pre-refinement에서 지수이동평균 필터의 효용
3D Human Pose Estimation 분야에서 최근 핫한 메타는 2 step approach이다.
2 step approach란, 기존의 Image → 3D Pose의 모델을 설계하는 게 아닌, Stacked Hourglass/CPN/Mask RCNN/Detectron(이하 2d모델) 등과 같은 2D Pose Estimator의 output(2D Pose)만을 input으로 삼아 3D Pose output을 구하는 모델(이하 3d 모델)을 설계하는 것이다.
NLP식으로 얘기하면 feature-based approach가 되려나...?
CVPR/ICCV의 2019~2020 SOTA 모델들은 거의 대부분 이런 접근 방법을 선택하고 있다.
2d 모델의 output은 이미지 픽셀 좌표계상의 관절 위치 예측값으로, Tensor shape은 이미지마다 이다.
2d 모델의 output이 신뢰할 만하다고 가정했을 때(그리고 카메라 왜곡을 무시했을 때), 의 텐서는 그저 한 순간의 스켈레톤을 2차원 평면으로 투영한 것에 지나지 않는다. 이 데이터만으로는 3d모델에서 쓸 만한 결과를 낼 수가 없는데, 하나의 2d 데이터로부터 가능한 3d 데이터가 유일하지 않기 때문이다.
따라서 2 step approach의 3d 모델들은 전부 이미지 한 프레임의 정보만을 이용하지 않고, 연속된 프레임의 2d 모델 output을 input으로 삼고 있다.
이 때, 입력 텐서의 shape은 가 된다. 그리고 FAIR팀의 VideoPose3D처럼 downsample과정이 있지 않은 이상에야, 출력 텐서 shape은 가 된다.
연속된 프레임에서 부드럽지 못한 불안정한 결과를 낼 수 있으므로, 많은 연구들은 RNN이나 CNN 등 여러 구조의 작은 모델을 추가하여 post-refinement 과정을 진행한다.
문제는, 모든 2d 모델들이 비디오 입력이 아니라 단일 이미지에 대해 예측하도록 설계되었다는 것이다. 그렇기에 2d 모델의 출력은 개의 이미지를 각각 예측하여 도출된 shape output의 나열일 뿐이고, 이를 concat하여 의 텐서로 만드는 것이다.
아무리 좋은 2d 모델이더라도, 그 결과를 재생하면 썩 부드럽지 못한 noisy한 데이터가 될 수밖에 없다. 이를 보정하여 3d 모델의 정제된 데이터를 넘겨주도록 pre-refinement 과정이 필요함은 [논문] Deep Kinematics Analysis for Monocular 3D Human Pose Estimation 같은 논문에서 잘 설명되어 있다.
나는 여기서 신호 처리 필터인 이동평균(MA) 필터나 지수이동평균(EMA) 필터, 혹은 칼만 필터를 적용하는 것이 도움이 될지 호기심이 들었다.
기본적으로 신호 처리 분야에서 MA, Kalman 필터와 같은 것들은 nosiy한 시계열 데이터를 smoothing해주고, 한 순간 값이 튀는 현상을 보정하는 것이다.
경험상 MA, EMA, Kalman 중에는 칼만이 성능이 가장 좋은데, 구현 난이도나 계산 복잡도 측면에서 MA, EMA가 쉽다고 생각한다. 그래서 이에 대해 그 효용이 있을지 한 번 실험해보았다.
