보통 수업/학교/연구에서는 정해진 데이터셋/평가 방식에서 더 좋은 모델을 찾는 일을 한다.
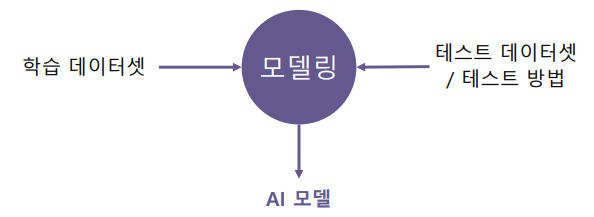
- 정해진 데이터셋에서 모델 구조 또는 학습 방법을 바꿔가면서 성능이 최대가 되는 모델을 찾아가는 방법
하지만, 서비스 개발 시에는 데이터셋이 준비되어 있지 않고, 오로지 요구사항만 존재한다.
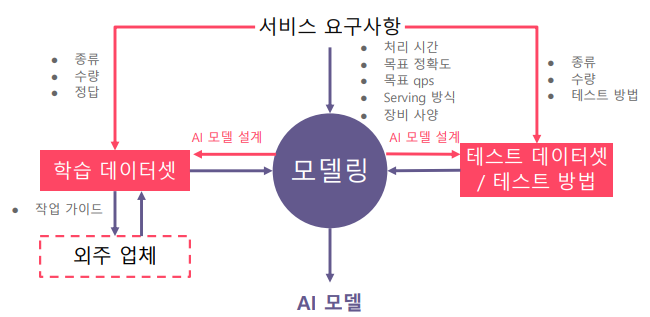
- 데이터 셋이 준비되어 있지 않거나 있더라도 불완전한 경우가 많다. → 개발 업무의 반 이상이 데이터 셋을 준비하는 작업과 관련되어 있다.
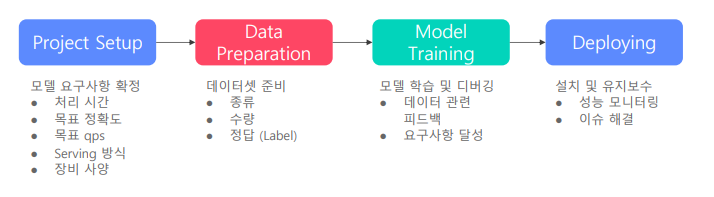
서비스향 AI 모델 개발 과정
-
Project Setup
- 프로젝트 진행에 앞서 목표치, 장비, 진행 방식 등을 미리 정하는 과정
-
Data preparation
- 보통은 supervised learning 으로 학습이 되기 때문에 labeling이 필요
- 준비된 데이터 셋을 바로 모델에 적용할 수 있게끔 준비하는 과정
-
Model Training
- 모델 학습 이후 한번에 성능이 원하는 만큼 나오지 않기에 디버깅하는 과정이 필요.
- 디버깅 과정에서 결국엔 데이터를 들여다볼 수 밖에 없기 때문에 데이터 관련 피드백을 진행
-
Deploying
- 실제로 서비스에 적용하여 살펴보면 처음 기대했던 성능과의 차이가 있기에 지속적으로 모니터링하고 이슈를 해결
-
이 과정의 목표는 요구 사항을 충족시키는 모델을 지속적으로 확보하는 것이며, 두 가지 방법이 있다.
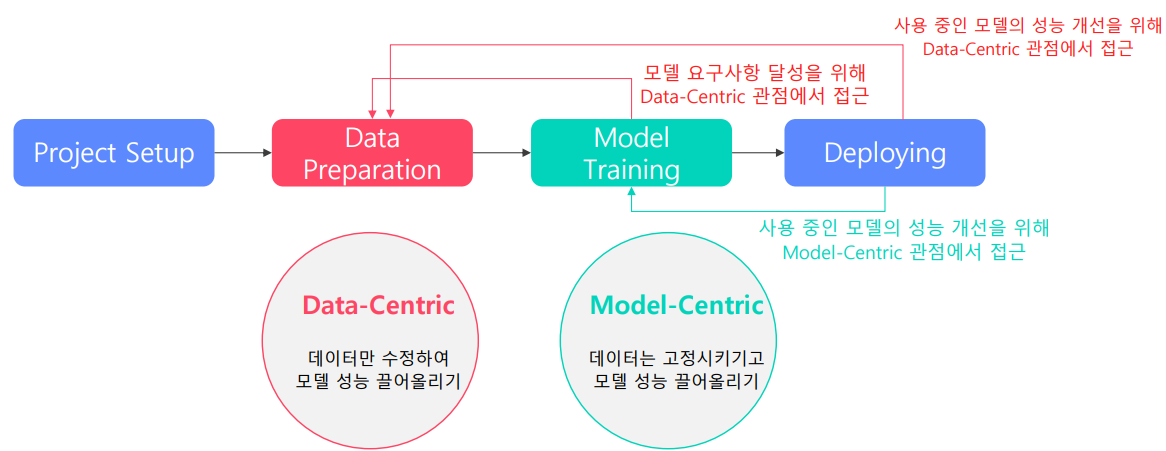
- Data-Centric
- 모델은 고정시키고 데이터만 수정하여 성능 올리기
- Model-Centric
- 데이터는 고정시키고 모델을 수정하여 성능 올리기
- 모델 성능 달성에 있어서 데이터와 모델에 대한 비중
- 서비스 배포 전
- 목표 정확도, qps 등이 모델 구조에 의해 정해지기 때문에 모델도 어느 정도 건드려야함.
