1. 2진수, 8진수, 10진수, 16진수, 그리고 진수 변환과 변수, 기본 자료형, 형 변환
아까 자바 1장에서 우리는 컴퓨터가 0과 1, 2진수로 돌아간다는것을 배웠다. 더 깊게 파고들자면 이런 0과 1을 표현해내는 부품들을 각각 1비트라고 정하면서 이것을 8개 연결하면 8바이트라고 정한것이다. 이걸 수학적으로 계산하면 2의 8승, 2⁸ = 256가지의 패턴이 생기게 된다. 그렇다는 말은 이 0과 1을 표현해내는 8개의 부품 한 묶음은 256개의 결과값을 반환 할수 있게 되는것이다.
이를 언어에 대입하면 1바이트(8비트)는 한 언어의 256개 문자를 기억할수도 있는것이고 숫자에 대입하면 256개의 숫자를 기억시킬수도 있는것이다.
시간이 흘러 점점 기계가 발전하면서 사회, 학문이 발전하고 점점 단순히 8개를 묶은 1바이트에서 그치는것이 아니라 2바이트, 4바이트, 8바이트, 16바이트 ...킬로 바이트 10³(1024바이트)- 메가 바이트 10⁶(1024킬로바이트) - 기가 바이트 10⁹(1024메가바이트) - 테라 바이트 10¹²(1024기가바이트) - 엑사 - 제타 - 요타 까지 현재 기술이 많이 발전했다.
그에 따라 기계에게 기억시키고 연산 처리를 맡겨 받을수 있는 결과값 범위가 한층 넓어졌고 이런 기술의 발전과 함께 프로그래밍의 중요성이 증대됨에 따라 프로그래밍 언어 또한 처음 0과 1로 이뤄진 2진수 언어에서 어셈블리어, 그리고 포트란, C언어, 마지막 자바까지 사람 친화적인 언어로 진화했다.
예를 들면 아래 코드를 보자.
int x = 3 + 7;자바에 대해서 전혀 모른다고 하더라도 일반인 수준의 수학과 영어를 배웠다면 int를 제외하고 x 값은 3 + 7 = 10이라는것 쯤은 알수 있을것이다. 이처럼 0과 1로 이뤄진 난해한 컴퓨터 언어보다 사람이 읽을수 있도록 친화적이게 변화한 것이다.
또한 여기서 x는 변수, 즉 어떤 값을 저장하는 공간이라고 생각하면 편하다. (항상 변할수 있는 수, 마지막 변화값 1개만을 저장한다 또한 변수는 첫글자를 숫자 사용이 안되며 첫글자로 올수 있는거는 _언더바 $달러기호 영어 대문자/소문자만 가능하다. 그리고 되도록이면 전체를 영어소문자로 적어야한다. 또한 공백이 없어야 하며 자바 기본 프로그램에서 미리 지정한 단어인 키워드 예약어로는 변수의 이름 지정이 안된다. 전체적인 표기법은 낙타의 혹처럼 단어 의미 단위마다 결합되는 단어들로 변수명이 이뤄질 경우 경계 첫 글자는 대문자로 적는 camel 표기법과 뱀처럼 경계 첫 글자를 언더바로 적고 대문자로 적는 snake 표기법이 있다. ex) testJava, test_java) 그리고 =은 오른쪽 값을 왼쪽 변수에 대입한다고 생각하면 되고, 변수 = 값 수식을 적는것을 변수 값에 대한 초기화라고 생각하면 된다.
일단 컴퓨터는 0과 1, 2진수로 이뤄진 비트 8개로 묶인 1바이트 단위로 프로그램을 이해하고 실행한다는것이 중요하다. 양수로 한정해 숫자로 따지면 1바이트만 인식할수 있는 컴퓨터는 0부터 255까지의 숫자밖에 이해하지 못한다는것이고 (결과값 또한 마찬가지이다.) 이를 늘리기 위해선 2바이트 2¹⁶으로 늘리는 수밖에 없다. 거기서 더 늘려서 더 큰 값을 처리하고 저장하기 위해선 또다시 바이트를 늘려야 한다.