-
데이터셋: H36M
- VideoPose3D에서 제공된 data_2d_h36m_cpn_ft_h36m데이터 사용
- train subjcets=[S1, S5, S6, S7, S8], test subjects=[S9, S11]
-
필터 옵션: MA 필터는 window-size값을 [1, 3, 5, 7, 9] 로 설정해 총 5개의 옵션, EMA 필터는 값(이건 경우에 따라 로 표기하기도 하는데, 그냥 선형보간의 비율값이다)을 [0.5, 0.75, 0.9, 0.95]로 총 4개의 옵션
-
3d 모델 구조: VideoPose3D의 TCN
- 빠른 학습을 위해 512채널만 사용
-
하이퍼 파라미터
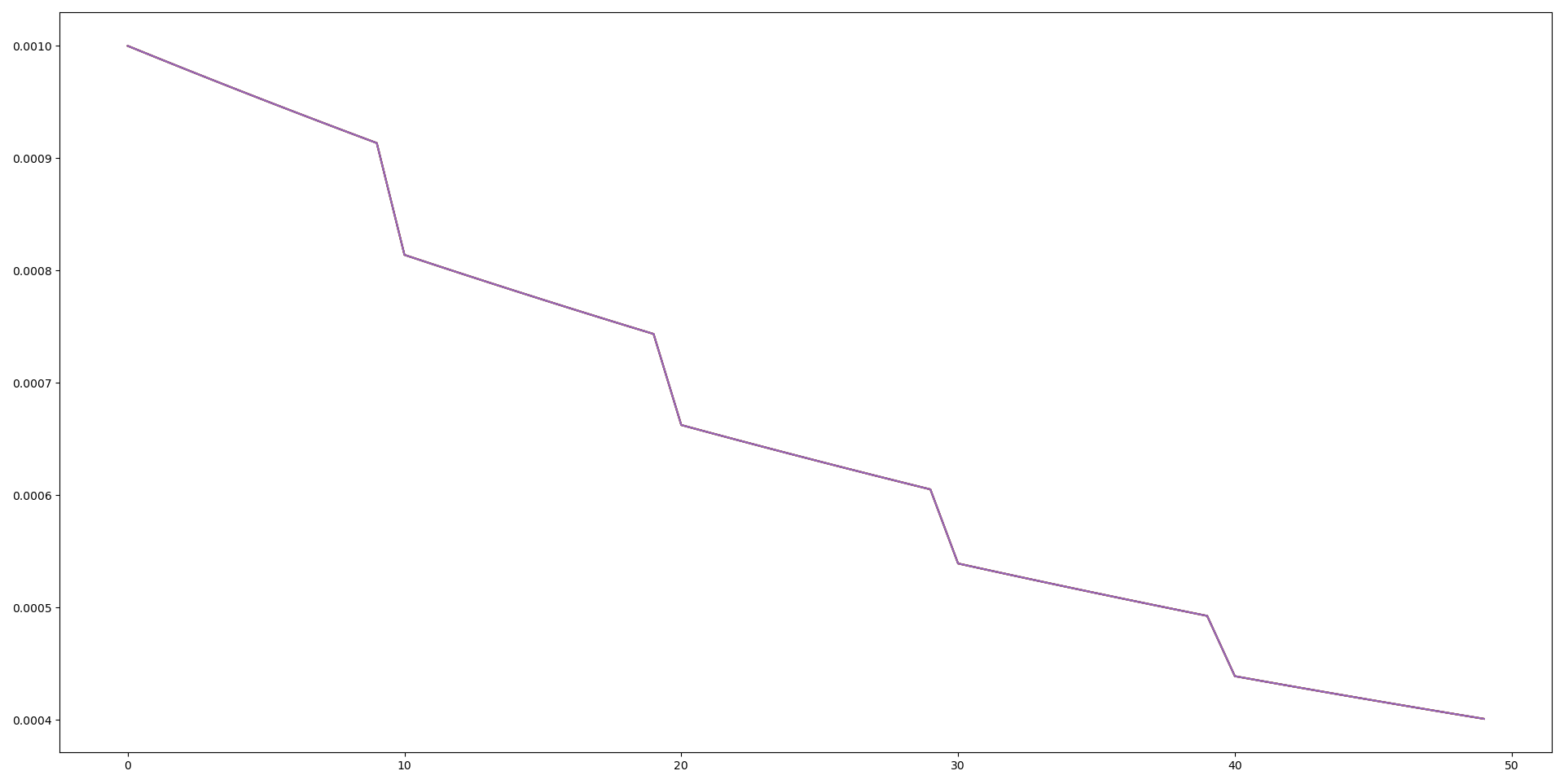
- epochs=50
- lr=1e-3
- lr_decay: 1 epoch마다 0.99, 10 epoch마다 0.9
-
딥러닝 프레임워크: PyTorch
-
실험 하드웨어: Datacrunch V100 Instance
실험 환경은 3D-HM-POSE-EST-EXP-ENV로 진행했다.(은근 슬쩍 개인 레포 홍보... 여기에 파이프라인 구성도 있다. tcn.py 파일 참조)
결과는 아래와 같다.