- 데이터 : 모델 = 50 : 50
- 서비스 배포 후
- 서비스 출시 후에는 정확도에 대한 성능 개선 요구가 가장 많다.
- 이때 정확도 개선을 위해 모델 구조를 변경하는 것은 처리 속도, qps, 메모리 크기 등에 대한 요구사항에 검증도 다시 해야 하므로 비용이 크다.
- 데이터 : 모델 = 80 : 20
- 서비스 배포 전
예상보다 데이터 관련 업무가 왜 이렇게 많을까?
-
어떻게 하면 좋을지에 대해서 알려져 있지 않다.
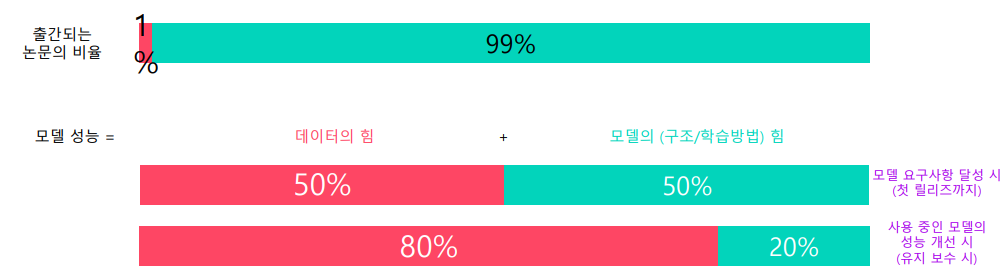
- 출간되는 논문의 비율 중 99%가 모델에 대한 내용이며, 데이터에 대한 내용은 단 1%.
- 학계에서는 데이터를 다루기 힘든 이유
- 좋은 데이터를 많이 모으기 힘들다
- 라벨링 비용이 크다
- 작업 기간이 오래 걸린다
-
데이터 라벨링 작업이 생각보다 많이 많이 어렵다.
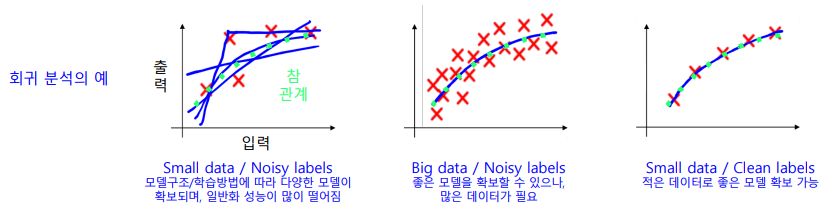
- 라벨링 노이즈 : 라벨링 작업에 대해 일관되지 않음의 정도
- 잘못된 라벨링 결과를 학습 시 무시하게 하려면 전체 라벨링 데이터가 라벨링 노이즈를 상쇄할 정도로 깨끗한 라벨링 데이터으로 이루어져 있어야 한다..
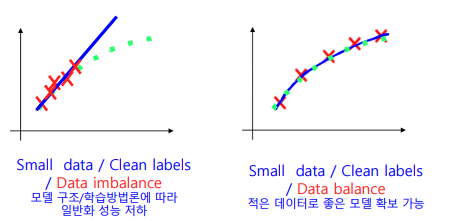
- 뿐만 아니라 적은 데이터도 골고루 있어야지 너무 유사한 데이터만 있으면 안된다.