이런 과정속에서 2진수로는 당연히 계속해서 총 표현되는 숫자 길이가 길어질수밖에 없으므로 더 짧은 길이의 수로 표현되는것이 더 바람직하기에 8진수, 10진수, 16진수로 변환이 가능하다. 그 변환 방법은 아래 사진과 같다.

이런 과정을 거쳐 자바는 프로그램 내 저장되거나 연산 처리되는 숫자나 언어에 대해 메모리 공간을 일정 부분 할당하는 기본 자료형을 정해두었는데 그 내용은 아래와 같다.
(1) 기본 자료형 - 정수형
우리가 1부터 2,3,4...로 부르는 일반적인 숫자는 정수(Integer)라고 한다. 이런 정수를 자바는 어떤 값인지에 따라 범위를 두어 맞춤 메모리 공간을 할당하는 정수 자료형을 선언할수 있는데, 그 규칙은 아래를 보면 된다.
byte 2⁸ : 말그대로 1바이트, -2⁷ ~ 2⁷-1 (-128 ~ 127) 범위의 숫자를 표현한다.
short 2¹⁶ : 2바이트, -2¹⁵ ~ 2¹⁵ -1 (-32,768 ~ 32,767) 범위의 숫자를 표현한다.
int 2³² : 4바이트, -2³¹ ~ 2³¹ -1 (-2,147,483,648 ~ 2,147,483,647) 범위의 숫자를 표현한다.
long 2⁶⁴ : 8바이트, -2⁶³ ~ 2⁶³ -1 (-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807) 범위의 숫자를 표현한다.
(음수 양수 모두를 표현한다면 이렇게 나온다. 양수에서 -1을 뺀 것은 중간 가운데 0이 포함되기 때문)
이렇게 자바에서는 어떤 범위에 해당하는 정수에 따라 자료형을 지정하고 선언하여 특정 값을 저장하고 처리가 가능하며 기본적으로 자바에 입력되는 정수값들은 int형으로 자동 저장된다. (int형을 넘어서는 범위를 가진 정수를 써야하거나 특정 값이 int가 아닌 다른 자료형으로 저장되게끔 하고 싶다면 아래 코드처럼 이클립스에 코드를 명시적으로 쳐야한다.)
long x = 25L; //int 이외의 자료형 값을 선언하고 저장할때는 오른쪽 값뒤에 Long은 대문자 소문자 L,l을 붙여야 함.(2) 기본 자료형 - 문자형
우리가 A,B,C...할때 쓰는 각각 하나 하나의 문자가 바로 문자형이다. 문자형 자료형은 하나뿐인데 아래와 같다.
char 2¹⁶ : 2바이트
예시는 아래와 같다.
char x = 'A';그런데 여기서 의문이 들것이다, 어떻게 컴퓨터는 'A'라는 문자에 대해서 0과 1만으로 기억을 하는지에 대해. 그 답변은 아스키 코드와 유니코드가 해줄수 있다.
ASCII (American Standard Code for Information Interchange, 미국 정보 교환 표준 부호) : 미국의 산업 표준을 정하는 미국 국립 표준 협회 American National Standards Institute, ANSI에서 1963년에 표준화한 정보교환용 7비트 부호체계이다. 나머지 1비트는 에러 검출용도로 사용했다. 그래서 1바이트이며 총 합쳐서 128개의 영어문자,특수문자, 숫자로 이뤄져있다.
다만, 한글을 포함해 영어와 다른 언어를 가진 여러 다른 나라들의 자국어는 표시하기가 힘들었기에 (글자 깨짐 오류 현상 발생) ASCII코드를 고쳐야할 필요성이 생겼고 이에 맞춰 1991년 유니코드 Unicode 1.0이 공개되었다. 유니코드는 전세계 공용 문자코드표로써 범위를 플레인으로 나누어 0번 플레인까지는 1개의 char 타입 2바이트로 표현하고 1~16플레인은 2개의 char 타입을 묶어 4바이트로 표현한다고 한다.