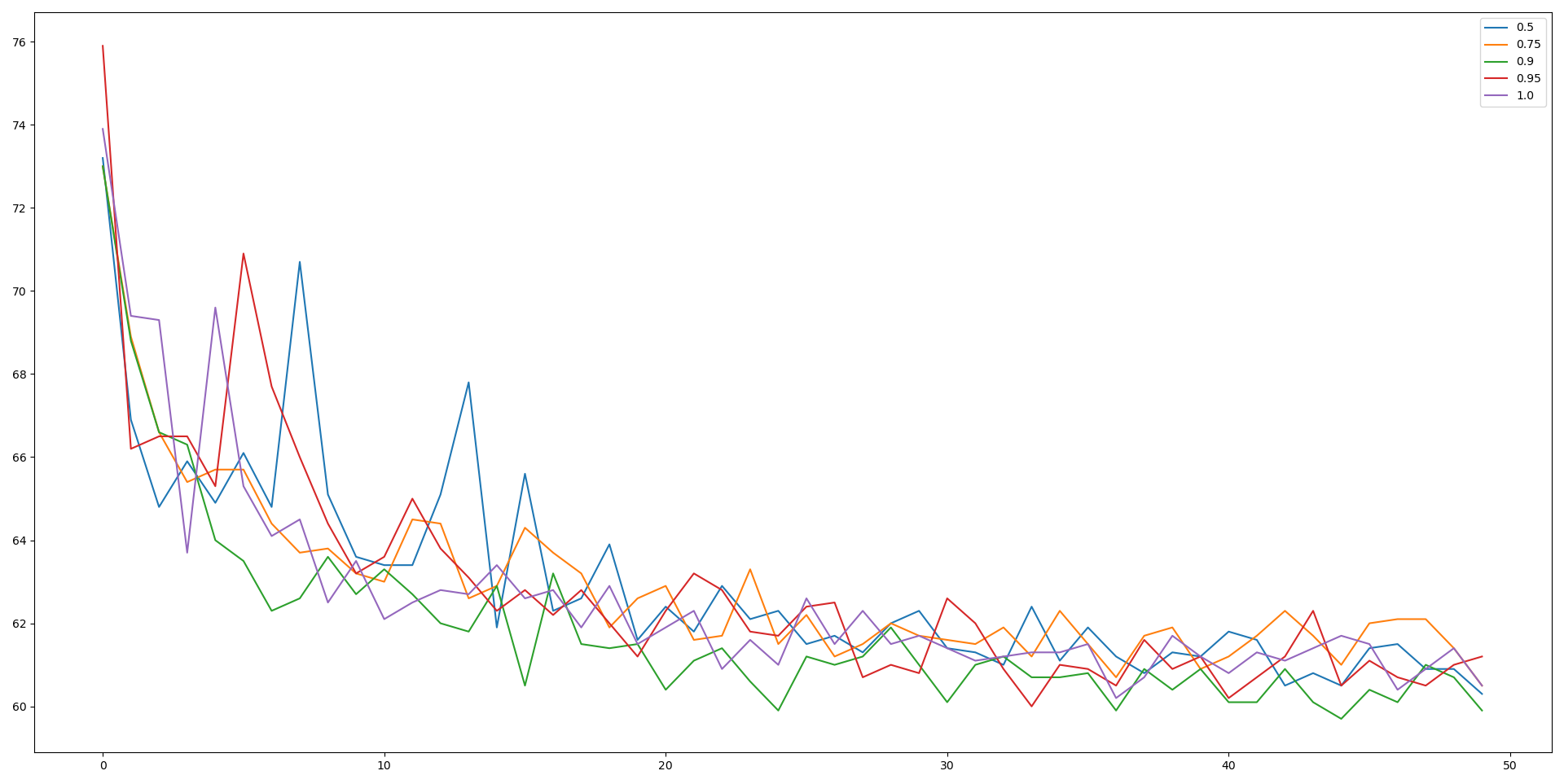 | 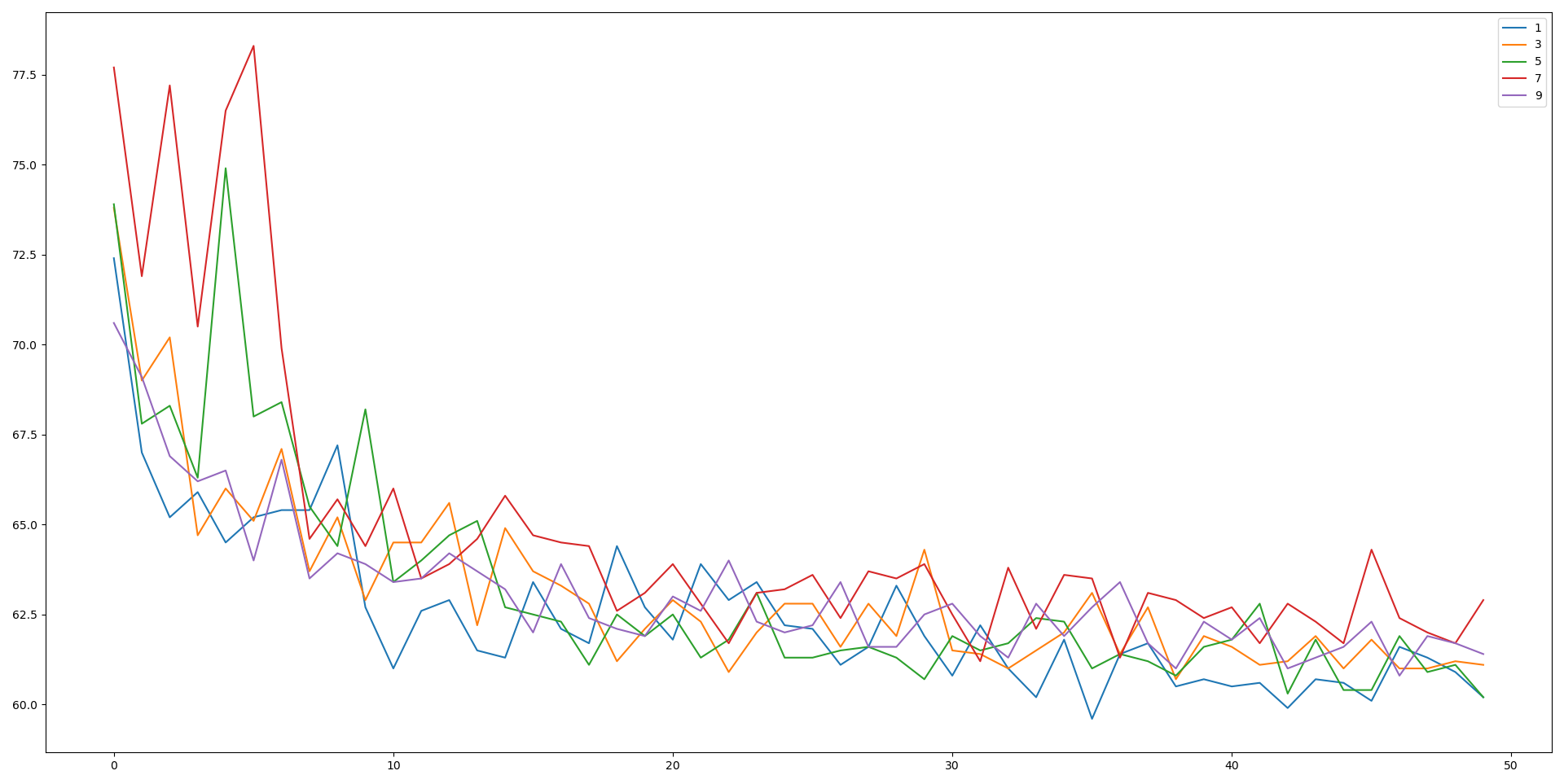 |
|---|---|
| 지수이동평균 필터의 결과 | 이동평균 필터의 결과 |
결과를 보니 100 epochs정도는 돌려야 했나 싶다.
일단 지수이동평균 필터의 경우, 0.75~0.9 정도의 선형 보간은 1.0(필터링 없음)의 경우보다 어느 정도 결과의 향상을 보였다.
이동평균 필터에서도 window size가 1~5정도일 때 역시 필터링이 없을 때보다 test_loss가 작았다.
데이터가 기본적으로 h36m에 fine tuning된 모델의 output이라서, 필터링이 없는 것에 비해 큰 향상은 보이지 않는다. 요즘엔 시간이 빠듯한데, 추후 fine tuning되지 않은 2d 모델의 결과에서 필터링을 적용한 결과를 비교할 예정이다.
결론
MA/EMA 필터는 3D Pose Estimation의 two-step approach에서 pre-refinement processor로 사용했을 때, 모델 학습에 약간 도움이 된다.
