연관성은 무시함
-
.
군집화
_데이터의 의미있는 맥락 찾기
-
두 데이터 간 거리는 N 차원에서도 구할 수 있어야 하기 때문에, 피타고라스정리가 아닌
-
유클리드 거리 유사도를 사용해야 함.
- 실제, 딥러닝 에서 유클리도 유사도를 이요해 모델을 설계함
- 유클리드 거리 유사도 관련 설명 : https://wikidocs.net/24654
-
이외 기준에 따른 유사도 구하는 법
- 거리에 따라 → 맨해튼 공식
- 방향에 따라 → 코사인 유사도
뭔가 무해한 개념 설명이라
지금껏 가장 이해하려 애썼던 것 같아요.
감사합니다. 익준쓰앵님 ( _ _ )