현재 자바에서 웬만한 char 타입 값들은 unicode의 0번 플레인으로 저장되어 처리되는것이고 이는 웹에서 대표적으로 1바이트에서 4바이트까지 폭넓게 문자를 처리하는 유니코드 UTF-8형식으로 인코딩(문자가 이진수로 바뀌는 처리)되어 운용되고 있다. (자바는 UTF-16, 2바이트 고정으로 유니코드 형식으로 처리)
특이한게 이런 문자들은 모두 2진수, 8진수, 10진수, 16진수별로 구분을 할 수 있는데 자세한 표는 다음 링크에서 볼 수 있다. (https://www.rapidtables.org/ko/code/text/unicode-characters.html)
열어서 보면 예를 들어 대문자 A는 코드로 십진수 65, 소문자 a로는 97로 저장됨을 알 수 있다.
그래서 아래 코드단처럼 자바에서 대문자 A는 다양한 형태로 표현할 수 있다.
public class 클래스명 ~ {
public static void main (String [] args) {
char ch1 = 'A'; //일반 로마자 형식
char ch2 = 65; //삽잔수 형식
char ch3 = 0x41; //16진수 형식
char ch4 = 0b0000000001000001; //2진수 형식
System.out.println(ch1);
System.out.println(ch2);
System.out.println(ch3);
System.out.println(ch4);
}
}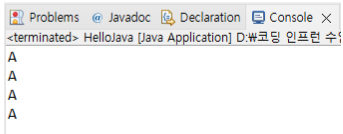
위 사진에서 보다시피 결과는 모두 다 같은 대문자 A로 표현된다.
(3) 기본 자료형 - 논리형
논리형은 어떤 조건에 대한 참, 거짓 결과값의 자료형을 말한다. (true or false)
boolean 2⁸ : 1바이트, true 아니면 false 값을 저장한다.
한번 아래 코드를 main 부분에 넣어서 실행해보자.
public static void main(String[] args)
{
boolean bol1 = true; // 직접 true 값 대입
boolean bol2 = false; // 직접 false 값 대입
boolean bol3 = (1 > 2); // 수식 조건의 결과 값으로 대입
boolean bol4 = (1 < 2);
System.out.println(bol1);
System.out.println(bol2);
System.out.println(bol3);
System.out.println(bol4);
}그러면 아래와 같이 결과값이 콘솔에 찍혀서 나온다.
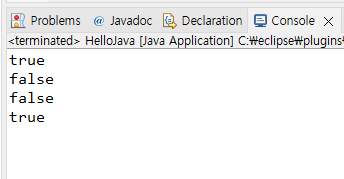
(4) 기본 자료형 - 실수형
실수(real number)는 유리수(정수 (자연수 + 0 + 음수) + 분수)와 무리수(분수로는 표현되지 않는 무한 소수)인데, 실상 코딩 이쪽에서는 정수와 소수가 같이 쓰이며 표현되는 수라고 지칭한다. 이 실수는 알다시피 0과 1사이의 무한대로 존재하는 소수를 포함하기에 범위가 굉장히 중요하다.
예를 들어, 0.2라는 수는 다르게 표현하자면 2 x 10^-1 과 같다.여기서 2는 정수 부분으로서 가수 부분이라 칭하고 10^-1 (10의 -1승)은 지수 부분이라 칭한다. 이렇게 표현하는것을 부동 소수점 표현방식이라 한다. 소수 몇자리까지만 정해놓고 표현하는 고정 소수점 방식보다 몇자리까지 표현할지 정해지지 않고 계속 움직이는 소수 표현 방식을 가진 부동식 소수점 표현 방식은 더 세밀하게 실수를 표현할수 있다.