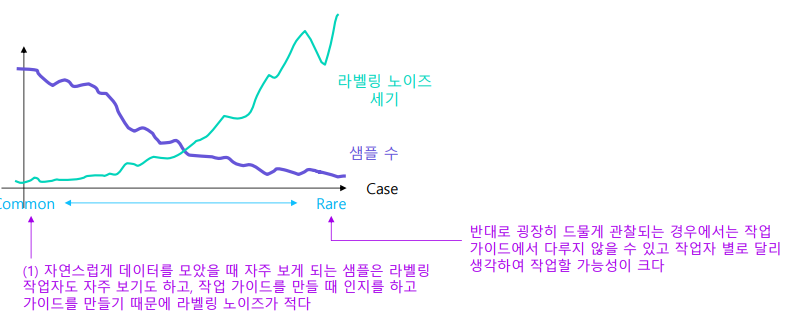
- 라벨링 노이즈를 데이터 분포와 연관지어서 생각해볼 수도 있다.
- 예를 들어, 강아지의 사진을 수집할 때 흔히 볼 수 있는 강아지의 경우는 라벨링을 하는 사람이나 요청한 사람이나 모두 쉽게 알아볼 수 있으므로 노이즈가 적다.
- 하지만, 희귀한 종의 강아지의 경우에는 작업하는 사람과 요청한 사람 모두 알아보기 어려우므로 노이즈가 크다.
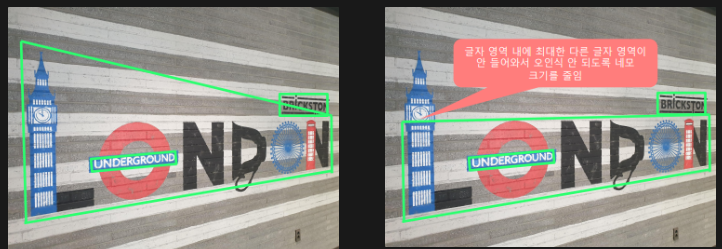
OCR 예시
- 글자 영역을 검출하는데, 단어 단위로 검출하려 할 때의 라벨링
- 아래 사진의 경우 대부분의 사람들이 일관되게 박스를 설정할 수 있다.

- 하지만 다음의 경우 잘못 적은 글자 혹은 특수문자에 대해 작업하는 사람에 따라 라벨링이 달라질 수 있다.

- 그 외에도 아래 사진들과 같이 구분하기 어려운 경우들이 존재한다.


-
데이터 불균형을 바로 잡기가 어렵다.
-
데이터를 골고루, 일정하게 라벨링된 데이터가 많아야 한다.
-
즉, 특이한 경우를 의도적으로 많이 모아줘야 하고, 라벨링 노이즈를 제거하기 위해 라벨링 가이드가 특이한 경우들을 잘 라벨링 할 수 있도록 잘 나타나 있어야 한다.
-
이 작업을 효율화 하기 위한 방법
-
해당 태스크에 대한 경험치가 잘 쌓여야 한다.
- 결국 도메인 지식이 많을 수록 예외 경우에 대해서 미리 인지를 할 수 있다.
-
하지만 완벽하게 모든 경우의 수를 알고 데이터를 모으고 라벨링 가이드를 만드는 것은 불가능한 것을 인지하고 이를 반복적으로 자동화된 작업으로 만들어가야 한다.
-
Data Engine / Flywheel
-
결국 데이터 라벨링은 반복적인 작업을 통해 최대한 깨끗한 데이터 셋을 만들어야 한다.
-
이 때, 한번의 cycle을 Data Engine/Flywheel 이라 한다.
-
Software 1.0 vs Software 2.0
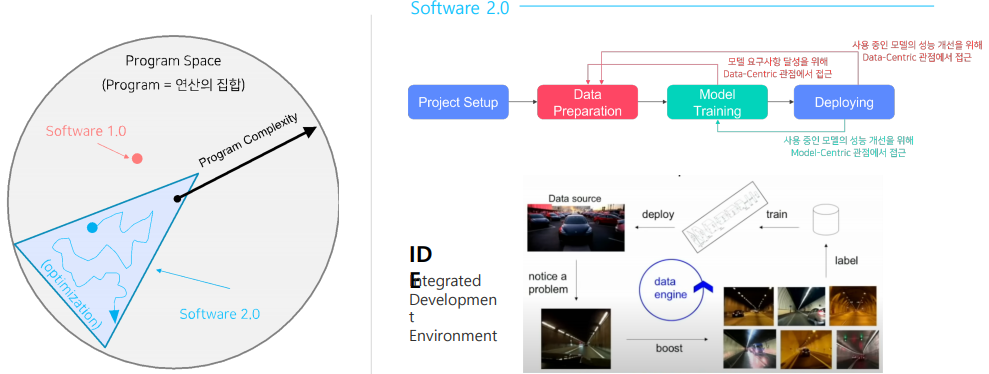
-
전체 AI 모델의 성능을 확보하기 위해서는 반복적인 작업을 효율적으로 하는 툴인 IDE를 잘 만들어야 한다.
