4. DDL
데이터베이스를 선정하여 ERD의 요소들을 실제 데이터베이스의 요소들로 변환
DDL 구조
- CREATE : 테이블을 생성하는 기능을 수행하는 명령어
- CREATE문 구조
CREATE TABLE [스키마명.] 테이블명
(컬럼명, 데이터타입 [기본값][제약조건] , ...);
CREATE TABLE emp_ex (
empno number(5),
ename varchar2(10),
salary number(5)
);- ALTER : 테이블이나 컬럼의 이름을 바꾸거나 / 제약조건을 변경하거나 / 컬럼을 추가 또는 삭제하는 등의 다양한 테이블 변경 기능을 수행하는 명령어
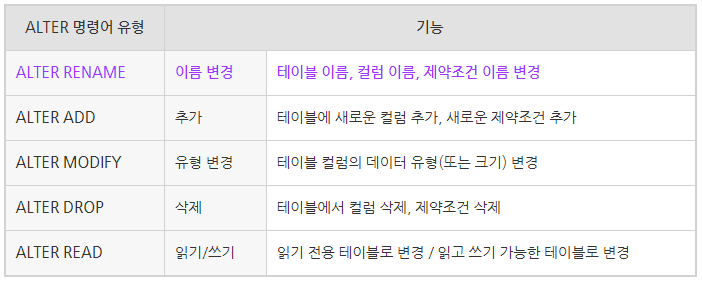
[출처][오라클/SQL] ALTER RENAME : 테이블 이름 변경, 컬럼(변수) 이름 변경, 제약조건 이름 바꾸기|작성자 리제
- ALTER문은 구조가 다양해서 다 외워서 직접 쿼리를 짜는건 네비게이션 없이 처음가는 길을 모두 외워서 다니는 것과 같다...
(Oracle이나 MySQL에는 편리한 기능이 있으니 그걸 사용하자...)
https://m.blog.naver.com/regenesis90/222200592868
위 사이트에서 리제 작성자분이 기깔나게 정리해 놨으니 더 많은 정보는 참고하자
- TRUNCATE :
- 테이블의 모든 행(row)의 데이터 삭제
- 행 자체도 삭제
- 삭제된 행이 사용하고 있었던 저장공간을 반납함
(테이블 용량을 줄일 수 있음)
- 테이블의 인덱스(index)도 삭제됨
- TURNCATE문 구조
TRUNCATE TABLE (삭제하려는 테이블 이름);
- DROP : 테이블을 전체 삭제하는 기능을 수행하는 명령어
- DROP문 구조
DROP TABLE (삭제하려는 테이블 이름);
다른 테이블에서 참조되는 경우 삭제 불가
SEQUENCE
- 테이블 내에서 기본키가 유일한 값을 갖도록 자동으로 지정해주는 객체
- 사용자가 직접 기본키의 값을 생성해 등록하게 되면 중복이 발생할 가능성이 생기며, 직접 로직을 구현해야 한다.
- 기본키(PK)의 중복값을 방지하기 위해 사용
CREATE SEQUENCE 시퀀스명
START WITH [시작값]
INCREMENT BY [증가값]
MINVALUE [최소값]
MAXVALUE [최대값];
emp_ex 테이블의 empno 컬럼 값을 처리하기 위한 시퀀스 생성
CREATE SEQUENCE emp_ex_seq
START WITH 1
INCREMENT BY 1
MINVALUE 1
MAXVALUE 99999;시퀀스 문법
- CURRVAL : 시퀀스의 현재값 확인 (초기 1회 NEXTVAL 실행 후 사용 가능
- CURRENT VALUE의 줄임말
- NEXTVAL : 시퀀스의 다음값 확인
- NEXT VALUES의 줄임말
시퀀스 예제
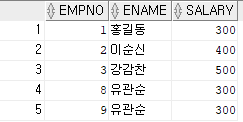
• emp_ex 테이블에 새로운 데이터 등록 시 시퀀스 사용
• 사원명 : 유관순, 급여 : 300
• 현재 시퀀스가 7으로 지정되어 있음
insert into emp_ex values (emp_ex_seq.nextval, '유관순', 300);
/* EMPNO번호가 하나씩 증가하며 데이터가 삽입된다
즉, 기본키 (PK)값을 자동으로 지정해줌 */ 우왕
VIEW
VIEW : 실제 존재하지 않는 논리적인 가상의 테이블
- VIEW문의 구조
CREATE VIEW 뷰명 [(컬럼명...)]
AS
SELECT 문;
VIEW를 사용하는 이유
- 복잡한 SELECT문을 자주 사용해야 하는 경우
- 조회 속도를 높이기 위해
VIEW 생성
- local에 접속(더블클릭)
- GRANT create view TO 사용자계정(testuser);
CREATE VIEW emp_view
AS
SELECT * FROM emp WHERE job = '사원';- 이제 만들어진 emp_view를 따로 조회하여 속도up!
INDEX
INDEX :
- 데이터의 빠른 검색을 위해 사용하는 색인 기술
- B-tree 자료구조를 이용하여 검색 속도 향상
- B-tree(Balanced Tree)란 이진트리의 변형된 알고리즘으로, 데이터들을 빠르게 찾을 수 있도록 트리구조에 정렬한 상태로 보관하는 방식
INDEX 장/단점

INDEX 실습
인덱스 실행 전 실행 계획 출력
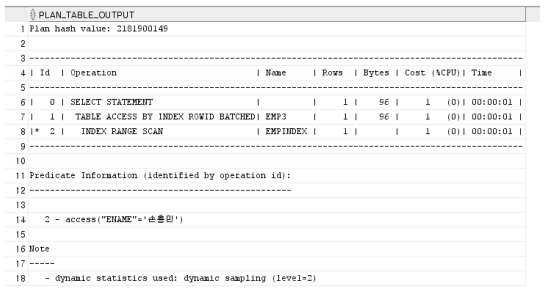
explain plan for select * from emp where ename = '손흥민';
select * from table(DBMS_XPLAN.DISPLAY);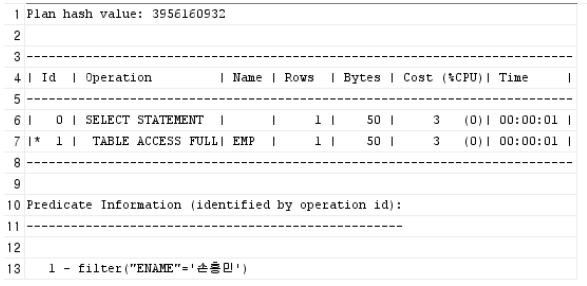
인덱스 생성
emp 테이블의 직원명(ename) 컬럼에 인덱스 생성
CREATE INDEX empindex ON emp (ename);다시 인덱스 실행 계획 출력
explain plan for select * from emp where ename = '손흥민';
select * from table(DBMS_XPLAN.DISPLAY);