자바 역시 이 부동 소수점 방식을 사용하며 실수의 자료형은 두 가지가 있다, 그것은 float와 double이다.
float 2³² : 4바이트, 부호 1비트 + 지수부 8비트 + 가수부 23비트 방식
double 2⁶⁴ : 8바이트, 부호 1비트 + 지수부 11비트 + 가수부 52비트 방식
보다시피 double이 표현할수 있는 실수의 범위가 float 보다 더 넓다. 자바는 실수를 값으로 저장할때 기본적으로 double로 저장한다.
(만약 float로 저장하고 싶다면 long의 경우처럼 변수에 float 자료형을 선언하는것은 물론; 해당 값 뒤에 대문자 F나 소문자 f를 써야한다. 아래 코드 참조)
float x = 3.14F; //대문자 F 혹은 소문자 f이렇게 부동 소수점 방식을 쓰는 자바 실수형은 분명 더 세밀하게 실수를 표현하긴 하지만, 가수부가 특정 비트 범위의 한계가 있기에 0과 1사이의 무한의 소수를 다 표현하지 못할뿐더러 몇몇 계산에선 치명적이지는 않지만 자잘한 오차들이 발생한다.(지수가 0이 될수는 없음) 일단 아래 코드단을 쳐보고 실행해보자.
public static void main(String[] args){
double dnum1 = 1;
for(int i = 0; i < 10000; i++){
dnum1 = dnum1 + 0.1; // 0.1을 10000번 계속 더 하라는 뜻
}
System.out.println(dnum1);
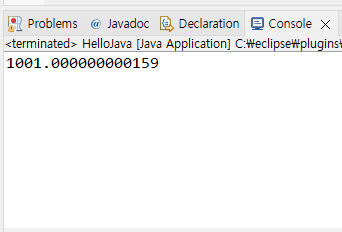
}그럼 결과가 원래는 딱 1001이 나와야 하는데 아래 사진처럼 소수점 부분으로 부정확하게 나온다.
이게 왜냐하냐면 우리가 앞서 1장 컴퓨터 부분에도 말했다시피 자바 또한 이진수로 실수 값이 저장되기 때문에 (2의 승) 이진수로 완벽하게 표현할수 없는 10의 승은 제대로 계산되지 않는다. (이건 비단 자바 뿐만이 아니라 여타 다른 프로그래밍 언어들 또한 마찬가지이다.)
+) 자료형 없이 변수 선언하기 (자바 10부터 생긴 문법)
여태까지 배워왔듯이 원래 자바는 어떤 값을 선언하고 변수에 저장할때, 자료형을 정확히 적어줘야한다. 그러나 자바 10버젼부터는 지역 변수 추론(local variable type inference)이라고 해서 자료형을 선언하지 않아도 변수를 사용할수 있다.(자동으로 맞춤 자료형으로 선언 및 저장됨) 아래 코드단을 main 부분 안에 쳐보고 실행해보자.
var num = 10;
var dnum = 3.14;
var bol = true;
var str = "안녕"; //""로 걸려있는 문자들(문자열)은 원래 자료형이 String (<= 기본 자료형X, 참조 자료형 객체 O)
System.out.println(num);
System.out.println(dnum);
System.out.println(bol);
System.out.println(str);그러면 아래 사진과 같이 결과가 나오는데, 보다시피 자료형 선언 없이 var만으로도 충분히 변수 값 저장 및 출력이 가능하다.
다만 몇가지 조건이 있는데, 한번 선언한 자료형 변수를 다른 자료형으로 선언할수 없으며 이렇게 var를 이용해 자료형 선언 없이 변수를 저장하는것은 main 부분 안에서만 가능하다.(지역 변수, main이 메소드인데 이 메소드 안에서 선언되는 변수를 뜻한다.)
그리고 다른 언어의 프로그램도 이 방식이 사용 가능하다.(자바 스크립트)
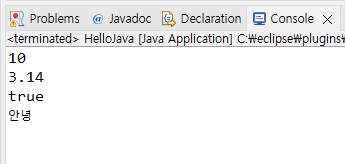
(5) 형 변환
이렇게 우리가 앞서 기본 자료형에 대해 공부해봤는데, 만약 어떤 자료형을 다른 자료형으로 바꾸고 싶다면 어떻게 해야할까? 그래서 형 변환(type conversion)이라는게 존재한다.