-
software 1.0은 아래와 같이 나와 있지 않지만 software 2.0 IDE는 아직 나타나 있지 않다.
-
하지만, Software 2.0 IDE가 갖춰야 할 기능들에 대해서는 생각해볼 수 있다.
-
데이터 시각화
- 데이터/레이블 분포 시각화
- 레이블 시각화
- 데이터 별 예측값 시각화

- 데이터를 다각도로 시각화하여 어떤 데이터를 추가로 수집/예외처리 할지를 제공해야 한다.
-
데이터 라벨링
-
라벨링 UI
-
태스크 특화 기능
-
라벨링 일관성 확인
-
라벨링 작업 효율 확인
-
자동 라벨링
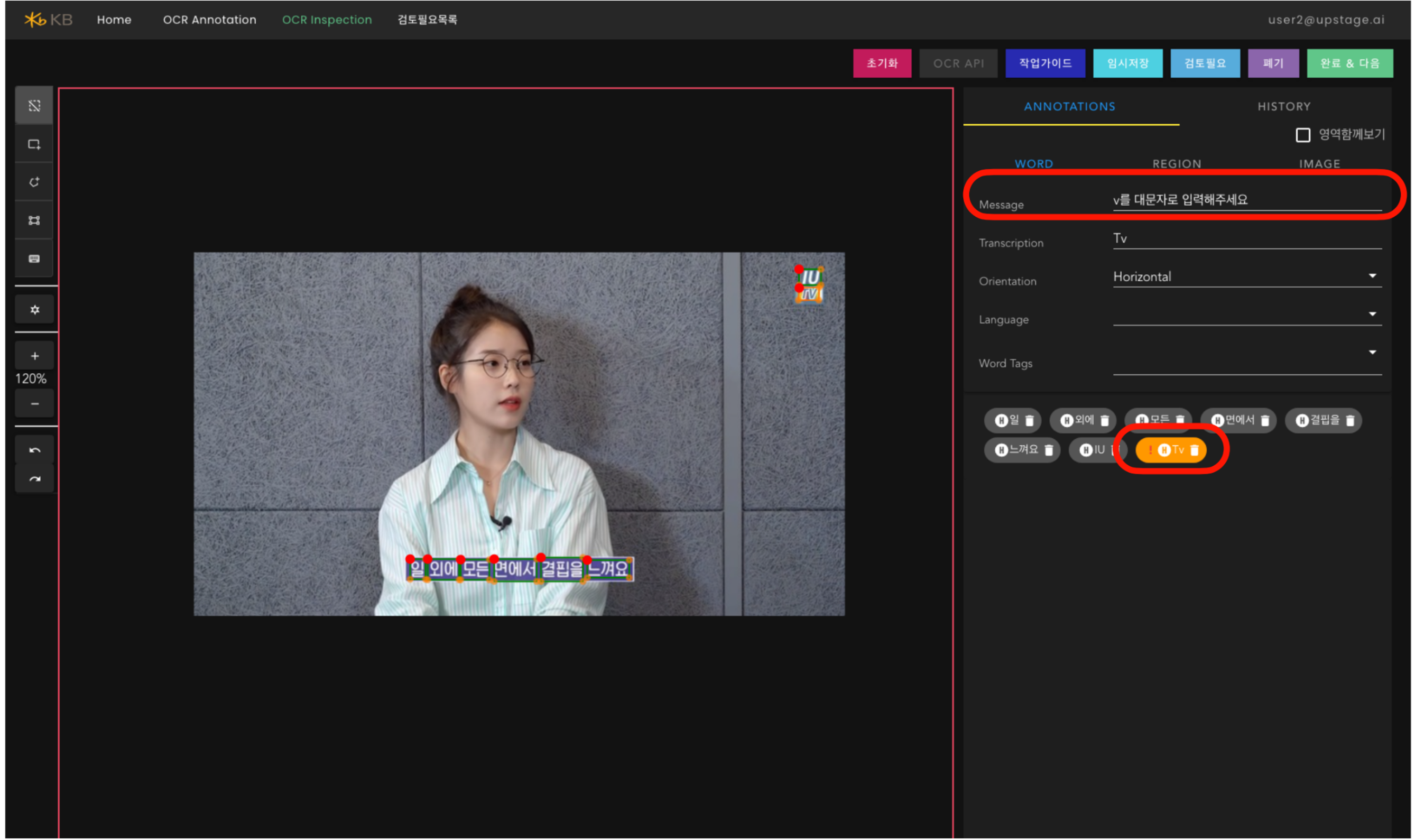
- 특이한 경우를 다루기 위해 라벨링 가이드를 업데이트 해 나가야 하고, 이를 효율적으로 개선해 나가야 할 기능들이 필요하다.
