Course overview
- 사람의 지능은 인지능력과 지각능력 기억과 이해 및 사고능력 까지의 넓은 영역을 의미
- AI는 바로 이 사람의 지능을 컴퓨터 시스템으로 구현하는 것
-
사람은 5개의 감각을 활용해 세상과 상호작용을 하며 학습을 한다. 또한, 5개의 오감 말고도 교차값과 다중값을 통해 더 유용한 정보를 취득할 수 있다. (eg. 얼굴과 눈을 인식하는 것 뿐만 아니라 표정을 파악)
-
사실 사람도 이러한 감각들의 사용법을 명확하게 알지 못하므로 이를 컴퓨터로 구현하는 문제는 단순한 문제가 아니기 때문에 활발히 연구되고 있다.
-
따라서, 인공지능을 구현하기 위해서는 도입부인 퍼셉트론이 불완전하면 사고 능력도 불완전하기에 지각 능력의 구현이 가장 중요하다.
-
우리는 ’뇌에서 처리하는 가장 많은 정보는 시각 정보이다’ 라는 말이 있을 정도로 다른 오감에 비해 압도적으로 시각에 의존하며 살아가고 있다.
사람이 장면을 이해하는 과정
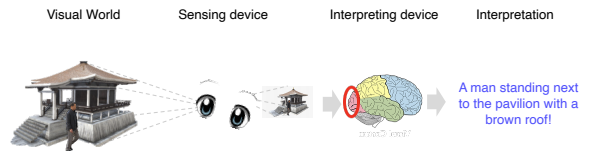
일상의 장면 관찰 → 수정체 뒤쪽에 상이 맺힘 (센싱) → 뇌에 이 자극을 전달 → 이 자극을 이해하고 해석
컴퓨터가 장면을 이해하는 과정
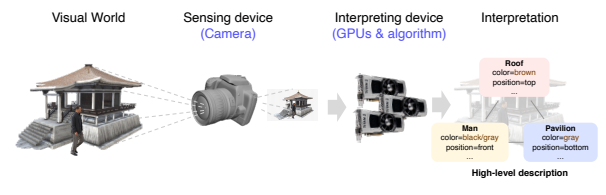
카메라를 통해 영상 혹은 이미지 생성 → 이 것을 GPU상에 올려서 연산 진행 → 장면에 대한 분석을 진행하여 인사이트 추출
What is computer vision?
- CV는 결국 영상이나 이미지같은 visual data를 입력으로 받아 Machine vision perception을 만드는 것이다.
- 사람의 어떤 생물학적인 부분을 이해를 하고 어떻게 컴퓨터로 구현을 할지 생각해야 한다.

- 위의 사진을 보면 뒤집힌 상태의 얼굴을 보면 별로 이상하다고 생각되지 않는데, 다시 돌려보면 표정이 이상한 것을 알 수 있다.
- 우리는 평소에 뒤집힌 얼굴을 볼 기회가 거의 없고 온전한 얼굴을 많이 봐오면서 학습을 하였기 때문에, 우리의 시각 기능이 bias되어 학습되어 있다는 것을 알 수 있다.
- 이와 같이 인간의 시각적인 기능에서 불완전하지 못한 부분이 많이 존재하기 때문에, 사람의 구조를 모방하는 CV를 구현하기 위해서는 어떻게 하면 이러한 부분을 보완할 수 있을지 생각해볼 필요가 있다.
Image classification
-
Classifier란?
- 어떤 물체가 영상 속에 들어있는지를 분류하는 mapping
-
K-NN(K nearest Neighbors)
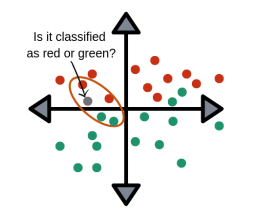
- 가장 이상적인 Classifier를 생각해보자.
- 모든 데이터를 가지고 있다면 입력이 들어왔을 때 쉽게 분류할 수 있을 것이고, 이는 K-NN으로 구현할 수 있을 것이다.
- 한 query데이터가 들어오면 다른 데이터들과의 유사도를 측정해 query데이터와 유사한 k개의 데이터를 찾고 이 데이터들의 라벨 정보를 기반으로 분류를 할 수 있다.
-
하지만, 모든 데이터를 컴퓨터에 담기에는 용량도 부족하고 검색하는데 시간이 오래 걸리는 한계가 있다.
CNN
-
single Fully connectied layer
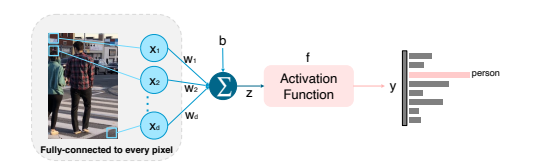
-
모든 픽셀들을 서로 다른 가중치로 내적하여 nonlinear activation function을 통해 분류 스코어로 출력하는 간단한 모델
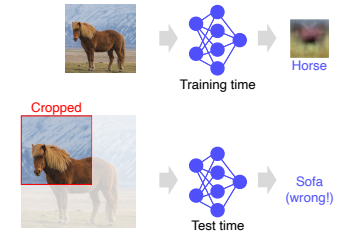
-
-
이는 평균적인 이미지에 대해서만 학습을 하여 표현하였는데, 조금이라도 영상의 위치나 스케일이 달라지게 된다면 다른 결과와 해석을 나타내는 문제가 있다.
-
Locally connected neural network
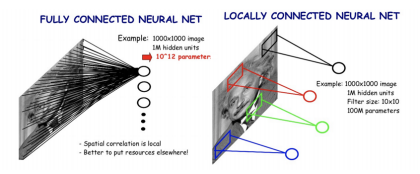
- 하나의 특징을 뽑기 위해서 국부적인 영역들만 sliding window를 통해 connection을 고려한 layer를 locally connected neural network라 한다.
- 이는 fc layer보다 파라미터 수가 훨씬 적으며, 영상의 위치나 스케일이 달라지게 되어도 민감하지 않게 특징을 잘 추출 해낼 수 있다.
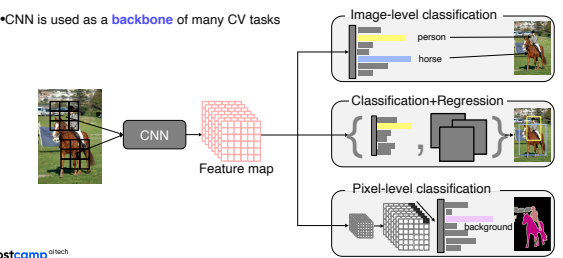
- backbone network 위에 target task의 head를 적합하게 디자인해서 사용하는 형태가 기본적인 CV 알고리즘의 디자인 패턴이다.
CNN의 발전 흐름
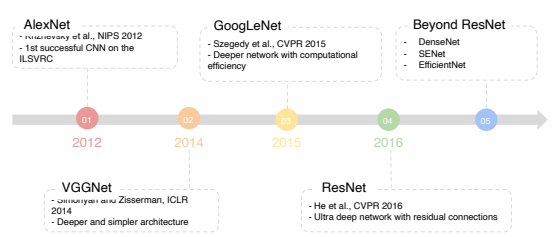
AlexNet
https://velog.io/@ysw2946/AlexNet
VggNet