형 변환은 묵시적 형 변환 (자동 형 변환)과 명시적 형 변환이 있는데, 일단 기본 원칙은 아래와 같다.
바이트 크기가 작은 자료형에서 큰 자료형으로 변하는 형 변환은 자동적으로 이뤄진다.
덜 정밀한 자료형에서 더 정밀한 자료형으로 형 변환은 자동적으로 이뤄진다.
즉, 우리가 앞서 봤던 기본 자료형들을 나열하면서 묵시적 형 변환만 추리자면 아래와 같다.
정수 [byte => short,char => int => long] => 실수 [float => double]
(1바이트) => (2바이트) => (4바이트) => (8바이트)
(정수와 실수는 실수가 더 범위가 크기 때문에 정수에서 실수로 갈때 묵시적 형변환 자동 형변환이 일어난다.)
이렇게 묵시적 형 변환이 일어나기에 이 반대 방향으로 형 변환이 이뤄지는건 반대로 명시적 형변환이라고 한다. (자료형에 따라 다르지만 명시적 형 변환의 경우 넓은 범위의 값에서 좁은 범위의 값으로 변환되는거기에 값 손실이 일어날수 있다.)
한번 아래 코드단을 main 부분안에 쳐보고 실행을 해보자.
// 자동 타입 변환 (업캐스팅) 묵시적 형변환
float value1 = 3;
long value2 = 5;
double value3 = 7;
double value4;
value4 = value1 + value3;
System.out.println(value1);
System.out.println(value2);
System.out.println(value3);
System.out.println(value4);
System.out.println();
// 수동 타입 변환 (다운캐스팅) 명시적 형변환 () cast 연산자 값손실 일어날수 있음
int value5 = (int)3.5;
float value6 = (float)7.5;
System.out.println(value5);
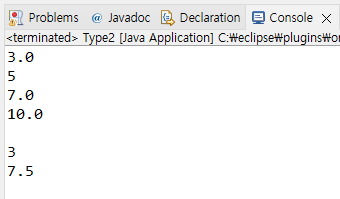
System.out.println(value6);그러면 아래 사진과 같이 오른쪽 항 값이 정수여도 float나 double인 경우 소수점 한자리까지 표현되고 있으며 value4는 서로 다른 자료형 더하기 연산을 해도 double이 유지되고 있다. 특히 value5는 원래 값이 3.5였지만 강제로 int형으로 범위가 좁은 자료형으로 변환되면서 3으로 값이 손실되었다.
2. 상수
상수(Constant Number)는 항상 변하지 않는 값으로 변수의 반대말과 같다. 자바에서는 우리가 값으로 대입하는 1,2,3,4,... 등 정수 실수를 말한다. (단지 우리가 이 '값'을 이용해서 오른쪽에서 왼쪽 항으로 어떤 변수에 대입(=)을 하는것이지 이 값은 자바 프로그램이 로딩되자마자 프로그램 상 사용할수 있게 위치해 있는 수들의 모음이다. 이를 리터럴, 상수 풀 이라고도 한다. 문자도 논리값 true false 값도 리터럴에 속한다.)
다만, 자바에서 절대 변하지 않는 값으로 선언하기 위해서는 아래와 같은 코드를 쳐야한다.
final PI = 3.14F; //final 예약어 + 상수명 (모든 글자를 영어 대문자로), 초기화 필수이러면 PI 상수는 해당 코드에서 따로 변경하지 않는 이상 절대 다른 수식에 의해 값이 변화하지 않는다.
이렇게 컴퓨터, 자바 작동의 기본 수체계인 2진수부터 변수, 그리고 변수의 자료 타입을 지정하는 기본 자료형과 마지막 상수 설정법까지 알아보았다. 다음장에서는 연산자와 본격적으로 프로그램의 본체가 되는 클래스 그리고 그 클래스의 기능이 되는 메소드를 만드는 형식을 알아보겠다.