-
-
데이터셋 정제
- 반복되는 데이터 제거
- 라벨링 오류 수정
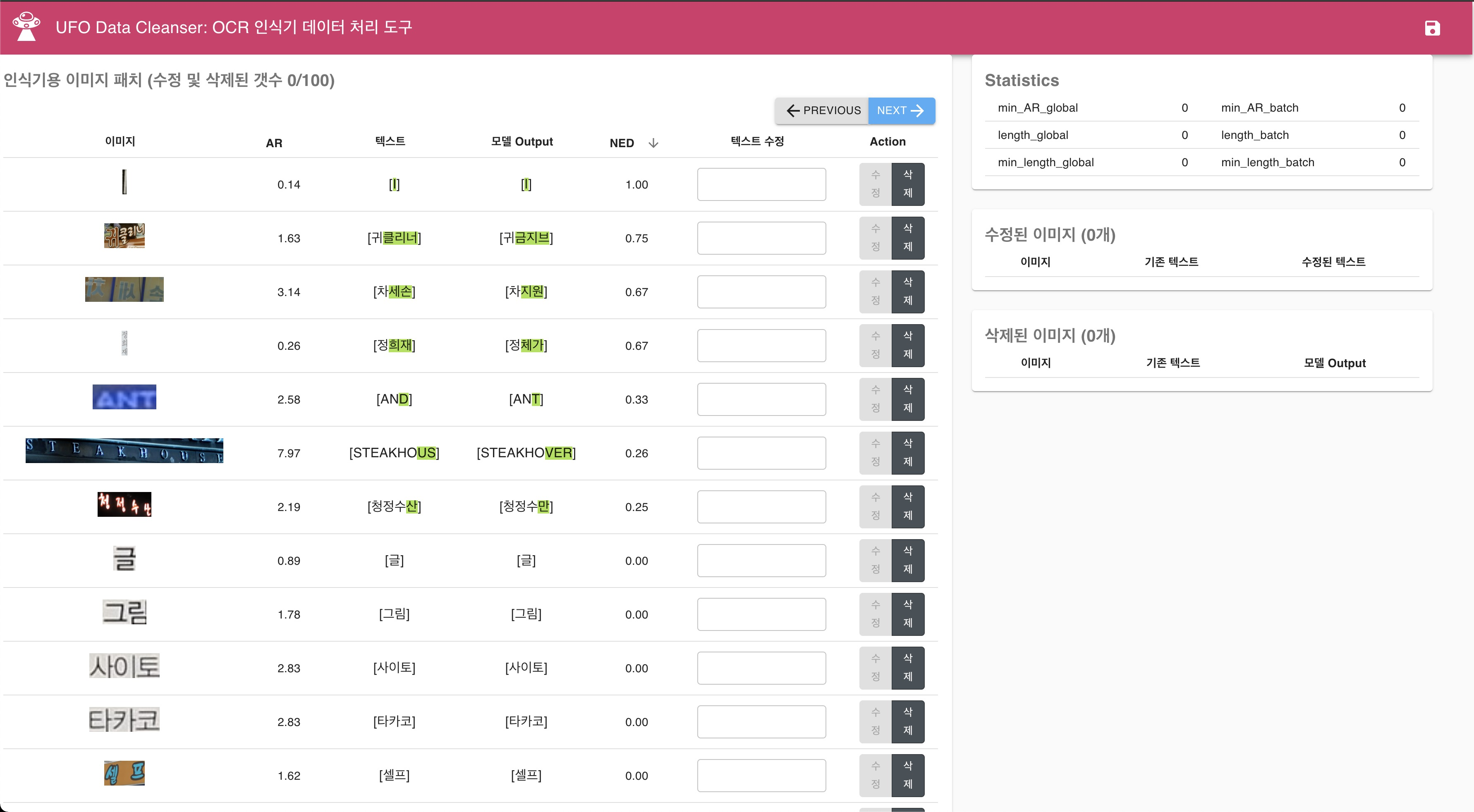
- 데이터셋 선별
- 어떤 데이터를 모델 성능 향상을 위해서 라벨링해야 하나?
- 어떤 데이터를 모델 성능 향상을 위해서 라벨링해야 하나?
